semester 2 - modul statistik sosial
DESCRIPTION
12345TRANSCRIPT

MODUL
PENDAHULUAN
Tujuan Pembelajaran
Setelah mempelajari modul ini diharapkan:
Mahasiswa mampu menjelaskan apakah yang dimaksud dengan statistik
Mahasiswa mampu menjelaskan apakah yang dimaksud dengan statistik
Mahasiswa mampu menjelaskan jenis data statistik
Mahasiswa mampu menjelaskan kegunaan statistic
Mahasiswa mam menjelaskan macam-macam sampling
Statistika dipelajari oleh berbagai ilmu terutama digunakan untuk penelitian . kita
mengenal dua istilah statistik dan statistika, berikut perbedaan statistik dengan statistika
diagram
Statistik tabel/daftar
rata-rata
statistika Cara atau metode dalam pengolahan Data
Dalam statistik yang memiliki peran utama adalah data.
Data terbagi menjadi 2 yaitu :
1. Kualitatif : dilihat berdasarkan kualitasnya ( baik, cantik, pintar, dll )
2. Kuantitatif : dilihat berdasarkan kuantitasnya ( ukuran ).
Data dalam statistik biasanya selalu dibentuk dalam data kuantitatif, untuk
mengkuantitatifkan data tersebut maka dikenal adanya skala dalam statistik adapun skala
tersebut adalah:
1. skala nominal (skala dimana angka hanya menggambarkan atribut saja)
2.skala ordinal (skala dimana angka hanya menggambarkan tingkatan saja)
3. skala interval (skala dimana angka merupakan angka sebenarnya)
4. skala ratio (skala dimana angka merupakan angka sebenarnya dan memiliki nol mutlak)
Berdasarkan dari mana asalnya data kuantitatif terbagi menjadi 2 macam :
Hasil mengukur = Data kontinu adalah hasil dari mengukur sesuatu dengan standar , contoh
: tinggi badan, berat badan.

Hasil membilang = Data diskrit, contoh : 5 benua, 7 orang, jumlah penduduk.
Statistika secara garis besar dapat dibagi menjadi dua macam :
1. statistika deskriftif
yaitu statistika digunakan untuk melihat gambaran data secara umum, baik itu
penyajian data, ukuran gejala pusat dan ukuran simpangan
2. statistika inferensia
yaitu statistika yang digunakan untuk menganalisis data atu menguji suatu
hipotesis, statistika inferensia dibagi menjadi dua bagian yaitu statistika
parametris dan statistika non parametris.
Data diambil dari suatu populasi, yaitu kumpulan objek yang memiliki karakteristik
yang akan diteliti.
Populasi cakupannya luas
Dalam menarik suatu sampel harus representatif → mewakili suatu populasi
Data terdapat dua macam, yaitu:
Data homogen : tingkat kedisiplinan mahasiswa FISIP UNSRI.
Data heterogen : tingkat pendidikan karyawan pada suatu organisasi.
Teknik Sampling
a. Probability Sampling
- Simple Random Sampling→ data harus homogen, pengambilan sampel secara acak.
- Proportionate Stratified Random Sampling → data heterogen
Sebagai contoh : Latar belakang pendidikan di suatu organisasi
Tamat SD → 5 orang sampel 30% dari populasi harus benar-benar
SMP → 30 orang mewakili ke 4 strata. 120 orang dengan sampel
SMA → 60 orang 30% = 36 orang. Jadi perlu diproporsikan kembali
S1 → 25 orang SD→ 2, SMP→ 9, SMA→ 18, S1→ 7 =36 orang.

Langkah:
Strata → Homogen → Random
- Disproportionate Stratified Random Sampling → sama dengan cara ke-2 tetapi
untuk data yang tidak proporsional
Sebagai contoh: SD → 100
SMP → 150 disesuaikan dengan persentase
SMA → 300
S1 → 2 dijadikan langsung sebagai sampel, tidak perlu
S2 → 1 diacak
- Area (Cluster) Sampling → untuk populasi yang cakupannya sangat luas
Sebagai contoh: pola hidup sehat masyarakat Indonesia
Rumpun pertama boleh diambil secara acak
Ke-2 = acak
Ke-3 = acak
b. Non Probability Sampling
- Sampling Sistematis → teknik penarikan sampling berdasarkan suatu sistem.
Sebagai contoh: populasi 100 orang/benda, setiap anggota diberi nomor urut dari 1
sampai dengan 100
Yang akan dijadikan sampel bisa hanya pada bilangan ganjil/genap, bilangan
berjumlah 10, dan lain-lain.
- Sampling Kuota → sampel dikelompokkan berdasarkan kuota, setelah itu baru
diambil sebagai sampel. (hampir serupa dengan strata)
- Sampling Aksidental → sampel yang diambil secara kebetulan.
Misalnya: - meneliti muatan truk yang melebihi kapasitas
- orang-orang yang berperilaku berpakaian aneh

- Purposive Sampling → teknik penarikan sampel dengan pertimbangan/tujuan
tertentu.
Misalnya: penyimpangan perilaku wanita penyuka sesama (homo/lesbi).
- Sampling Jenuh → sampel yang semua anggota populasi dijadikan sampel.
Digunakan pada populasi yang kecil
- Snowball Sampling → teknik penarikan sampel yang jarang digunakan.
Misalnya: ingin meneliti 3 orang sebagai sampel.
3 orang diambil sebagai sampel, dari 3 orang ini menunjuk 3 orang lagi
masing-masing. 3 orang pertama tidak menjadi sampel, hasil tunjukkan
ke-3 orang tadi yang dijadikan sampel.
Ukuran Sampel
Data homogen: - Random
- Dapat diambil sampel kecil
- ≤ 10%
Data heterogen: - sesuai dengan jenis sampling
- minimal 10% - 30% → valid
Catatan: purposive, populasinya tidak banyak.
Tes formatif
Kerjakanlah soal-soal di bawah ini dengan baik dan benar!
1. apa yang dimaksud dengan statistika
2. apa yang dimaksud dengan statistik
3. sebutkan macam – macam data
4. jelaskan perbedaan data kualitatif dengan data kuantitatif
5. sebutkan macam-macam skala pengukuran
6. buatlah contoh data yang merupakan skala nominal
7. buatlah contoh data yang merupakan skala ordinal

8. buatlah contoh skala interval dan ratio
9. buatlah hubungan masing-masing skala dengan statistik inferensia
10. buatlah contoh masing-masing sampling
DAFTAR PUSTAKA
Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta

MODUL PEMBELAJARAN
PENYAJIAN DATA
Tujuan pembelajaran
Setelah mempelajari modul ini diharapkan:
Mahasiswa mampu menyajikan data dalam bentuk tabel atau daftar
Mahasiswa mampu menyajikan data dalam bentuk diagram
1. Pendahuluan
Data yang telah dikumpulkan baik berasal dari populasi ataupun dari sampel, untuk
keperluan laporan atau analisis selanjutnya perlu diatur, disusun dan disajikan dalam bentuk
yang jelas dan baik. Penyajian yang baik akan memudahkan pengguna data dalam
memahami data sehingga pesan yang disampaikan dalam penyajian data tersebut dapat
ditangkap dengan benar.
Terdapat 2 cara penyajian data yang sering dipakai yakni :
1) tabel atau daftar
2) grafik atau diagram.
2. Beberapa Contoh Daftar Statistik
Secara garis besar bagian-bagian sebuah tabel yakni:

Judul daftar
Judul daftar ditulis ditengah bagian teratas, dalam beberapa baris, dengan huruf
besar. Ditulis singkat dan jelas meliputi: apa, klasifikasi, dimana, bila dan satuan atau data
yang digunakan.
Judul kolom & judul baris ditulis singkat & jelas. Usahakan jangan melakukan
pemutusan kata. Sel daftar ialah tempat nilai data dituliskan dibagian catatan biasanya
dituliskan dimana data itu dikutip.
Penulisan nama-nama sebaiknya disusun menurut abjad. Waktu disusun secara
berurutan. Kategori dicatat menurut kebiasaan misalnya laki-laki dulu baru perempuan.
2.1 DAFTAR BARIS KOLOM
Tabel I
Pembelian Barang Oleh Jawatan A
Dalam Ribuan Unit & Jutaan Rupiah
2005-2007
Badan Daftar
Judul Baris
JudulKolom
Catatan

Barang2005 12006 2007
Banyak Harga Banyak Harga Banyak Harga
A 8,3 234.4 12,7 307,8 11 290.4
B 10,8 81,4 9,4 80,5 13,0 92,0
Jumlah 19,1 315,8 22,1 388,3 24,0 382,4
Catatan: Data karangan
2.2 DAFTAR KONTINGENSI
Daftar I
Banyak Murid Sekolah Di Daerah A
Menurut Tingkat Sekolah & Jenis Kelamin
Tahun 2007
Jenis
kelaminSD SLTP SLTA JUMLAH
Laki-laki
9.0124.758 2.795 1.459
Perempuan 4.032 2.116 1.256
7.404
Jumlah 8.790 4.911 2.715 16.416
Catatan : Data Karangan
2.3 DAFTAR DISTRIBUSI FREKUENSI
Daftar IUmur Mahasiswa Univ. X
Dalam Tahun(Akhir Tahun 2007)
UMUR f
17-20 1.172
21-24 2.758
25-28 2.976
29-32 997

1562
1019
432
818 743
0
200
400
600
800
1000
1200
1400
1600
1800
SD SMP ST SMA SMEA
Tingkat
BanyakMurid
33-36 205
Jumlah 8.108
Catatan : Data Karangan
3. DIAGRAM BATANG
Data yang variabelnya berbentuk kategori atau atribut sangat tepat disajikan dalam
diagram batang.
Daftar IvBanyak Murid Didaerah A
Menurut Tingkat Sekolah & Jenis KelaminTahun 2007
TINGKAT BANYAK MURIDJUMLAH
SEKOLAH LAKI-LAKI PEREMPUAN
SD 875 687 1.562
SMP 512 507 1.019
ST 347 85 432
SMA 476 342 818
SMEA 316 427 743
JUMLAH 2.526 2.048 4.574
3.1 DIAGRAM BATANG TUNGGAL
A. SECARA VERTIKAL
DiagramBanyak Murid Didaerah A
Menurut Tingkat Sekolah & Jenis KelaminTahun 2007

1562
1019
432
818
743
0 500 1000 1500 2000
SD
SMP
ST
SMA
SMEATingkat
Banyak murid
0
100
200
300
400
500
600
700
800
900BanyakMurid
SD SMP ST SMA SMEA
Sekolah
BANYAK MURID LAKI-LAKI
BANYAK MURIDPEREMPUAN
B. SECARA HORIZONTAL
3.2 DIAGRAM BATANG 2 KOMPONEN
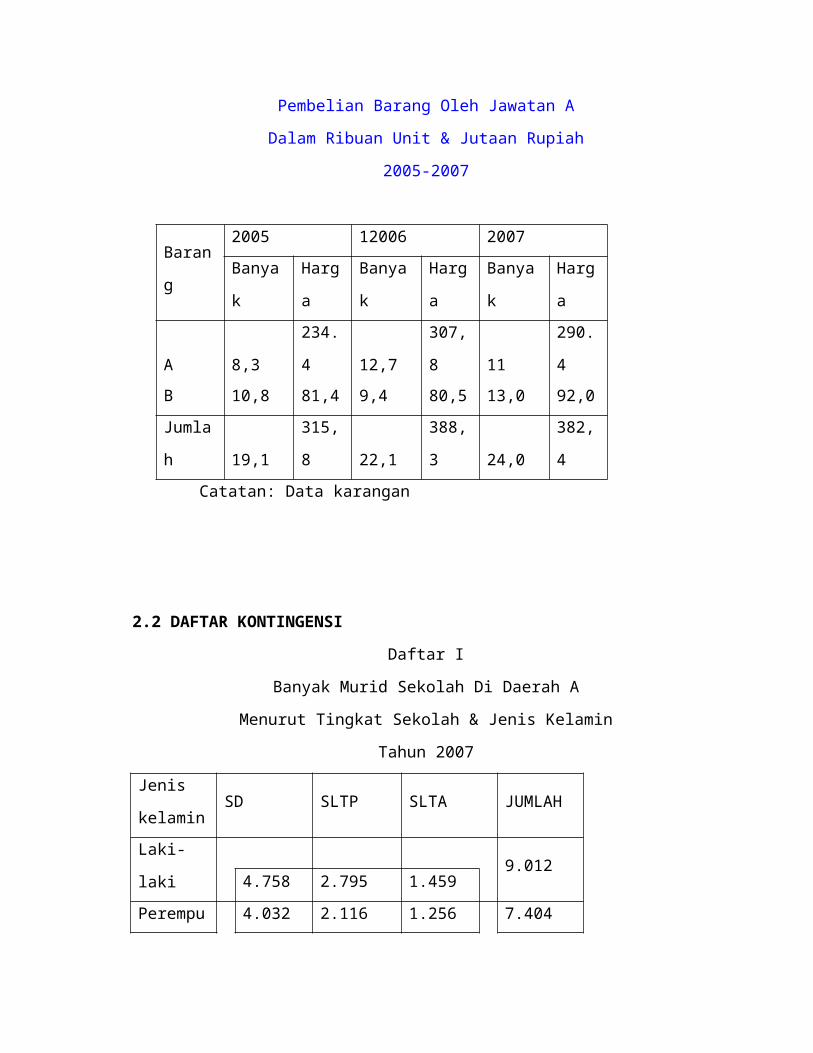
875512 347 476 316
1562
1019
432
818743
0
500
1000
1500
2000
2500
3000
SD SMP ST SMA SMEA
Tingkat
Ban
yak
Mur
id
laki-laki
perempuan
3.3 DIAGRAM BATANG CAMPURAN 2 KOMPONEN
Selain dari contoh diagram batang yang ada diatas masih terdapat diagarm batang
dua arah baik secara horizontal maupun vertical serta diagram batang 3 komponen.
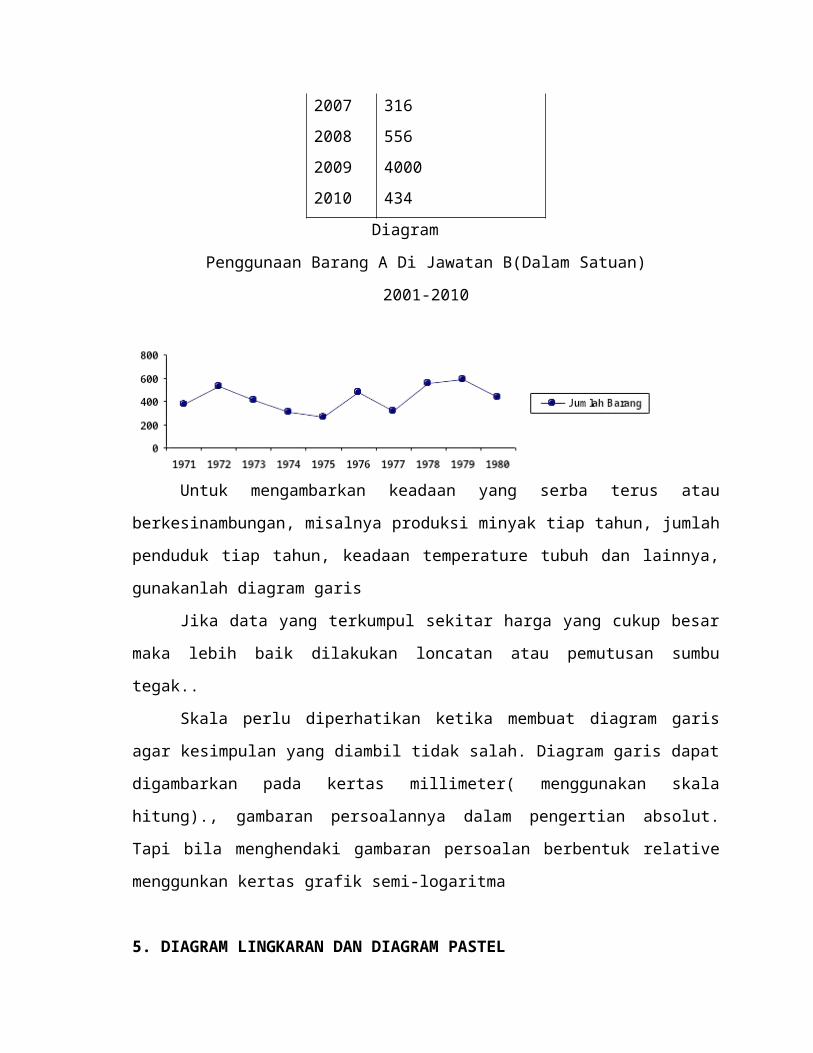
4. DIAGRAM GARIS
Contoh 2
Daftar V
Penggunaan Barang A Di Jawatan B(Dalam Satuan)
2001-2010
TAHUN Barang yang digunakan
2001 376
2002 524
2003 412
2004 310
2005 268
2006 476
2007 316
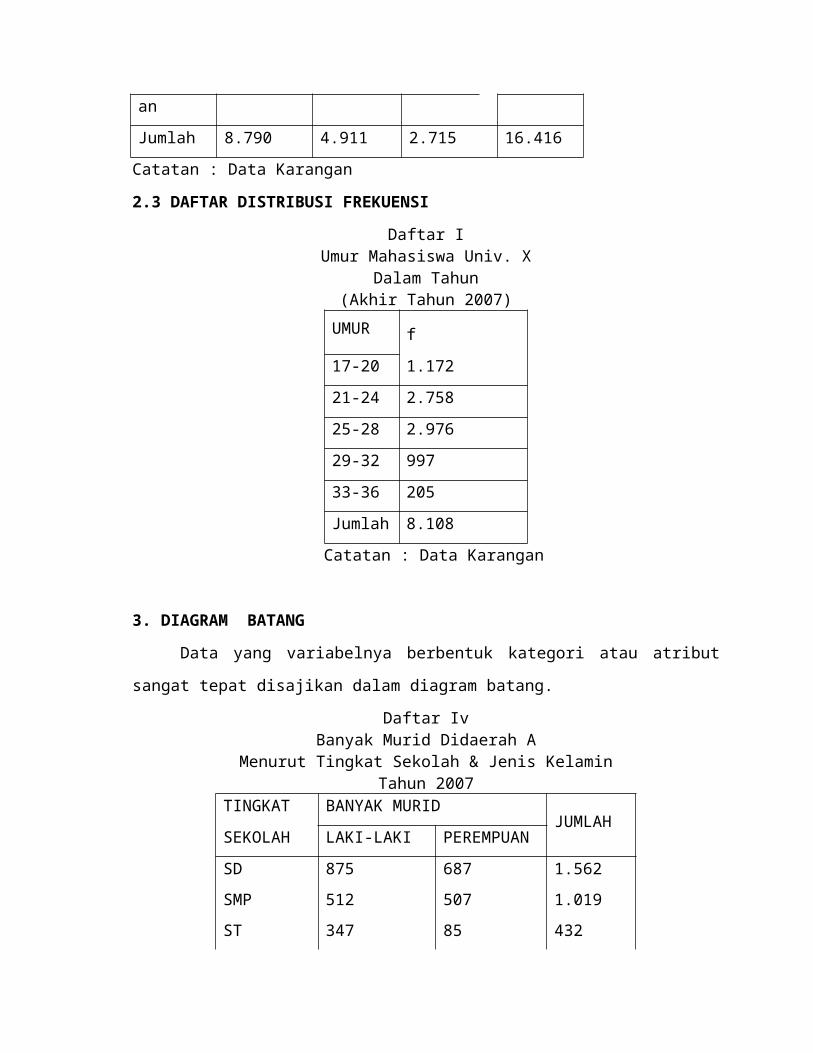
2008 556
2009 4000
2010 434
Diagram
Penggunaan Barang A Di Jawatan B(Dalam Satuan)
2001-2010
Untuk mengambarkan keadaan yang serba terus atau berkesinambungan, misalnya
produksi minyak tiap tahun, jumlah penduduk tiap tahun, keadaan temperature tubuh dan
lainnya, gunakanlah diagram garis
Jika data yang terkumpul sekitar harga yang cukup besar maka lebih baik dilakukan
loncatan atau pemutusan sumbu tegak..
Skala perlu diperhatikan ketika membuat diagram garis agar kesimpulan yang
diambil tidak salah. Diagram garis dapat digambarkan pada kertas
millimeter( menggunakan skala hitung)., gambaran persoalannya dalam pengertian absolut.
Tapi bila menghendaki gambaran persoalan berbentuk relative menggunkan kertas grafik
semi-logaritma
5. DIAGRAM LINGKARAN DAN DIAGRAM PASTEL
5.1 DIAGRAM LINGKARAN
Daftar Vi
Biaya Tiap Bulan
Di Daerah A (Dalam %)
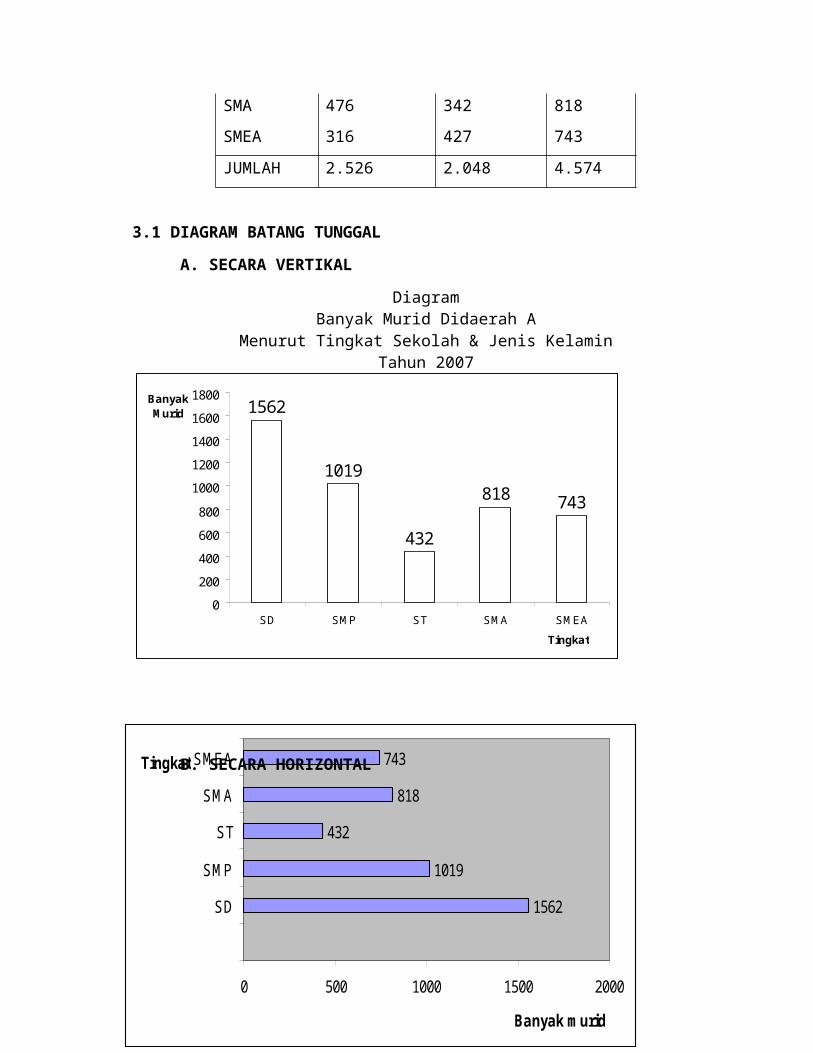
Pos A28%
Pos B18%Pos C
14%
Pos D22%
Pos E10%
Pos F8% Pos A
Pos B
Pos C
Pos D
Pos E
Pos F
Pos A28%
Pos B18%
Pos C14%
Pos D22%
Pos E10%
Pos F8%
Pos A
Pos B
Pos C
Pos D
Pos E
Pos F
Pos A misalnya menjadi
Pos B misalnya menjadi
Pos C misalnya menjadi
Pos D misalnya menjadi
5.2 DIAGRAM PASTEL
KEPERLUAN
BIAYA
UNTUK (%)
Pos A 28
Pos B 18
Pos C 14
Pos D 22
Pos E 10
Pos F 8
Jumlah 100
6. DIAGRAM LAMBANG
Contoh : diagram simbul yang dapat digunakan untuk melukiskan jumlah pegawai
diberbagai jawatan.
JAWATANJUMLAH
PEGAWAI
A
B
C
D
E
140
100
120
80
85
7. DIAGRAM PETA
Disebut juga kartogram. Dalam pembuatannya digunakanlah peta geografis tempat
data terjadi. Sehingga terlukislah suatu keadaan yang dihubungkan dengan tempat
kejadiaanya. Salah 1 contohnya buku peta bumi yang melukiskan luas suatu pulau yang
ditunjukkan oleh gambar dibawah ini.

8. DIAGRAM PENCAR
Daftar VPenggunaan Barang A Di Jawatan B
(Dalam Satuan)1971-1980
TAHUN
Barang yang
digunakan
1971 376
1972 524
1973 412
1974 310
1975 268
1976 476
1977 316
1978 556
1979 585
1980 434
Tes formatif
Kerjakan soal di bawah ini setelah saudara mempelajari modul di atas
1. mengapa data harus disajikan dengan tepat dan benar
2. sebutkan macam-macam penyajian data
3. buatlah contoh penyajian data menggunakan tabel
4. apa beda tabel biasa dengan tabel kontingensi
5. tabel distribusi frekuensi biasanya disusun untuk data seperti apa, dan buatlah contohnya
6.tentukan penyajian data yang paling tepat untuk data yang bersifat kontinu, serta berikan
contoh
7. diagram batang ganda biasanya digunakan untuk menggambarkan data yang bagaimana ,
berikan contoh
8.diagram pencar biasanya digunakan untuk menggambarkan data yang bagaimana ,
berikan contoh
9. apa perbedaan antara diagram garis dengan diagram pencar
10. buatlah contoh penyajian data menggunakan digram lambang
DAFTAR PUSTAKA
Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta

MODUL PEMBELAJARAN
DAFTAR DISTRIBUSI FREKUENSI DAN GRAFIKNYA
Tujuan Pembelajaran
Mahasiswa mampu menyususn data dalam bentuk daftar distribusi frekuensi
Mahasiswa mampu membuat daftar distribusi relative
Mahasiswa mampu menyusun daftar distribusi frekuensi kumulatif
Mahasiswa mampu memmbuat histogram
Mahasiswa mampu menyusus polygon frekuensi
1. Membuat Daftar Distribusi Frekuensi
Perhatikan nilai ujian statistika untuk 80 orang mahasiswa berikut ini :
79 49 48 74 81 98 37 80
80 84 90 70 91 93 82 78
70 71 92 38 56 81 74 73
68 72 85 51 65 93 83 86
90 35 83 73 74 43 86 88
92 93 76 71 90 72 67 75
80 91 61 72 97 91 88 81
70 74 99 95 80 59 71 77
63 60 83 82 60 67 89 63
76 63 88 70 66 88 79 75

Untuk membuat daftar distribusi frekuensi dengan panjang kelas yang sama, kita
lakukan sebagai berikut.
a. Menentukan rentang (datum terbesar – datum terkecil)
rentang = 99 – 35 = 64
b. Menentukan banyak kelas ( gunakan aturan sturges)
Banyak kelas = 1 + (3,3) log n
Banyak kelas = 1 + (3,3) log 80
= 1 + (3,3)(1,9031)
= 1 + 6,2802
= 7,2802 (dibulatkan ke bawah)
= 7
c. Menentukan panjang interval k (p), yaitu
P =
=
= 9,14 (dibulatkan ke atas)
= 10
Dengan interval (p) = 10 dan memulai dengan data yang lebih kecil atau data yang
tidak terdapat dalam data yang tersedia, misalanya diambil nilai 30, maka kelas pertama
terbentuk 30 – 39, kelas kedua terbentuk 40 – 49, kelas keetiga terbentuk 50 – 59, dan
seterusnya.
Jadi, daftar distribusi frekuensi berdasarkan data diatas, yaitu
Daftar Distribusi Frekuensi

nilai ujian statistika 80 orang mahasiswaNilai ujian Fi
30 – 39 340 – 49 350 – 59 360 – 69 1170 – 79 2480 – 89 2190 – 99 15
80
Atau dapat juga disusun seperti daftar di bawah ini
Daftar Distribusi Frekuensinilai ujian statistika 80 orang mahasiswa
Nilai ujian Fi35 – 44 445 – 54 355 – 64 865 – 74 2175 – 84 2185 – 94 1995 – 104 4
80
P= batas atas kelas – batas bawah kelas
Dalam daftar distribusi frekuensi di kenal istilah-istilah sebagai yang dapat kita
ambil contohnya dari daftar distribusi diatas, yaitu :
Kelas interval (banyak objek atau data yang dikumpulkan dalam kelompok-
kelompok berbentuk a – b).
Frekunsi (jumlah), misalnya, f = 3 untuk kelas interval pertama, atau ada
tiga orang mahasiswa yang mendapat nilai ujian paling rendah 30 dan paling
tinggi 39.

Ujung bawah (bilangan-bilang di sebelah kiri) misal, untuk kelas interval
pertama, kedua dan terakhir adalah 30, 40,...., 90.
Ujung atas (bilangan-bilangan di sebelah kanan) misal, untuk kelas
pertama,kedua, dan terakhir adalah 39, 49,...., 99.
Panjang kelas interval (p) yaitu selisih positif antara tiap ujung bawah
berurutan atau rentang dibagi banyak kelas.
Batas bawah kelas yaitu, ujung bawah dikurang 0,5.
Batas atas kelas yaitu, ujung atas ditambah 0,5
Note : - ditambah / dikurangi 0,5 jika satu decimal
- ditambah / dikurangi 0,05 jika dua decimal dan seterusnya.
Nilai tengah / tanda kelas interval yaitu, ujung bawah di tambah (+) ujung
atas lalu dibagi (:)dua (2).
2. Distribuís Frekuensi Relatif dan Kumulatif
Dalam daftar di atas, frekuensi dinyatakan dengan banyak data yang terdapat dalam
tiap kelas ;jadi dalam bentuk absolut. Jika frekunsi dinyatakan dalam persen (%) maka
diperoleh daftar distribusi frekuensi relatif. Frekuensi absolut dan relatif dapat disajikan
dalam sebuah daftar, yaitu :
Daftar Distribusi Frekuensi Relatif
nilai ujian statistika 80 orang mahasiswa
Nilai ujian frelatif%
30 – 39 3,75

40 – 49 3,75
50 – 59 3,75
60 – 69 13,75
70 – 79 30
80 – 89 26,25
90 – 99 18,25
100
Note :3,75 didapat dari 100% = 3,75 ; untuk yang lain caranya sama.
sebuah daftar yang disebut daftar distribusi frekuensi kumulatif yang dibentuk dari
daftar distribusi frekuensi biasa, dengan jalan menjumlahkan frekuensi demi frekuensi.
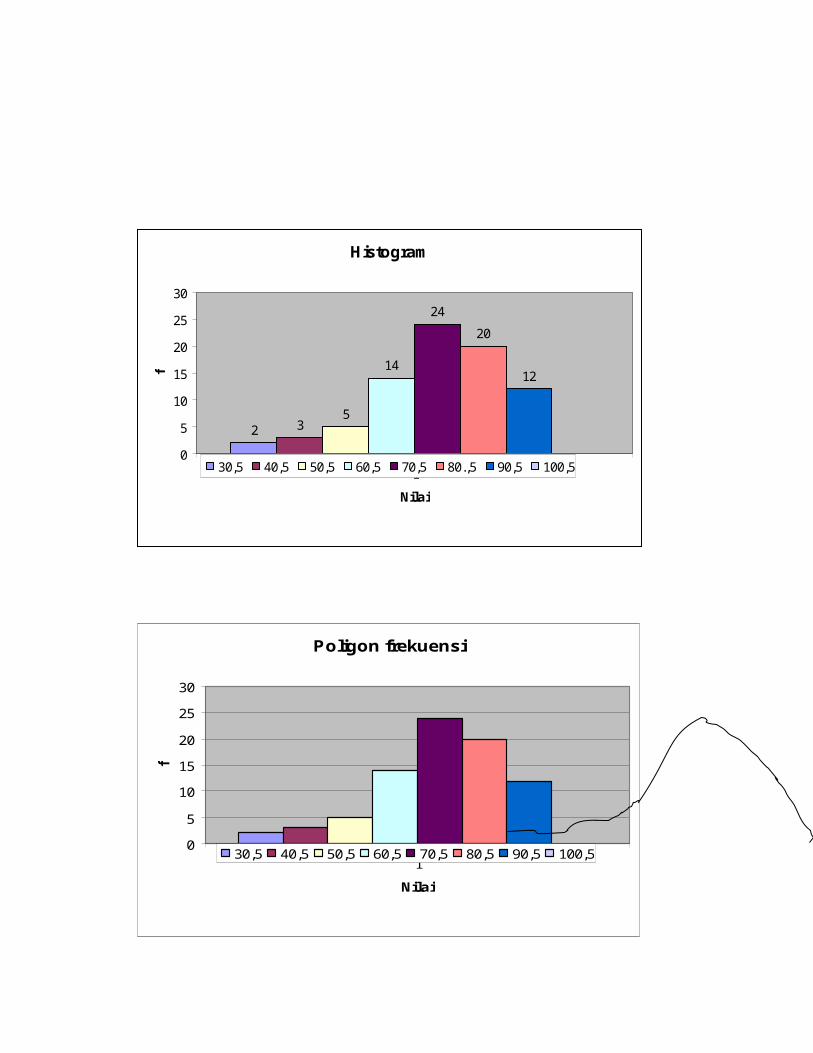
Frekuensi kumulatif ada dua yaitu, frekuensi kurang dari dan atau lebih. Contoh :
Nilai Ujian StatistikaUntuk 80 Mahasiswa
(Kumulatif Kurang Dari)Nilai fkum
Kurang dari 30 0
Kurang dari 40 3
Kurang dari 50 6
Kurang dari 60 9
Kurang dari 70 20
Kurang dari 80 44
Kurang dari 90 65
Kurang dari 100 80

Nilai Ujian Statistika untuk 80Mahasiswa(Kumulatif Atau Lebih)
Nilai fkum
30 atau lebih 80
40 atau lebih 77
50 atau lebih 74
60 atau lebih 71
70 atau lebih 56
80 atau lebih 32
90 atau lebih 12
100 atau lebih 0
Kalau daftar distribusi frekuensi kumulatif dengan frekuensi relatif dikehendaki,
maka hasilnya seperti dalam daftar-daftar di bawah ini
Nilai Ujian StatistikaUntuk 80 Mahasiswa
(Kumulatif Kurang Dari)Nilai fkum (%)
Kurang dari 31 0
Kurang dari 41 2,50
Kurang dari 51 6,25
Kurang dari 61 12,50
Kurang dari 71 30,00
Kurang dari 81 60,00
Kurang dari 91 85,00
Kurang dari 101 100,00
Nilai Ujian Statistikauntuk 80Mahasiswa
(Kumulatif Atau Lebih)Nilai fkum
31 atau lebih 100,00

41 atau lebih 97,50
51 atau lebih 93,75
61 atau lebih 87,50
71 atau lebih 70,00
81 atau lebih 40,00
91 atau lebih 15,00
101 atau lebih 0
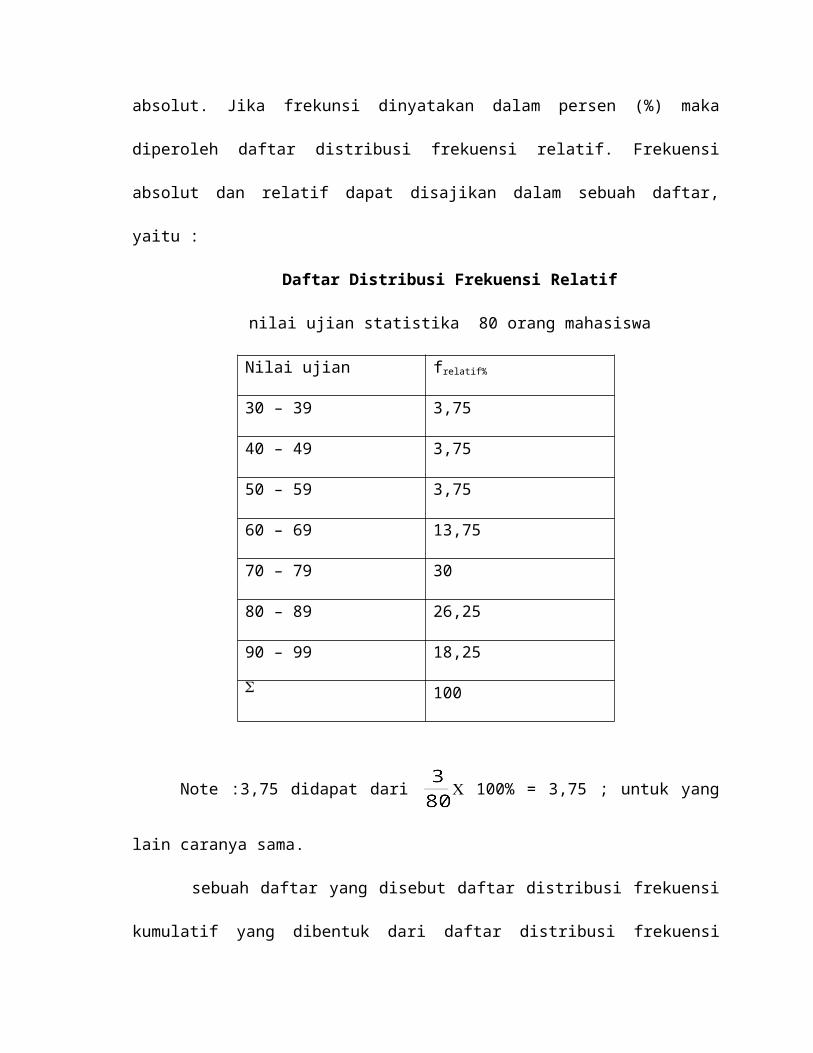
3. Histogram dan Poligon Frekuensi
Dalam histogram dan poligon frekuensi, sumbu mendatar untuk menyajikan kelas
interval, dan sumbu tegak untuk menyatakan frekuensi baik absolut maupun relatif. Contoh
gambar histogram dan poligon frekuensi berdasarkan daftar berikut ini, yaitu
Nilai Ujian Statistika
untuk 80MahasiswaNilai Frekuensi
31 – 40 2
41 – 50 3
51 – 60 5
61 – 70 14
71 – 80 24
81 – 90 20
91 – 100 12
80

Histogram
2 35
14
24
20
12
0
5
10
15
20
25
30
1
Nilai
f
30,5 40,5 50,5 60,5 70,5 80.,5 90,5 100,5
Poligon frekuensi
0
5
10
15
20
25
30
1
Nilai
f
30,5 40,5 50,5 60,5 70,5 80,5 90,5 100,5

Gambar kumulatif kurang dari
0
10
20
30
40
50
60
70
80
90
31 41 51 61 71 81 91 101
Nilai
f

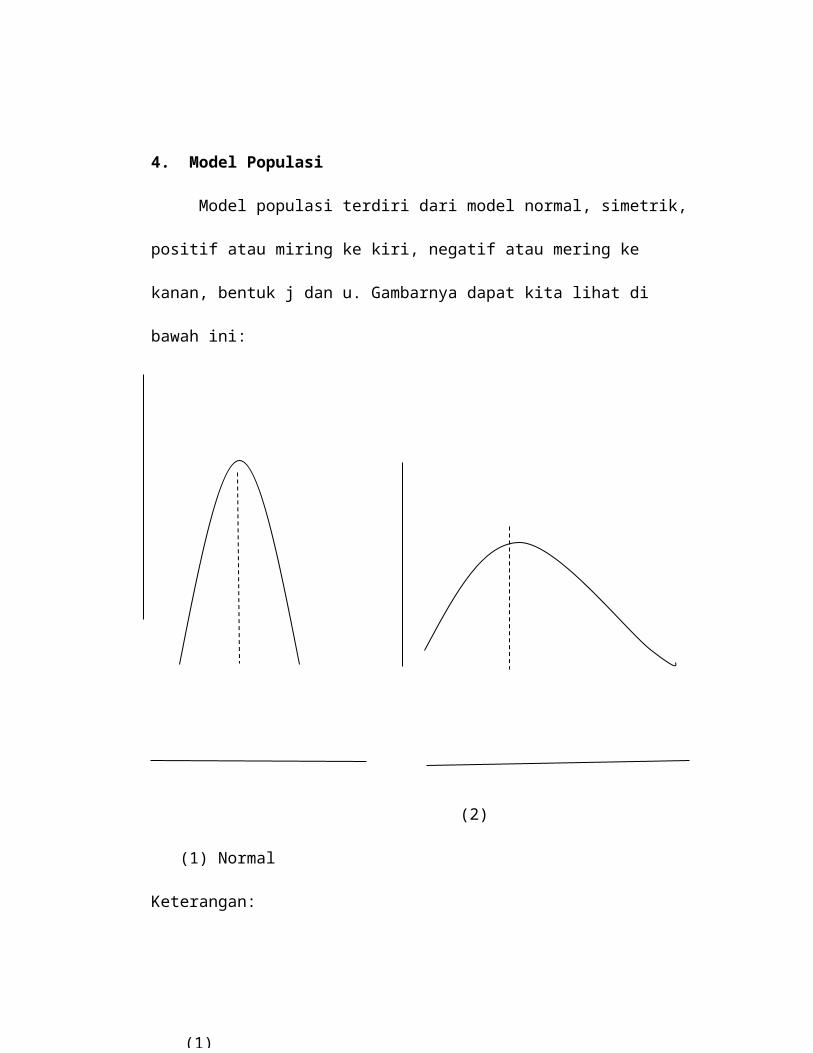
4. Model Populasi
Model populasi terdiri dari model normal, simetrik, positif atau miring ke kiri,
negatif atau mering ke kanan, bentuk j dan u. Gambarnya dapat kita lihat di bawah
ini:
(1) Normal
Keterangan:
1. Model normal, bentuk model ini sselalu simetrik dan mempunyai sebuah puncak.
Kurva dengan sebuah puncak disebut unimodal.
2. Model simetrik, disini juga unimodal dan ini merupakan kebalikan model normal.
(2) Simetrik
(1) Normal
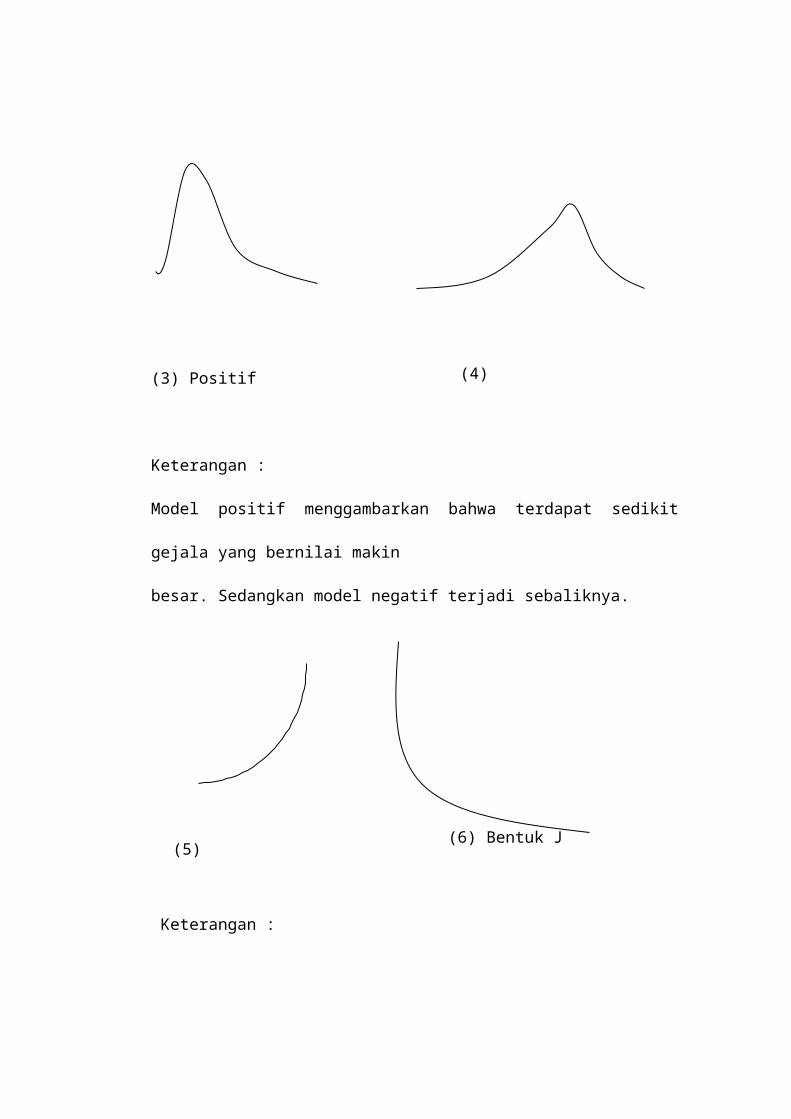
(3) Positif
Keterangan :
Model positif menggambarkan bahwa terdapat sedikit gejala yang bernilai makin
besar. Sedangkan model negatif terjadi sebaliknya.
Keterangan :
Bahwa kedua gambar ini memperlihatkan fenomena yang modelnya
berbentuk J Ini banyak terdapat dalam dunia ekonomi, industri, dan fisika.
(4) Negatif
(7) Bentuk U
(5) Bentuk J(6) Bentuk J terbalik

Keterangan :
Model ini mula-mula terdapat banyak gejala bernilai kecil, kemudian menurun
sementara gejala bernilai besar dan akhirnya menaik lagi untuk nilai gejala yang
makin besar. Kalau puncaknya lebih dari dua namanya multimodal.
Tes formatif
Kerjakan soal di bawah ini setelah saudara mempelajari modul di atas
1. sebutkan macam –macam daftar distribusi
2. apa perbedaan daftar distribusi tertutup dengan daftar distribusi terbuka
3.buatlah contoh daftar distribusi frekuensi terbuka
4.
80 30 50 65 68 75 80 95 75 64
80 90 75 99 100 20 50 60 65 69
100 60 45 35 94 69 78 88 75 78
28 50 75 85 75 55 65 60 88 90
55 91 64 45 81 87 88 89 90 99
89 90 70 50 82 89 90 64 56 70
89 89 82 89 83 100 21 71 81 72
99 90 35 96 84 100 55 75 88 73
97 99 99 97 85 99 65 78 85 65
96 75 100 99 86 20 70 80 86 66
Susunlah daftar distribusi tertutuf
5. soal no. 4 susunlah daftar distribusi relatif
6.soal no.4 susunlah daftar distribusi kumulatif
7. soal no 4. buatlah histogram
8. soal no 4. buatlah poligon frekunsi
9. soal no.4 berbentuk apakah distribusi data tersebut
10. berdasarkan soal no. 9 apakah yang dapat kamu simpulkan mengenai data
tersebut

DAFTAR PUSTAKA
Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta

MODUL PEMBELAJARAN
UKURAN GEJALA PUSAT (CENTRAL TENDENCY)
Tujuan Pembelajaran
Setelah mempelajari modul ini diharapkan
Mahasiswa mampu menjelaskan apa yang dimaksud dengan ukuran gela pusat
Mahasiswa mampu menentukan nilai rata-rata dari sekelompok data Mahasiswa mampu menentukan nilai modus dari sekelompok data Mahasiswa mampu menentukan nilai median dari sekelompok data Mahasiswa mampu menentukan kuarti, desil dan persentil dari
sekelompok data
A. Pengertian
Ukuran gejala pusat merupakan ukuran yang dapat mewakili data secara
keseluruhan. Artinya, jika kesluruhan nilai yang ada dalam data tersebut
diurutkan besarnya dan selanjutnya dimasukkan nilai rata-rata tersebut memiliki
kecendrungan (tenddensi) terletak di urutan paling tengah atau pusat.
B. Jenis-Jenis Ukuran Nilai Pusat
1. rata-rata
2. median
3. modus
4. kuartil
5. desil
6. persentil
1. MEAN (RATA-RATA HITUNG)
Mean merupakan teknik penjelasan kelompok yang didasarkan atas nilai rata-
rata dari kelompok tersebut. Rata-rata (mean) ini didapat dengan menjumlahkan
data seluruh individu dalam kelompok itu, kemudian dibagi dengan jumlah
individu yang ada pada kelompok tersebut.
Untuk mencari Mean untuk data tunggal dapat menggunakan rumus:
Ket: = rata-rata
Xi = data ke ..i
n=banyaknya data
Untuk mencari mean untu data berkelompok dapat menggunakan rumus:
Ket: fi frekuensi kelas ke ..i
Untuk mencari mean bengan menggunakan coding yaitu:
Dimana := Mean
fi = Jumlah data/sampelXi = Nila tengah kelasXo = Nilai tengah kelas coding
p = Panjang interval kelasCi = kelas Coding
Contoh soal:
1. Sepuluh pegawai di PT. samudra penghasilan sebulannya dalam satuan ribu
rupiah adalah seperti berikut:90, 120, 160, 180, 190, 90, 180, 70, 160, hitunglah
rata-rata penghasilan pegawai tersebut?
Jawab: Me=(90+120+160+60+180+190+90+180+70+160) : 10
Me=150
Jadi, penghasilan rata-rata pegawai di PT Samudera =Rp.150.000,00
2.Tentukanlah Mean (rata-rata hitung) dari distribusi frekuensi berikut ini:
Daftar
hasil tingkat kepuasan masyarakat
atas layanan lembaga negara
Interval Fi
50 – 54
55 – 59
60 – 64
65 – 69
70 – 74
75 – 79
80 – 84
6
10
9
25
28
13
9
jumlah 100
Jawab:
Interval Fi Xi Fi Xi
50 – 54 6 52 312

55 – 59
60 – 64
65 – 69
70 – 74
75 – 79
80 – 84
10
9
25
28
13
9
57
62
67
72
77
82
570
558
1675
2016
1001
738
jumlah 100 6870
= 68,7
Jadi,mean dari data di atas adalah 68,7
Mencari Mean Dengan Menggunakan Coding
Daftar
tingkat kepuasan masyarakat
atas layanan lembaga negara
=72-3,3
= 68,7
.
2. MODUS
Modus merupakan teknik penjelasan kelompok yang didasarkan atas nilai yang
sedang populer (yang sedang menjadi mode) atau yang sering muncul dalam
kelompok tersebut.
Data dapat dibagi 2, yaitu:
1. Data kualitatif (Rata-rata)
Interval fi xi ci fici
50 – 54 6 52 -3 -18
55 – 59 10 57 -2 -20
60 – 64 9 62 -1 -9
65 – 69 25 67 0 0
70 – 74 28 72 1 28
75 – 79 13 77 2 26
80 - 84 9 82 3 27
Jumlah 100 34

Contoh data kualitatif:
Seorang peneliti datang ke Yogyakarta, dan melihat para siswa dan
mahasiswa masih banyak yang naik sepeda. Selanjutnya peneliti
dapat menjelaskan dengan modus, bahwa (kelompok) siswa dan
mahasiswa di Yogya masih banyak yang naik sepeda.
Kebanyakan pemuda Indonesia menghisap rokok.
Pada umumnya pegawai Negeri tidak disiplin kerjanya
Pada umumynya warna mobil tahun 70-an adalah cerah, sedangkan
tahun 80-an warnanya gelap
2. Data kuantitatif (Modus)
Untuk mencari Modus dari suatu data dapat digunakan rumus:
Dimana:
Mo = Modus
b = Batas bawah kelas modus
p = panjang interval kelas
b1 = frekuensi pada kelas modus (frekuensi pada kelas terbanyak )
dikurangi frkuensi kelas interval terdekat sebelumnya.
b2 = frekuensi kelas modus dikurangi frekuensi kelas interval
berikutnya.
Contoh soal:
Daftar skor tingkat kepuasan pelanggan
terhadap layanan lembaga publik
Interval Fi
50 – 54
55 – 59
60 – 64
65 – 69
70 – 74
75 – 79
80 – 84
6
10
25
25
28
13
9
Interval 100
Jawab:
= 70,33
Jadi, Modus dari data di atas adalah 70,33
3. MEDIAN
Median adalah salah satu teknik penjelasan kelompok yang didasarkan atas
nilai tengah dari kelompok data yang telah disusun urutannya dari yang terkecil
sampai yang terbesar, atau sebaliknya dari yang terbesar sampai yang terkecil.
90, 120, 160, 180, 190, 90, 180, 70, 160,

70, 90,90,120,160,160,180,180,190 data ganjil
70, 90,90,120,160,180,180,180,190, 200 data genap
Cara menghitung median untuk data berkelompok adalah:
Dimana :
Me = Median
b = Batas bawah, dimana median terletak
P = Panjang interval kelas
N = banyak data/jumlah data
F = Jumlah semua frekuensi sebelum kelas median
f = frekuensi kelas median.
Contoh soal:
Daftar skor tingkat kepuasan pelanggan
terhadap layanan lembaga publik
Interval Fi
50 – 54
55 – 59
60 – 64
65 – 69
70 – 74
75 – 79
80 – 84
6
10
9
25
28
13
9
Interval 100

Jawab:
Pertama kita cari dulu setengah dari jumlah data
=
Selanjutnya kita cari letak data ke 50 tersebut terletak dimana
=64,5 +5
=69,5
4. QUARTIL
Quartil dapat diartikan sebagai:
- Nilai yang membagi data terurut menjadi empat bagian yang sama
- Data tunggal
- Data berkelompok
Untuk mencari Quartil untuk data berkelompok adalah:
70, 90,90,120,160,160,180,180,190
K1 =90
K2 = Me=160
K3 = 180

Dimana:
Q = Quartil
b = Batas bawah, dimana median terletak
P = Panjang kelas interval dengan frekuensi terbanyak.
n = banyak data/jumlah data
F = Jumlah semua frekuensisebelum kelas median
f = frekuensi kelas median.
Contoh:
Daftar skor tingkat kepuasan pelanggan
terhadap layanan lembaga publik
Interval Fi
50 – 54
55 – 59
60 – 64
65 – 69
70 – 74
75 – 79
80 – 84
6
10
9
25
28
13
9
Interval 100

Q1= 59,5+5
=59,5+5
=64,5
Q3=69,5+5(75-50/28)
=69,5+4,45
=73,95
Note: Untuk ukuran Desil dan persentil merupakan perluasan rumus median dan
kuartil, Desil membagi data menjadi 10 bagian yang sama sedangkan persentil
membagi data menjadi 100 bagian yang sama.
Tes Formatif
Kerjakan soal di bawah ini setelah andah mempelajari modul di atas
1.jelaskan apa yang dimaksud dengan ukuran gejala pusat
2. tentukan nilai rata-rata hitung dari data di bawah ini menggunakan rumus biasa.
Daftar skor tingkat kepuasan pelangganterhadap layanan lembaga publik
Nilai f
21-3031-4041-5051-6061-7071-8081-9091-100
261830201088
Jumlah 102

3. tentukan nilai rata-rata hitung menggunakan cara coding dari soal no.2
4. jelaskan apa yang dimaksud dengan modus
5.tentukan nilai modus dari data soal no.2
6. jelaskan apa yang dimaksud dengan median
7. tentukan nilai median dari data soal no.2
8. jelaskan apa yang dimaksud dengan kuartil
9.tentukan nilai kuartil dari data di atas
10. jelaskan hubungan antara nilai masing-masing ukuran gejala pusat
DAFTAR PUSTAKA
Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta

MODUL PEMBELAJARAN
UKURAN SIMPANGAN, DISPERSI DAN VARIASI
Mahasiswa Dapat Menentukan Nilai Standar Deviasi Dari Sekelompok
Data
Mahasiswa Mampu Menjelaskan Kegunaan Dari Standar Deviasi
Mahasiswa Dapat Menentukan Bilangan Baku Dari Sekelompok Data
Mahasiswa Mengetahui Kegunaan Dari Bilangan Baku
Ukuran simpangan, dispersi dan variasi menggambarkan bagaimana
berpencarnya data kuantitatif.
Beberapa ukuran variasi yang akan diuraikan di sini adalah
1. Rentang
Ukuran variasi yang paling mudah ditentukan ialah rentang. Sehingga
ukuran ini banyak digunakan dalam cabang lain dari statistika, seperti
statistika industri.
Rumusnya adalah
RENTANG = NILAI MAXIMUM DATA-NILAI MINIMUM DATA
2. Rentang antar kuartil
Rentang antar kuartil juga mudah ditentukan, dan ini merupakan selisih
antara Kuartil ketiga (K3) dan Kuartil pertama (K1).
Rumusnya adalah RAK = K3 – K1

3. Simpangan Kuartil
Simpangan Kuartil atau deviasi kuartil atau disebut juga rentang semi
antar kuartil, harganya setengah dari rentang antar kuartil.
Jadi, rumusnya adalah
SK = ½ RAK
atau
4. Rata-Rata Simpangan
Misalkan data hasil pengamatan berbentuk x1, x2, x3, . . . , xn dengan rata-
rata . Selanjutnya kita tentukan jarak antara setiap data dengan rata-rata
, dengan simbol (harga mutlak dari selisih xi dengan . Jika jarak-
jarak : , , . . . , dijumlahkan, lalu dibagi oleh n, maka
diperoleh satuan yang disebut rata-rata simpangan atau rata-rata deviasi.
Rumusnya adalah
RS =
70, 90,90,120,160,160,180,180,190
Standar Deviasi (Simpangan Baku)
Ukuran yang paling banyak digunakan adalah simpangan baku(standar
deviasi).Pangkat dua dari standar deviasi dinamakan varians. Untuk sampel,
standar deviasi akan diberi simbol s, sedangkan untuk populasi diberi simbol
SK = ½ (K3 – K1)

(sigma). Varians sampel (s2) merupakan statistik dan varians populasi ( dan 2)
merupakan parameter.
Jika kita mempunyai sampel berukuran n dengan data x1, x2, x3, . . . , xn
dan rata-rata , maka statistik s2 dihitung dengan rumus :
Untuk mencari simpangan baku s, s2 diambil harga akarnya yang positif.
Bentuk lain untuk rumus varians sampel ialah :
Dalam rumus di atas, cukup menggunakan nilai data aslinya berupa nilai
data dan jumlah kuadratnya. Sangat dianjurkan bila menghitung standar
deviasi menggunakan rumus ini karena kekeliruannya lebih kecil.
Jika data dari sampel telah disusun dalam daftar distribusi frekuensi, maka
untuk menentukan varians s2 dipakai rumus :
S2 =
S2 =
S2 =
S2 =

atau lebih baik menggunakan rumus di atas menggunakan nilai tengah atau
tanda kelas interval.
Ada pula cara yang lebih singkat dan mudah untuk menentukan varians s2
sehingga perhitungan lebih sederhana, yaitu dengan cara coding (sandi) :
BILANGAN BAKU
Ket: = bilangan baku ke iXi = data ke i/ nilai tengah kelas ke i
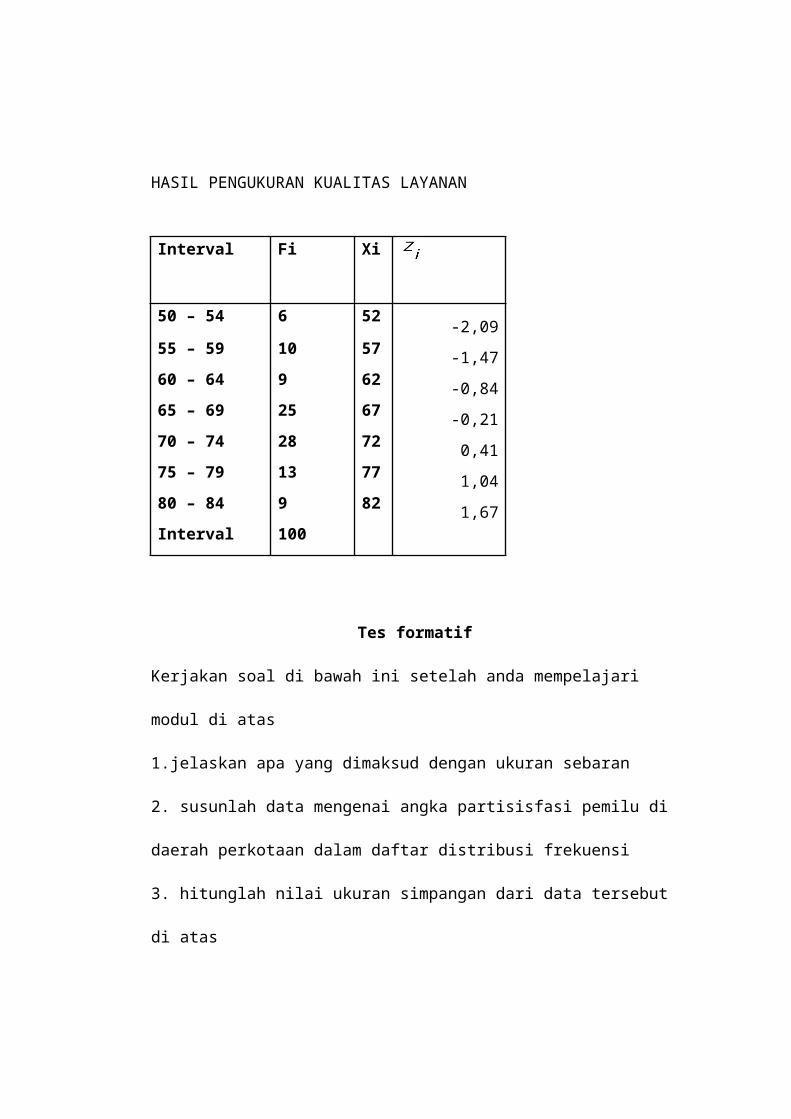
S = simpangan baku
Rata2= 68,7 S = 7,98
HASIL PENGUKURAN KUALITAS LAYANAN
S =

Interval Fi Xi
50 – 54 6 52-2,09
55 – 59 10 57-1,47
60 – 64 9 62-0,84
65 – 69 25 67-0,21
70 – 74 28 720,41
75 – 79 13 771,04
80 – 84 9 821,67
Interval 100
Tes formatif
Kerjakan soal di bawah ini setelah anda mempelajari modul di atas
1.jelaskan apa yang dimaksud dengan ukuran sebaran
2. susunlah data mengenai angka partisisfasi pemilu di daerah perkotaan dalam
daftar distribusi frekuensi
3. hitunglah nilai ukuran simpangan dari data tersebut di atas
DAFTAR PUSTAKA

Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta
Pengujian Normalitas Data Menggunakan Chi²

Seperti yang telah diketahui bahwa Statistik Parametris itu bekerja
berdasarkan asumsi bahwa data setiap variable yang akan dianalisis berdistribusi
normal. Untuk itu sebelum menggunakan teknik Statistik Parasimetris, maka
kenormalan data harus diuji terlebih dahulu karena jika sebuah data tidak normal
maka statistic parasimetris tidak dapat digunakan. Namun biasanya yang membuat
sebuah data menjadi tidak noramal biasanya karena adanya kesalahan instrument
dan pengumpulan data, maka mengakibatkan data yang diperoleh menjadi tidak
akan normal.
Tetapi bila data sudah valid, tetapi distribusinya tidak membentuk
distribusi normal, maka seorang peneliti baru membuat keputusan untuk
menggunakan teknik statistic nonparasimetris. Berikut ini akan dibahas teknik
untuk menguji normalitas data dengan menggunakan Chi kuadrat (χ²).
Cara I
Chi Kuadrad (χ²)
Pengujian normalitas data dengan (χ²) dilakukan dengan cara
membandingkan kurve normal yang membentuk dari data yang telah terkumpul
(B) dengan kurve normal baku/standar (A). jadi membandingkan antara (B : A).
Bila B tidak berbeda secara signifikan dengan A, maka B merupakan data yang
berdistribusi normal.
Sperti yang telah kita ketahui bahwa kurve normal baku yang luasnya
mendekati 100% itu di bagi menjadi 6 bidang berdasarkan simpangan bakunya,
yaitu tiga bidang di bawah rata-rata (mean) dan tiga bidang diatas rata-rata. Luas

bidang dalam kurve normal baku adalah : 2,27%; 13,53%; 34,13%; 13,53%;
2,27%.
Contoh :
Data nilai ujian mata kuliah statistik 150 mahasiswa
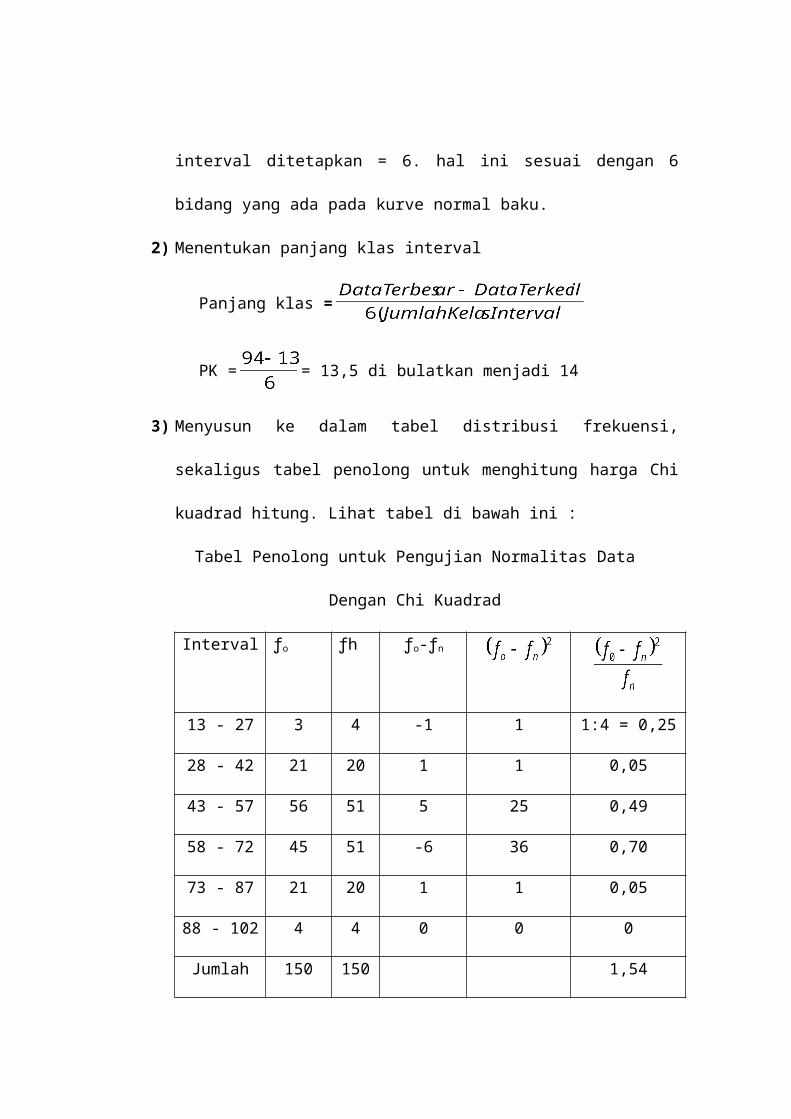
Langkah-langkah yang diperlukan adalah :
1) Menentukan jumlah kelas interval untuk pengujian normalitas denagn Chi
kuadrad ini, jumlah klas interval ditetapkan = 6. hal ini sesuai dengan 6 bidang
yang ada pada kurve normal baku.
2) Menentukan panjang klas interval
Panjang klas =
PK = = 13,5 di bulatkan menjadi 14
3) Menyusun ke dalam tabel distribusi frekuensi, sekaligus tabel penolong untuk
menghitung harga Chi kuadrad hitung. Lihat tabel di bawah ini :
Tabel Penolong untuk Pengujian Normalitas Data

Dengan Chi Kuadrad
Interval ƒο ƒh ƒo-ƒn
13 - 27 3 4 -1 1 1:4 = 0,25
28 - 42 21 20 1 1 0,05
43 - 57 56 51 5 25 0,49
58 - 72 45 51 -6 36 0,70
73 - 87 21 20 1 1 0,05
88 - 102 4 4 0 0 0
Jumlah 150 150 1,54
Catatan :
ƒo= frekuensi / jumlah data hasil obsevasi
ƒh = jumlah / frekuensi yang diharapakan (prosentase luas tiap bidang
dikalikan dengan bidang n)
ƒο – fh = selisi data ƒо dengan ƒh
4) Menghitung ƒh (frekuensi yang diharapakan)
Cara menghitung frekuensi yang diharapkan didasarkan pada present Asi
luas tiap bidang kurve normal dikaitkan jumlah data observasi (jumlah
individu dalam sample). Dalam hal ini jumlah individu dalam sample = 150,
jadi :

a) Baris pertama dari atas : 2,7% x 150 = 4,05 di bulatkan menjadi 4
b) Baris ke dua 13,53% x 150 = 20,29 dibulatkan menjadi 20
c) Baris ke tiga 34,13% x 150 = 51,19 dibulatkan menjadi 51
d) Baris ke empat 34,13% x 150 = 51,19 dibulatkan menjadi 51
e) Baris ke lima 13,53% x 150 = 20,29 dibulatkan menjadi 20
f)Baris ke enam 2.7% x 150 = 4,05 dibulatkan menjadi 4
5) Memasukan harga-harga frekuensi yang diharapkan(ƒh) ke dalam tabel kolom
ƒh, sekaligus menghitung harga-harga dan
menjumlahkannya harga adalah merupakan harga Chi Kuadrad (χ²)
hitung.
6) Membandingkan harga Chi Kuadrad hitung denagn Chi Kuadrad Tabel. Bila
harga Chi Kuadrad Hitung lebih kecil dari pada Chi Kuadrad Tabel, maka
dustribusi data dinyatakan normal, dan sebaliknya apabila lebih besar maka
dinyatakan tidak normal.
Dalam perhitungan ditemukan Chi Kuadrad Hitung = 1,54. selanjutnya
harga ini bila dibandingkan dengan Chi kuadrad tbel denagn derajad kebebasan 6
– 1 = 5. Berdasarkan tabel diatas maka dapat diketahui bahwa bila derahjad
kebebasan 5 dan jesalahan yang ditetapkan = 5%, maka harga Chi kuadrad tabel =
11,070 , karena harga Chi kuadrad hitung (1,54) lbih kecil dari harga Chi kuadrad

tabel (11,070). Maka distribusi data niali statistik 150 mahasiswa tersebut dapat
dinyatakan distribusi normal.
Cara II
Kriteria normalitas
→ Apabila chi kuadrat hitung lebih kecil daripada chi kuadrat table
Contoh Normalitas data
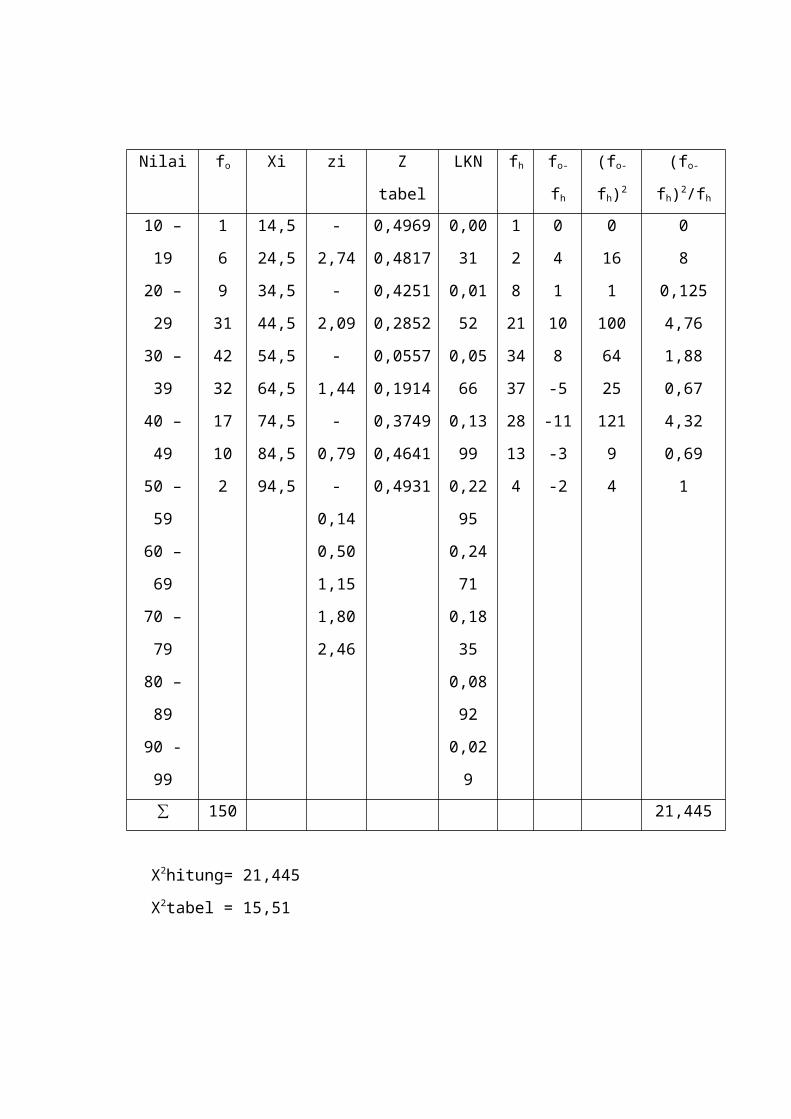
= 56,7
S = 15,36
Nilai fo Xi zi Z tabel LKN fh fo-fh (fo-fh)2 (fo-fh)2/fh
10 – 19
20 – 29
30 – 39
40 – 49
50 – 59
60 – 69
70 – 79
80 – 89
90 - 99
1
6
9
31
42
32
17
10
2
14,5
24,5
34,5
44,5
54,5
64,5
74,5
84,5
94,5
-2,74
-2,09
-1,44
-0,79
-0,14
0,50
1,15
1,80
2,46
0,4969
0,4817
0,4251
0,2852
0,0557
0,1914
0,3749
0,4641
0,4931
0,0031
0,0152
0,0566
0,1399
0,2295
0,2471
0,1835
0,0892
0,029
1
2
8
21
34
37
28
13
4
0
4
1
10
8
-5
-11
-3
-2
0
16
1
100
64
25
121
9
4
0
8
0,125
4,76
1,88
0,67
4,32
0,69
1
∑ 150 21,445
X2hitung= 21,445
X2tabel = 15,51
z = Sebagai contoh: z = =
X1 : batas atas kelas = -2,42

: rata-rata
S : standar deviasi
MENGUJI KESAMAAN DUA RATA-RATA :
Tujuan Pembelajaran
Mahasiswa mampu menguji hipotesis komparatif
Mahasiswa mampu menguji uji dua rata-rata uji du pihak
Mahasiswa mampu menguji uji dua rata-rata uji satu pihak, pihak kanan
Mahasiswa mampu menguji uji dua rata-rata pihak kiri

A. UJI DUA PIHAK
Banvak penelitian yang memerlukan perbandingan antara dua
Keadaan atau tepatnya dua populasi. Misalnya membandingkan dua cara
mengajar, dua cara produksi, daya sembuh dan dua macam obat dan lain
sebagainya. Untuk keperluan ini akan digunakan dasar distribusi
sampling mengenai selisih statistik, misalnya selisih rata-rata dan selisih
proporsi.
MisaIkan kita mempunyai dua populasi normal masing-mabing
dengan rata-rata , dan sedangkan simpangan bakunya dan .
Secara independen dari populasi kesatu diambil sebuah sempel acak
berukuran n1, sedangkan dari populasi kedua sebuah sampel acak berukuran
n2. Dari kedua sampel ini berturut-turut didapat s1 dan s2. akan diuji
tentang rata-rata dan
Pasangan hipotesis nol dan tandingannya yang akan diuji adalah
Untuk ini kita bedakan hal-hal berikut:
Hal A) . = dan d ike tahui
Statistik yang gunakan jika H0 benar, adalah:
RUMUS IRUMUS I

Dengan taraf nyata α maka kriteria pengujian adalah: terima H0 jika –z1/2 (1-α) < z
< z1/2 (1-α) di mana z1/2 (1-α) didapat dari daftar normal baku dengan peluang 1/2
(1-α) dalam hal ini H0 ditolak.
Hal B) . = tidak d ike tahui
Dengan
Menurut teori distribusi sampling, maka statistik t diatas berdistribusi
Student dengan dk = (n1 + n2 – 2). Kriteria pengujian adalah: terima H0 jika –t1 -
1/2α < t < t1 -1/2α dimana t1 -1/2α didapat dari daftar distribusi t dengan dk = (n 1 +
n2 - 2) dan peluang (1 - 1/2a). Untuk harga-harga t lainnya Ho ditolak.
Cantoh:
Dua macam makanan A dan B diberikan kepada ayam secara
terpisah untuk jangka waktu tertentu. Ingin diketahui macam
makanan yang mana yang lebih baik bagi ayam tersebut. Sampel acak
yang terdiri atas 11 ayam diberi makanan A dan 10 ayam diberi
makanan B. Tambah berat badan ayam (dalam ons) hasil percobaan
adalah sebagai berikut:
Makanan A 3,1 3,0 3,3 2,9 2,6 3.0 3,62,7 3,8 4,0 3,4
Makanan B 2,7 2,9 3,4 3,2 1,3 2 ,9 3,03,0 2,6 3,7

Dalam taraf nyata α = 0,05, tentukan apakah kedua macam
makanan itu sama baiknya atau tidak.
Jawab:
Dari data di atas didapat 3,22, = 3,07, = 0,1996 dan = 0,1112.
Simpangan baku gabungan, dari Rumus "s" didapat s = 0,397. Maka
RUMUS II:
Harga to 975 dengan dk = 19 dari dattar distribusi Student adalah
2,09. Kriteria pengujian adalah: terima H0 jika t hitung terletak antard -
2,09 dan, 2,09 dan tolak Hf) jika t mempunyai harga-harga,l ain.
Dari penelitian didapat t = 0.862 dan ini jelas ada dalam daerah
penerimaan. Jadi H0 diterima.
Kesimpulan: keduamacam makanan ayam i tu memberikan
tambahan berat daging yang sama terhadap ayam.-ayam itu.
Untuk pengujian di atas telah dimisalkan tambahan berat daging ayam
berdistribusi normal dengan varians yang sama besar.
H a l C ) . σ 1 ≠ σ 2 d a n k e d u a - d u a n y a t i d a k d i k e t a h u i
Jika kedua simpangan baku tidak sama tetapi kedua populasi
berdistribusi normal, hingga sekarang belum ada statistik yang, tepat yang dapat
digunakan. Pendekatan yang cukup memuaskan adalah dengan menggunakan
statistik t' sebagai berikut:
Kriteria pengujian adalah: diterima H0 jika
RUMUS IVRUMUS IV

Dengan :
tβ, m didapat dari daftar distribusi Student dengan peluang β dan dk =
m. Untuk harga-harga t lainnya, Ho ditolak.
Contoh:
Semacam barang dihasilkan dengan menggunakan dua proses. Ingin
diketahui apakah kedua proses itu menghasilkan hasil yang sama atau
tidak terhadap kualitas barang itu ditinjau dari rasa-rasa daya tekannya.
Untuk itu diadakan percobaan sebanyak 20 dari hasil proses kesatu dan 20
pula dari hasil proses kedua. Rata-rats dan simpangan bakunya berturut-
turut x1 = 9,25 kg, s1 = 2,24 kg, X2 = 10,40 kg dan s2 = 3,1 2 kg. Jika
varians kedua populasi tidak sama, dengan taraf nyata 0,05,
bagaimanakah haslinya?
Jawab: Hipotesis H,, dan tandingan H1 adalah:
H0 : µ1 = µ2 ; kedua proses menghasilkan barang dengan rasa-rasa
Jaya tekan yang sama.
H1 µ1 ≠ µ2 ; kedua proses menghasilkan barang dengan rasa-rasa
daya, tekan yang berlainan.
Harga-harga yang dipedukan adalah
t1 = t(0,975).19 = 2,09 t2 = t(0,975).19 = 2.09
sehingga

Kriteria pengujian adalah: Terima Ho jika — 2,09 < t' < 2,09 dan
tolak HO dalam hal lainnya. Jelas: bahwa t' = 1,339 ada dalam dae rah
pene r imaan H 0 . Jad i k i t a t e r ima H 0 da l am t a ra f yang nyata 0,05.
Hal D). Observasl berpasangan
Hipotesis nol dan tandingannva adalah:
Jika B1, = x1 - y1, B2 = X 2 - Y2, . . ., Bn-= Xn - Yn Yn, maka data B1, B 2 , . . . ,
Bn menghasilkan rata-rata B dan simpangan baku SB.. Untuk pengujian hipotesis,
gunakan statistik:
Kritria diterima H0 jika –t1- < t < t1- dimana t1- didapat dari
daftar distribusi t dengan peluang (1 – 1/2α) dan dk = (n1 – 1). Dalam hal lainnya
H0 ditolak
Contoh
RUMUS VRUMUS V

Dan daftar distribusi t dengan peluang 0,975 dan dk = 9 didapat tO,975=
2,26. Ternyata t = 0,762 ada dalam daerah penerimaan Ho. Jadi penelitian
menghasilkan uji yang tak berarti.
B. UJI SATU PIHAK

Sebagaimana dalam uji dua pihak, untuk uji satu pihak pun
dimisalkan bahwa kedua populasi berdistribusi normal dengan ra ta-ra ta µ 1 dan
µ 2 dan s impangan baku, Karena umumnya besar σ 1 dan σ 2 tidak
diketahui, maka di sini akan ditinjau hal-hal tersebut untuk keadaan σ 1 = σ 2
atau σ 1 ≠ σ 2 .
Hal A). Uji pihah kanan
Yang diuji adalah
Dalam hal σ 1 = σ 2 maka statistik yang digunakan ialah statistik t
seperti dalam) dengan s 2 . Kriteria pengujian yang berlaku ;alah:
terima Ho jika t < t1 _ α, dan tolak Ho, jika t mempunyai harga-harga lain.
Derajat kebebasan untuk daftar distribusi t ialah (n1 + n2 — 2) dengan
peluang (1 — a). Jika σ 1 ≠ σ 2 , maka statistik yang digunakan adalah
statistik t' seperti dalam Rumus). Dalam hal ini, kriteria pengujian adalah:
tolak hipotesis H0, jika
dan terima H0 jika terjadi sebaliknya, dengan w1 = / , , w2 / , t1 = t(1-α), (n1
-1). untuk penggunaan daftar distribusi t ialah (1 — α) sedangkan dk-nya
masing-masing (n1 — 1) dan (n2 — 1).
Contoh:
Diduga bahwa pemuda yang senang berenang rata-rata lebih tinggi
badannya daripada pemuda sebaya yang tidak senang berenang. Untuk
meneliti ini telah diukur 15 pemuda yang senang berenang dan 20 yang

tidak senang berenang. Rata-rata tinggi badannya berturut•turut 167,2 cm
dan 160,3 cm. Simpangan bakunya masing masing 6,7 cm dan 7,1 cm.
Dalam taraf nyata α = 0,05, dapatkah kita mendukung dugaan tersebut?
Jawab
Jika distribusi tinggi badan untuk kadua kelompok pemuda itu normal dan
σ 1 = σ 2 maka statistik t dalam Rumus . Kita punya n1=15, = 167,2 cm,
s1,= 6,7 cm, n2 = 20,x2 = 160,3 cm dan s:2 7,1 cm
Dari daftar distribusi t dengan peluang 0,95 dan dk = 33, didapat t0,.95 =
1,70
Dari penelitian didapat t = 2,913 dan ini lebih besar dari t = 1,70.
Jadi Ho: ditolak, di mana indeks satu menyatakan
pemuda yang senang berenang. Penyelidikan memberikan hasil
yang berarti pada taraf 5%'. Dugaan dimuka dapat diterima.
Jika untuk contoh di muka dimisalkan σ 1 ≠ σ 2 , maka digunakan
statistik t' dalam RUMUS VI Harga-harga yanig perlu adalah
w1 = 44,89/15 = 2,99, w2=50.41/20= 2,52
t1 = t(0,95).14 = 1,76 dan t1 = t(0,95).19 = 1,73
Sehingga diperoleh
Kriteria pengujian adalah: tolak Ho jika t' ≥, 1,75. Karena t' = 2,94
H0, ditolak dan hasil dapat disimpulkan
Untuk obserpasi berpasangan, pasangan hipotesis nol Ho dan
hipotesis tandingan HI untuk uji pihak kanan adalah:
Statistik yang digunakan masih statistik t dengan RUMUS V dalam
observasi berpasangan dan tolak Ho jika t≥t1-α dimana t1-α didapat dari daftar
distribusi Student dengan dk =(n .-1) dan peluang (1-α)
Contoh:
Untuk mempe!ajari kemampuan belaiar tentang meniumiahkan
bilangan, 10 anak laki-laki dan 10 anak perempuan telah diambil
secara acak. Dari Pengamatan masa lampau kemampuan,.beh;ar anak
laki-laki.mumnya lebih baik daripada kPmampuan belaiar anak
perempuan. Hasil ujian yang dilakukan adalah:
Laki-
laki
3
0
2
1
2
1
2
7
2
0
2
5
2
7
2
2
2
8
1
8Peremp
uan
3
1
2
2
3
7
2
4
3
0
1
5
2
5
4
2
1
9
3
8Apakah yang dapat distmpulkan dari hasil ujian ini?
jawab: Ambil µz, = rata-rata hasil ujian untuk anak laki-laki dan
µp = rata-rata atas ujian untuk anak perempuan. Akan diuji pasangan
hipotesis
Dari data di atas, setelah dihitung berdasarkan beda (selisih)
tiap
pasang data didapat = 4,4 dan sb = 11,34. Sehingga

Dengan dk = 9 dan peluang 0,95 dari daftar distribusi Student
didapat to.95 = 1,83. Karena t =. 1,22 lebih kecil dari 1,83
maka Ho diterima. dalam hai ini masih dapat dikatakan bahwa
rata-rata hasil ujian anak laki-laki lebih baik daripada rata-rata
hasil ujian anak perempuan.
Hal B). Uji pihak kiri
Perumusan hipotesis H0 dan hipotesis tandingan H1 untuk uji pihak kiri
Adalah
Langkah-langkah yang ditempuh dalam hal ini sejalan dengan yang
dilakukan untuk uji pihak kanan.
Jika σ 1 = σ 2 , kedua-duanya nilainya tak diketahui, maka digunkan
statistik t dalam kriteria pengujian adalah to lak Ho j ika t ≤ - t 1 - α
didapa t dar i daf t a r distribusi I dengan dk = (n1 + n2 — 2) dan peluang
(1 — α). Untuk harga-harga t lainnya, H0 diterima
Untuk observasi berpasangan, hipotesis h0 dan tandingan yang akan diuji adalah
tolak H0, jika t ≤ -t(1 - α), (n - 1) dan terima Ho untuk t
RUMUS VIRUMUS VI

DAFTAR PUSTAKA
Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta

MODUL PEMBELAJARAN
ANALISIS KORELASI
Tujuan Pembelajaran
Mahasiswa mampu menghitung koefisien korelasi
Mahasiswa mampu menguji hipotesis asosiatif
Pendahuluan
Hipotesis asosiatif merupakan dugaan adanya hubungan antar variabel
dalam populasi, melalui data hubungan variabel dalam sampel. Untuk itu dalam
langkah awal pembuktiannya, maka perlu dihitung terlebih dahulu koefisien
korelasi antar variabel dalam sampel, baru koefisien yang ditemukan itu diuji
signifikansinya. Jadi menguji hipotesis asosiatif adalah menguji koefisiensi
korelasi yang ada pada sampel untuk diberlakukan pada seluruh populasi dimana
sampel diambil ,dilakukan pada seluruh populasi maka tidak diperlukan pengujian
signifikansi terhadap koefisien korelasi yang ditemukan.
Dalam modul ini akan dipelajari materi, koefisien korelasi linier sederhana,
menguji derajat hubungan dua variable menggunakan uji t.
Setelah mempelajari modul ini diharapkan mahasiswa dapat:
1. menentukan koefisien korelasi
2. menentukan derajat determinasi
3. menguji derajat hubungan dua variabel menggunakan uji t
ANALISIS KORELASI
Terdapat tiga macam bentuk hubungan antar variabel, yaitu hubungan
simetris, hubungan sebab akibat (kausal) dan hubungan interaktif (saling
mempengaruhi). Untuk mencari hubungan antara dua variabel atau lebih
dilakukan dengan menghitung korelasi antar variabel yang akan dicari
hubungannya.

Hubungan dua variabel atau lebih dinyatakan positif, bila nilai suatu
variabel ditingkatkan, maka akan meningkatkan variabel yang lain, dan sebaliknya
bila satu variabel diturunkan maka akan menurunkan variabel yang lain.
Hubungan dua variabel atau lebih dinyatakan negatif, bila nilai satu variabel
dinaikkan maka akan menurunkan nilai variabel yang lain, dan juga sebaliknya
bila nilai satu variabel diturunkan, maka akan menaikkan nilai variabel yang lain.
Gambar1. Korelasi Positif Gambar 2. Korelasi Negatif
Besarnya koefisien korelasi dapat diketahui berdasarkan penyebaran titik-titik
pertemuan antara dua variabel misalnya X dan Y. Bila titik-titik itu terdapat
dalam satu garis, maka koefisien korelasinya = 1 atau –1.
Korelasi Product Moment
Teknik korelasi ini digunakan untuk mencari hubungan dan membuktikan
hipotesis hubungan dua variabel bila data kedua variabel berbentuk interval atau
ratio, dan sumber data dari dua variabel atau lebih adalah sama.
Berikut ini dikemukakan rumus yang paling sederhana yang dapat
digunakan untuk menghitung koefisien korelasi. Koefisien korelasi untuk populasi
diberi symbol rho () dan untuk sample diberi symbol r, sedang untuk korelasi
ganda diberi simbol R.
Dimana :
rxy = Korelasi antara variabel x dengan y
x = (Xi - X )
y = (Yi - )
2. Korelasi Ganda
Korelasi ganda (multiple correlation) merupakan angka yang menunjukkan
arah dan kuatnya hubungan antara dua variabel secara bersama-sama atau lebih
dengan variabel yang lain. Pemahaman tentang korelasi ganda dapat dilihat
melalui gambar 6 berikut simbol korelasi ganda adalah R.
gambar 6 Jalur hubungan korelasi ganda
X1 = kepemimpinan
X2 = tata ruang kantor
Y = kepuasan kerja
R = korelasi ganda

X1 = kesejahteraan pegawai
X2 = hubungan dengan pimpinan
X3 = pengawasan
Y = efektifitas kerja
Pada bagian ini dikemukakan korelasi ganda (R) untuk dua variabel
independen dan satu dependen. Rumus korelsi ganda dua variabel ditunjukkan
pada rumus berikut :
Dimana :
Ry.x1 x2 = Korelasi antara variabel X1 dengan X2 secara bersama-sama
dengan variabel Y
ryx1 = Korelasi Product Moment antara X1 dengan Y
ryx2 = Korelasi Product Moment antara X2 dengan Y
rx1x2 = Korelasi Product Moment antara X1 dengan X2
interpretasi tingkat hubungan antara dua variabel atau lebih dapat dilihat dalam
tabel di bawah ini
Tabel Pedoman interpretasi terhadap koefisien korelasi
Interval koefisien Tingkat hubungan

0,00 – 0,199
0,20 – 0,399
0,40 – 0,599
0,60 – 0,799
0,80 – 1,000
Sangat rendah
Rendah
Sedang
Kuat
Sangat kuat
Derajat Determinasi
Derajat determinasi adalah derajat yang menunjukan seberapa besar faktor
Variabel bebas mempengaruhi variabel terikat: Koefesien determinasi dapat dicari
dengan menggunakan rumus sebagai berikut:
D = r2
Dimana r adalah koefisien korelasi.
Uji hipotesis asosiatif
Untuk melihat ada tidak hubungan yang signifikan antara variabel bebas dan
variabel terikat perlu adanya uji hipotesis, untuk menguji derajat hubungan
signifikan diperlukan statistik uji t , dengan rumus sebagai berikut:
Adapun hipotesis yang akan di uji adalah
Ho : = 0 ( tidak ada hubungan antara variabel bebas dengan variabel terikat)
Ha : ≠ 0 ( ada hubungan antara variabel bebas dengan variabel terikat)
Kriteria penerimaan Ho jika -ttabel ≤ t hitung ≤ ttabel

Contoh:
Ingin diketahui ada tidak hubungan antara kualitas layanan terhadap penjualan
barang di suatu supermarket, untuk itu dilakukan penelitian terhadap 34
supermaket, dengan data sebagai berikut:
Tabel kualitas layananan supermaket dan penjualan barangNomor Kualitas Layanan (X1) Penjulan Barang (Y1)
1.2.3.4.5.6.7.8.9.19.11.12.13.14.15.16.1`7.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.
54505345486346565256475655525060554547534956575049584852565459474856
167155148146170173149166170174156158150160157177166160155159159172168159150165159162168166177149155160
Dengan alpha 5 % ujilah hipotesis apakah terdapat hubungan yang signifikan
antara kualitas layanan terhadap tingkat jumlah penjualan barang.
Jawab
Untuk menyelesaikan kasus ini diperlukan tabel bantu sebagai berikut:
Tabel bantu perhitungan koefisien korelasi
Nomor X1 Y1 X1Y1 X2 Y2
1.2.3.4.5.6.7.8.9.19.11.12.13.14.15.16.1`7.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.
54505345486346565256475655525060554547534956575049584852565459474856
167155148146170173149166170174156158150160157177166160155159159172168159150165159162168166177149155160
9.0187.7507.8446.5708.160
10.8996.8549.2968.8409.7447.3328.8488.2508.3207.850
10.6209.1307.2007.2858.4277.7919.6329.5767.0507.3509.5707.6328.4249.4088.964
10.4437.0037.4408.960
2.9162.5002.8092.0252.3043.9692.1163.1362.7043.1362.2093.1363.0252.7042.5003.6003.0252.0252.2092.8092.4013.1363.2492.5002.4013.3642.3042.7043.1362.9163.4812.2092.3043.136
27889240252190421316289002992922201275562890030276243362496422500256002464931329275562560024025252812528129584282242528122500272252528126244282242755631329222012402525600
X1 = 1.782
Y1 = 5.485 X1 Y1
=288.380
X12 =
94.098 Y1
2 =887291
= 52.41176
Y = 161.3235
Sx = 4.606436
Sy = 8.583708

Selanjutnya dari nilai – nilai yang ada dalam tabel bantu tersebut masukkan ke
dalam rumus:
= 0,69
Harga r atau koefisien korelasi adalah 0,69, sesuai dengan table interpretasi
tingkat hubungan menunjukan terdapat hubungan yang kuat antara kualitas
layanan terhadap tingkat penjualan barang.
Untuk mengetahui seberapa besar factor layanan mempengaruhi penjualan barang
dapat dilihat dari derajat determinasi yaitu didapat dari kuadrat dari koefisien
korelasi yaitu :
D = r2
=( 0,69)2= 0,4761 atau 47,61% factor penjualan barang dipengaruhi oleh factor
kualitas layanan, selebihnyua dipengaruhi oleh factor lain.
Untuk menguji hipotesi ada tidak hubungan yang signifikan antara kualitas
layanan dan tingkat penjualan perlu di lanjutkan dengan uji t .
Adapun hipotesis yang akan di uji adalah
Ho : = 0 ( tidak ada hubungan antara kualitas layanan terhadap tingkat
penjualan
barang)
Ha : ≠ 0 ( ada hubungan antara kualitas layanan terhadap tingkat penjualan

barang )
uji t
Selanjutnya nilai t hitung dibandingkan dengan nilai t tabel dengan alpha 5% uji
dua pihak dan dk =n-2 =34-2=32, maka diperoleh t tabel =2,037, berarti nilai t
hitung berada di daerah penolakan HO atau penerimaan Ha , dimana terdapat
hubungan yang signifikan antara kualitas layanan terhadap tingkat penjualan.
Untuk menguji kemampuan mahasiswa kerjakan Tes Formatif Analisis Korelasi
Tes Formatif Analisis Korelasi
Petunjuk:Pilihlah jawaban yang paling benar dari soal-soal di bawah iniSoal
1. dilakukan penelitian untuk mengetahui ada tidaknya hubungan antara pendapatan dan pengeluaran. Untuk keperluan tersebut maka dilakukan penelitian terhadap 10 responden yang diambil secara random. Misalkan variabel pendapatan adalah X dan variabel pengeluaran adalah Y , berikut data yang diperoleh ribuan rupiah /bulan:X: 800 900 700 600 700 800 900 600 500 500Y: 300 300 200 200 200 200 300 100 100 100Hipotesis penelitian dari kasus tersebut adalah:a. Ho : terdapat kesamaan antara pendapatan dan pengeluaran Ha : tidak terdapat kesamaan antara pendapatan dan pengeluaranb. Ho : Tidak ada hubungan yang signifikan antara pendapatan dan pengeluaran Ha : terdapat hubungan yang signifikan antara pendapatan dan pengeluaranc. Ho : terdapat perbedaan antara pendapatan dan pengeluaran Ha : tidak terdapat perbedaan antara pendapatan dan pengeluarand. Ho : tidak ada pengaruh yang signifikan antara pendapatan dan pengeluaran Ha : terdapat pengaruh yang signifikan pendapatan dan pengeluaran

e.Ho :ada hubungan yang signifikan antara pendapatan dan pengeluaran Ha : tidak ada hubungan yang signifikan antara pendapatan dan penegluaran
2. dari kasus soal no 1 nilai korelasi product moment yang diperoleh adalaha. 0,9129b. 0,2199c. 0,1299d. 0,9912e. 1,2990
3. berdasarkan tabel interpretasi nilai r maka derajad hubungan dari variabel pendapatan dengan variabel pengeluaran pada soal no 1 adalah
a. positif lemahb. positif kuatc. negatif kuatd. positif sangat kuate. negatif lemah
4. derajat determinasi pada kasus soal no 1 adalaha. 0,38b. 1,8258c. 3,8d. 18,258e. 0,83
5. untuk menguji hipotesis asosiatif perlu dilakukan uji t, nilai t hitung pada kasus soal no 1 adalaha.6,33b. 3,66c. 6,66d . 6,63e. 0,33
6. kesimpulan yang dapat diambil dari uji hipotesis pada kasus soal no 1 adalaha. terima Ha, berarti terdapat kesamaan anatara pendapatan dengan pengeluaranb. terima Ha, berarti ada pengaruh antara pendapatan dan pengeluaranc. terima Ha, berarti terdapat perbedaan antara pendapatan dan pengeluarand. terima Ho, berarti tidak ada hubungan yang signifikan antara pendapatan dan penegluarane. terima Ha, berarti terdapat hubungan yang signifikan antara pendapatan dan pengeluaran
7. untuk meningkatkan jumlah pelanggan, PT Telkomsesal melakukan penelitian untuk melihat ada tidak hubungan antara jumlah marketing dengan jumlah pelanggan.
Untuk itu dilakukan penelitian dengan data sebagai berikut:tahun Jumlah marketing Jumlah pelanggan2001 11 2000

200220032004200520062007200820092010
101314151516161715
200025002500300035002500350035003750
Nilai r product moment adalaha.0, 8b. 1c -1d. 0,787e. -0,787
8. dari nilai r pada soal no 7, maka dapat diketahui bahwa terdapat hubungan yang:a. positif sangat kuatb. positif kuatc. positif sedangd. negatif sangat kuate. negatif kuat
9. dari derajat determinasi diketahui bahwa a. 61,9 % faktor jumlah pelanggan dipengaruhi oleh jumlah marketingb. 100% faktor jumlah pelanggan dipengaruhi oleh jumlah marketingc. 64 % faktor jumlah pelanggan dipengaruhi oleh jumlah marketingd. 61,9 % faktor jumlah marketing dipengaruhi oleh jumlah pelanggane. 100% faktor jumlah marketing dipengaruhi oleh jumlah pelanggan10. Hipotesis yang diterima dari kasus soal no 7 adalaha.terima Ho, berarti tidak ada hubungan yang signifikan antara jumlah marketing dengan jumlah pelangganb. terima Ha, berarti ada hubungan yang signifikan antara jumlah marketing dengan jumlah pelangganc. terima Ho, berarti tidak ada pengaruh yang signifikan antara jumlah marketing dan jumlah pelanggand. terima Ha, berarti ada pengaruh yang signifikan antara jumlah marketing dan jumlah pelanggane. terima Ha, berarti ada kesamaan antara jumlah marketing dan jumlah pelanggan
DAFTAR PUSTAKA

Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta
MODUL PEMBELAJARAN
ANALISIS REGRESI
Tujuan Pembelajaran
Persamaan regresi linier sederhana
membuat prediksi dengan persamaan regresi sederhana
persamaan regresi ganda
membuat prediksi dengan persamaan regresi ganda
Pendahuluan

Analisis regresi adalah analisis stattistik yang dilakukan bila hubungan
dua variabel berupa hubungan kausal atau fungsional. Analisis regresi digunakan
untuk mengetahui bagaimana variabel dependen/kriteria dapat diprediksikan
melalui variabel independent atau predictor, secara individual. Dampak dari
penggunaan analisis regresi dapat digunakan untuk memutuskan apakah naik dan
menurunnya variabel dependen dapat dilakukan melalui menaikkan dan
menurunkan variabel independen.
Dalam modul ini akan dipelajari regresi linier sederhana dan regresi
ganda, setelah mempelajari modul ini diharapkan mahasiswa dapat menentukan:
1. Persamaan regresi linier sederhana
2. membuat prediksi dengan persamaan regresi sederhana
3. persamaan regresi ganda
4. membuat prediksi dengan persamaan regresi ganda
A. Regresi Linier Sederhana
Regresi sederhana didasarkan pada hubungan fungsional ataupun kausal
satu variabel independent dengan satu variabel dependen. Persamaan umum
regresi linier sederhana adalah :
Dimana :
Y = variabel dependen yang diprediksikan.
a = Harga Y bila X = 0 (harga konstan)
b. = Angka arah atau koefisien regresi, yang menunjukkan angka
meningkatan ataupun penurunan variabel dependen yang didasarkan
pada variabel independent. Bila b ( + ) maka naik, dan bila ( - ) maka
terjadi penurunan.
X = Subyek pada variabel independent yang mempunyai nilai tertentu.
Secara teknis harga b merupakan tangent dari (perbandingan) antara
panjang garis variabel dipenden, setelah persamaan regresi ditemukan.

Gambar 1. Garis regresi Y karena pengaruh X, Persamaan
Regresinya Y = 2,0 + 0,5 X
Dimana :
R = Koefisien korelasi product moment antara variabel X dengan variabel Y
Sy = Simpangan baku variabel Y
Sx = Simapangan baku variabel X.
0
1
2
3
4
5
6
7
8
1 2 3 4 5 6 7 8 9 10
X
Y
Y = 2,0 + 0,5 X
a = 2,0
b = 2/4 atau 5/10
b = 2,5 = x/y
Harga b = r
Harga a = Y – bX

Jadi harga b merupakan fungsi dari koefisien korelasi. Bila koefisien
korelasi tinggi, maka harga b juga besar, sebaliknya bila koefisien korelasi rendah
maka harga b juga rendah (kecil). Selain itu bila koefisien korelasi negatif maka
harga jiga negatif, dan sebaliknya bila koefisien positif maka harga b juga positif.
Selain itu harga a dan b dapat dicari dengan rumus berikut :
1. Contoh Regresi Linier Sederhana
Data berikut adalah hasil pengamatan terhadap nilai kualitas layanan (X)
dan nilai rata-rata penjualan barang tertentu tiap bulan. Data kedua variabel
diberikan pada table 1 berikut.
TABEL 1
NILAI KUALITAS LAYANAN DAN
NILAI RATA-RATA PENJUALAN BARANG
Nomor Kualitas Layanan (X1) Penjulan Barang (Y1)
1.
2.
3.
4.
54
50
53
45
167
155
148
146
a =
b =

5.
6.
7.
8.
9.
19.
11.
12.
13.
14.
15.
16.
1`7.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
48
63
46
56
52
56
47
56
55
52
50
60
55
45
47
53
49
56
57
50
49
58
48
52
56
54
59
47
48
56
170
173
149
166
170
174
156
158
150
160
157
177
166
160
155
159
159
172
168
159
150
165
159
162
168
166
177
149
155
160

TABEL 2
TABEL PENOLONG UNTUK MENGHITUNG
PERSAMAAN REGRESI DAN KORELASI SEDERHANA
Nomor X1 Y1 X1Y1 X2 Y2
1.
2.
3.
4.
5.
6.
7.
8.
9.
19.
11.
12.
13.
14.
15.
16.
1`7.
18.
19.
20.
21.
22.
23.
24.
25.
54
50
53
45
48
63
46
56
52
56
47
56
55
52
50
60
55
45
47
53
49
56
57
50
49
167
155
148
146
170
173
149
166
170
174
156
158
150
160
157
177
166
160
155
159
159
172
168
159
150
9.018
7.750
7.844
6.570
8.160
10.899
6.854
9.296
8.840
9.744
7.332
8.848
8.250
8.320
7.850
10.620
9.130
7.200
7.285
8.427
7.791
9.632
9.576
7.050
7.350
2.916
2.500
2.809
2.025
2.304
3.969
2.116
3.136
2.704
3.136
2.209
3.136
3.025
2.704
2.500
3.600
3.025
2.025
2.209
2.809
2.401
3.136
3.249
2.500
2.401
27889
24025
21904
21316
28900
29929
22201
27556
28900
30276
24336
24964
22500
25600
24649
31329
27556
25600
24025
25281
25281
29584
28224
25281
22500

26.
27.
28.
29.
30.
31.
32.
33.
34.
58
48
52
56
54
59
47
48
56
165
159
162
168
166
177
149
155
160
9.570
7.632
8.424
9.408
8.964
10.443
7.003
7.440
8.960
3.364
2.304
2.704
3.136
2.916
3.481
2.209
2.304
3.136
27225
25281
26244
28224
27556
31329
22201
24025
25600
X1 = 1.782 Y1 = 5.485 X1 Y1 =288.380
X12 =
94.098 Y1
2 =887291
= 52.41176 Y = 161.3235Sx = 4.606436 Sy = 8.583708
2. Menghitung harga a dan b dengan rumus
3. Menyusun persamaan regresi
Setelah harga a dan b ditentukan, maka persamaan regresi linier
sederhana dapat disusun. Persamaan regresi nilai layanan dan nilai rata-rata
perjualan barang tertentu tiap bulan adalah seperti berikut :
Persamaan regresi yang telah ditemukan dapat digunakan untuk
melakukan prediksi (ramalan) bagaimana individu dalam variabel dependen akan
terjadi bila individu dalam variabel independent ditetapkan. Misalnya nilai
kualitas layanan = 64, maka nilai rata-rata penjualan adalah :
= 93,85 + 1,29.64 = 176,41

Jadi diperkirakan nilai rata-rata penjualan tiap bulan sebesar 176,41.
Dari persamaan regresi di atas dapat diartikan bahwa, bila nilai kualitas layanan
bertambah 1, maka nilai rata-rata penjualan barang tiap bulan bertambah 1,29 atau
setiap nilai kualitas layanan bertambah 10 maka nilai rata-rata penjualan tiap
bulan akan bertambah sebesar 12,9.
4. Membuat garis regresi
Garis regresi dapat digambar berdasarkan persamaan yang telah
ditemukan adalah :
= 93,85 + 1,29X
Gambar 2 Garis regresi nilai kualitas layanan dan nilai
rata-rata penjualan barang tiap bulan.
Antara nilai kulaitas layanan dengan nilai penjualan tiap bulan dapat
dihitung korelasinya. Korelasi dapat dihitung dengan rumus yang telah diberikan
atau dengan rumus berikut.

5.
Harga-harga yang telah ditemukan dalam dapat dimasukkan dalam rumus di atas
sehingga :
Harga r table untuk taraf kesalahan 5 % dengan n = 34 diperoleh 0,339
dan untuk 1 % = 0,436. Karena harga r hitung lebih besar dari r table baik untuk
kesalahan 5 % maupun 1 % (0,6909 > 0,436 > 0,339), maka dapat disimpulkan
terdapat hubungan yang positif dan signifikan sebesar 0,6909 antara nilai kualitas
layanan dan rata-rata penjualan barang tiap bulan.
Koefisien determinasinya r2 = 0,69092 = 0,4773. Hal ini berarti nilai rata-
rata penjualan barang tiap bulan 47,73 % ditentukan oleh nilai kualitas layanan
yang diberikan, melalui persamaan regresi Y = 93,83 + 1,29 X. Sisanya 52,27 %
ditentukan oleh factor lain.
B. Regresi Ganda
Analisis regresi ganda digunakan oleh peneliti, bila peneliti bermaksud
meramalkan bagaimana keadaan (naik turunnya) variabel dependen (kriterium),
bila dua atau lebih variabel independent sebagai factor predictor dimanipulasi
(dinaik turunkan nilainya). Jadi analisis regresi ganda akan dilakukan bila jumlah
variabel independennya minimal 2.
Persamaan regresi untuk dua prediktor adalah :
Y = a + b1X1 + b2X2
Persamaan regresi untuk tiga predictor adalah :
r =
r =

Y = a + b1X1 + b2X2 + b3X3
Persamaan regresi untuk n predictor adalah :
Y = a + b1X1 + b2X2 + ……. + bnXn
Untuk bias membuat ramalan melalui regresi, maka data setiap variabel
harus tersedia. Selanjutnya berdasarkan data itu peneliti harus dapat menemukan
persamaan melalui perhitungan.
Berikut ini diberikan tiga contoh analisis regresi ganda untuk dua
predictor.
Regresi Ganda Dua Prediktor
Penelitian dilakukan untuk mengetahui pengaruh kemampuan kerja
pegawai dan kepemimpinan direktif terhadap produktivitas kerja pegawai.
Berdasarkan 10 responden yang digunakan sbagai sumber data
penelitian, hasilnya adalah sebagai berikut :
No Reponden X1 X2 Y
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
10
2
4
6
8
7
10
6
7
6
7
3
2
4
6
5
4
3
4
3
23
7
15
17
23
22
3
14
20
19
Untuk dapat meramalkan bagaimana produktivitas kerja pegawai bila
kemampuan pegawai dan kepemimpinan direktif dinaikan atau diturunkan, maka
harus dicari persamaan regresinya terlebih dahulu. Berikut table penolong nya
TABEL 3

TABEL PENOLONG UNTUK MENGHITUNG
PERSAMAAN REGRESI GANDA DUA PREDIKTOR
No. X1 X2 Y X1Y X2Y X1Y2 X12 X2
2
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
10
2
4
6
8
7
10
6
7
6
7
3
2
4
6
5
4
3
4
3
23
7
15
17
23
22
3
14
20
19
230
14
60
102
184
154
40
84
140
114
161
21
30
68
138
110
30
42
80
57
70
6
8
24
48
35
12
18
28
18
100
4
16
36
64
49
16
36
49
36
49
9
4
16
36
25
9
9
16
9
JML 60 40 170 1122 737 267 406 182
Y = produktivitas ; X1 = kemampuan kerja pegawai
X2 = kepemimpinan direktif
Dari table diperoleh :
Y = 170 X1 Y = 737
X1 = 60 X1 X2 = 267
X2 = 40 X12 = 406
X1Y = 1.122 X12 = 182
Untuk menhitung harga-harga a, b1, b2 dapat menggunakan persamaan berikut :
( untuk regresi dua prediktor).
= an + b1 X1 + b2 X2
X1 Y = a X1 + b1 X1 + b2 X1 X2
X2 Y = a X1 + b1 X1 + b2 X2

Bila harga-harga dari data di atas dimasukkan dalam persamaan tersebut maka :
170 = 1- a + 60 b1 + 40 b2 ………. (1)
1.122 = 60 a + 406 b1 +267 b2 ……….. (2)
737 = 40 a + 267 b1 + 182 b2 ……….. (3)
Persamaan (1) dikalikan 6, persamaan (2) dikalikan 1 :
1.20 = 60 a + 360 b1 + 240
1.122 = 60 a + 406 b 1 + 267 _
- 102 = 0 a + -46 b1 + -27
- 102 = -46 b1 – 27 b2 ………….. (4)
Persamaan (1) dikalikan dengan 4, persamaan (3) dikalikan dengan 1 hasilnya
menjadi :
680 = 40 a + 240 b1 + 160 b2
737 = 40 a + 267 b 1 + 182 b2 _
-57 = 0 a + -27 b1 + -22 b2
-57 = -27 b1 -22 b2 ………… (5)
Persamaan (4) dikalikan dengan 27, persamaan (5) dikalikan dengan 46,
hasilnya menjadi :
-2.754 = - 1.242 b1 – 729 b2
-2.622 = -1.242 b 1 – 1.012 b2 _
-132 =0 b1 + 283 b2
B2 = -132 : 283 = - 0,466
Harga b2 dimasukkan dalam salah satu persamaan (4) atau (5). Dalam hal ini
dimasukkan dalam persamaan (4), maka :
- 102 = -46 b1 -27 (-0,466)
- 102 = 46 b1 - -12,582
46 b1 = 114,582
b1 = 2,4909

Harga b1 dan b2 dimasukan dalam persamaan 1, maka :
170 = 10 a + 60 (2,4909) + 40 (-0,466)
170 = 10 a + 149,454 – 18,640
10 a = 170 – 149,454 + 18,640
A = 39,186 : 10 = 3,9186
Jadi :
a = 3,9186
b1 = 2,4909
b2 = -0,466
jadi persamaan regresi ganda linier untuk dua predictor (kemampuan kerja
pegawai, dan kepemimpinan direktif) adalah :
Y = 3,9186 + 2,4909 X1 – 0,466 X2
Dari persamaan itu berarti produktivitas kerja pegawai akan naik, bila
kemampuan pegawai ditingkatkan. Dan akan turun bila kepemimpinan direktif
(otokratis) ditingkatkan. Tetapi koefisien regresi untuk kemampuan pegawai
(2,4909) lebih besar dari pada koefisien regresi untuk kepemimpinan direktif
(diharga mutlak = 0,466) X. jadi bila kemampuan pegawai ditingkatkan sehingga
mendapat nilai 10, maka produktivitasnya adalah :
Y = 3,9186 + 2,4909 . 10 – 0,466 . 10 = 24,1676
Diperkirakan produktivitas kerja pegawai = 24, 1676.
Untuk menguji kemampuan mahasiswa kerjakan Tes Formatif Analisis Regresi
Tes Formatif Analisis Regresi
Petunjuk:Pilihlah jawaban yang paling benar dari soal-soal di bawah ini
Soal1. analisis regresi diperlukan untuk
a. melihat perbedaan rata-rata antara variabel X dengan variabel Y

b. melihat perbedaan proporsi antara variabel X dengan variabel Yc. melihat hubungan antara variabel x dengan variabel yd. melihat seberapa besar faktor variabel X mempengaruhi variabel ye. mengetahui bagaimana variabel dependen dapat diprediksikan
melaui variabel independen2. bentuk umum persamaan regresi sederhana adalaha. Y= a+bxb. A= x+yc. C= a+bd. C2 = a 2 +b2
e. Y= a-x3. nilai yang menunjukan bahwa terjadi hubungan negatif pada persamaan
regresi sederhana adalaha. nilai a pada persamaan regresi bernilai negatifb. nilai b pada persamaan regresi bernilai negatifc. nilai a pada persamaan regresi bernilai positifd. nilai b pada persamaan regresi bernilai positife. nilai a pada persamaan regresi bernilai nol
4. pada tes formatif analisis korelasi soal no 1 persamaan regresinya adalaha.y= 150-0,5xb.y= -150+0,5xc.x= 150-0,5 yd x= -150+0,5ye.y= 0,5-150x
5. dari tes formatif analisis korelasi soal no 1. apabila jumlah pendapatan 1000 maka prediksi pengeluaran adalah
a. -350b. 450c. 350d. 325e. 375
6. dari persamaan regresi soal no 4 dapat diprediksikana. semakin besar pengeluaran maka akan semakin besar pendapatanb. semakin besar pendapatan maka akan semakin besar pengeluaranc. semakin kecil pendapatan maka akan semakin besar pengeluarand. semakin besar pendapatan maka akan semakin kecil pengeluarane. semakin kecil pengeluaran maka akan semakin besar pendapatan
7. pada tes formatif analisis korelasi soal no 5 persamaan regresinya adalaha. y=-394,73+230,263xb. y=394,73-230,263xc. y=230,263+394,73xd. y=-230,263+394,73xe. y=230,263-394,73x
8. PT Angin Ribut akan memasuki pasar global, strategi baru PT tersebut dengan cara meningkatkan pengendalian mutu dan menambah jumlah tenaga marketing untuk meningkatkan omset penjualan. Berikut data

pengendalian mutu, jumlah tenaga marketing dan omset penjualan dalam 8 tahun terakhir:
Tahun Quality controlDalam jutaan rupiah
Tenaga marketing Omset penjualanDalam ratusan juta rupiah
19971998199920002001200220032004200520062007200820092010
555678910111210111110
1110131415151617171716171818
2420232525273030313333333435
Persamaan regresi berganda adalaha. y= 7,615+1,017X1+0,815X2b. y= 7,615+1,017X1-0,815X2c. y=1,017+7,615X1+0,815X2d. y= 0,815+7,615X2+1,017X2e.y= 7,615+0,815X1+1,017X2
9.dari persamaan regresi berganda tersebut dapat diperdiksikan bahwaa. semakin besar nilai Quality control dan jumlah marketing maka akan semakin kecil omsetb. semakin kecil quality control dan jumlah marketing maka akan semakin kecil omsetc. semakin kecil quality control dan jumlah marketing maka akan semakin besar omsetd. semakin besar quality control dan marketing maka akan semakin besar omsete. semakin besar quality control dan semakin kecil marketing maka semakin besar omset10.dari persamaan regresi tersebut, apabila Quality control nya 20 dan jumlah marketing 20 maka prediksi omset yang akan diterima adalaha. 42,5b.45,5c.45,55d. 44,255e. 25,44

DAFTAR PUSTAKA
Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta

MODUL PEMBELAJARAN
ANALISIS VARIAN SATU JALUR
(ANAVA SATU JALUR)
Tujuan Pembelajaran
. menentukan hipotesis uji anava satu jalur
membuat tabel bantu perhitungan anava satu jalur
mencari nilai F hitung anova satu jalur
mencari F hitung anova satu jalur
membuat tabel ringkasan anava satu jalur
membuat suatu kesimpulan anava satu jalur
Pendahuluan
Analisis varian (anava) adalah suatu metode analisis data untuk menguji
perbedaan rata-rata yang terdiri dari lebih dari dua kelompok sampel. Distribusi
yang digunakan adalah distribusi F.
Anova terbagi menjadi dua macam, yaitu:1. Anova satu jalur (anova tunggal, anova satu arah atau one way anova).2. Anova dua jalur (anova ganda, anova dua arah atau two way anova).
Dalam modul ini akan dibahas tentang hipotesis yang menggunakan uji
anava satu jalur, tabel bantu dalam perhitungan anava satu jalur, rumus-rumus
yang diperlukan dalam uji anava satu jalur, tabel ringkasan anava satu jalur

kesimpulan anava satu jalur dan contoh kasus yang menggunakan anava satu
jalur.
Tujuan pembelajaran yang akan dicapai setelah pembelajaran dengan
modul ini adalah:
1. menentukan hipotesis uji anava satu jalur
2. membuat tabel bantu perhitungan anava satu jalur
3. mencari nilai F hitung anova satu jalur
4. mencari F hitung anova satu jalur
5. membuat tabel ringkasan anava satu jalur
6. membuat suatu kesimpulan anava satu jalur
LANGKAH-LANGKAH PENYELESAIAN ANOVA SATU JALUR1) Uji atau asumsikan bahwa data masing-masing dipilih secara acak.
2) Uji atau asumsikan bahwa data masing-masing berdistribusi normal.
3) Uji atau asumsikan bahwa data masing-masing homogeny.
4) Tulis Ha dan H0 dalam bentuk kalimat.
5) Tulis Ha dan H0 dalam bentuk statistic.
6) Buat tabel penolong untu perhitungan anova sebagai berikut:
Tabel penolong Perhitungan Anova satu jalur
Sampel I Sampel II Sampel III Jumlah Total
X1
X11
X12
X1n
.
.
.
X12
X112
X122
X1n2
.
.
.
X2
X21
X22
X2n
.
.
.
X22
X212
X222
X2n2
.
.
.
X3
X31
X32
X3n
.
.
.
X32
X312
X322
X3n2
.
.
.
Xtotal
Xtotal1
Xtotal2
Xtotal n
.
.
.
Xtotal2
Xtotal 12
Xtotal 22
Xtotal n2
.
.
.

7) Hitung jumlah kuadrat total:
8) Hitung jumlah kuadrat antarkelompok dengan rumus:
9) Hitung jumlah kuadrat dalam kelompok dengan rumus:
10) Hitung Rata – rata kuadrat antar dengan rumus:
, m = jumlah kelompok sampel
11) Hitung Rata – rata Kuadrat dalam dengan rumus:
, N = Jumlah seluruh anggota sampel
12) Hitung nilai F hitung dengan rumus:
13) Bandingkan F hitung dengan F tabel, dimana dk pembilang = m-1 dan dk
penyebut
N- m dengan alpha yang ditentukan.
14) Buat tabel ringkasan Anova. Selanjutnya buat suatu kesimpulan.
Sumber
variasi
dk Jumlah
Kuadrat
RK Fh F tabel Keputusa
n
Total N-1 JK total Dk pembilang=m-
1
Dk penyebut=N-m
Terima HaAntar
Kelompok
m-
1
JK antar RK antar
Dalam N- JK dalam RK

kelompok m dalam Alpha 5 % atau
1 %
15) Apabila terima Ha maka uji dilanjutkan ke Uji lanjut untuk melihat
dimana letak perbedaan tersebut, uji lanjut akan dibahas pada modul
selanjutnya.
Contoh
Ingin diketahui ada tidak perbedaan yang signifikan pengeluaran /bulan
antara PNS, Pedagang dan Petani. Untuk menguji hipotesis tersebut dilakukan
penelitian terhadap Ketiga kelompok sample tersebut, dengan data sebagai
berikut:
TABEL 5
Pengeluaran /bulanPengeluaran perbulan dalam ratusan
ribu rupiahPNS Petani Pedagang
Data yang dihasilkan
121310151314101213141310131015
131512181517182014161816151316
181814201519202118171719161714
Dengan alpha 5 % ujilah hipotesis tersebut:
Jawab:

Langkah-langkah yang harus dikerjakan:
1) Uji atau asumsikan bahwa data masing-masing dipilih secara acak.
2) Uji atau asumsikan bahwa data masing-masing berdistribusi normal.
3) Uji atau asumsikan bahwa data masing-masing homogen.
4) Tulis Ha dan H0 dalam bentuk kalimat.
Ho : Tidak Terdapat perbedaan yang signifikan antara pengeluaran
perbulan PNS, Petani dan Pedagang
Ha : Terdapat perbedaan yang signifikan antara pengeluaran perbulan
PNS, Petani dan Pedagang
5) Hipotesis statistiknya.
H0 : µA = µB = µC
Ha : salah satu ada yang ≠
6) Buat tabel penolong untu perhitungan anova satu arah sebagai berikut:
Tabel penolong Perhitungan Anova satu jalur
NoPNS(X1) X1
2 Petani(x2) X22 Pedagang(
x3)X3
2
X totalXtotal2
1 12 144 13 169 18 324 43 6372 13 169 15 225 18 324 46 7183 10 100 12 144 14 196 36 4404 15 225 18 324 20 400 53 9495 13 169 15 225 15 225 43 6196 14 196 17 289 19 361 50 8467 10 100 18 324 20 400 48 8248 12 144 20 400 21 441 53 9859 13 169 14 196 18 324 45 689
10 14 196 16 256 17 289 47 74111 13 169 18 324 17 289 48 78212 10 100 16 256 19 361 45 71713 13 169 15 225 16 256 44 65014 10 100 13 169 17 289 40 55815 15 225 16 256 14 196 45 677
total 187 2375 236 3782 263 4675 686 10832

7. Hitung jumlah kuadrat total:
8.Hitung jumlah kuadrat antarkelompok dengan rumus:
9.Hitung jumlah kuadrat dalam kelompok dengan rumus:
10. Hitung Rata – rata kuadrat antar dengan rumus:
, m = jumlah kelompok sampel
11. Hitung Rata – rata Kuadrat dalam dengan rumus:
, N = Jumlah seluruh anggota
sampel
12. Hitung nilai F hitung dengan rumus:
13. Bandingkan F hitung dengan F tabel, dimana dk pembilang = m-1 dan dk
penyebut N-m dengan alpha yang ditentukan.
14. Buat tabel ringkasan Anova. Selanjutnya buat suatu kesimpulan.
Sumber
variasi
dk Jumlah
Kuadrat
RK Fh F tabel Keputusan
Total 44 374,31 - 23,75 Dk
pembilang=m-1
Dk penyebut=N-
m
Terima HaAntar
Kelompok
2 198,58 99,29
Dalam 42 175,73 4,18

kelompok Alpha 5 % =3,22
15. Jadi kesimpulan yang diambil adalah terdapat perbedaan rata-rata pengeluaran
/bulan antara PNS, pedagang dan petani. Untuk mengetahui yang mana berbeda
maka harus dilanjutkan dengan uji lanjut yaitu uji t, uji Tukey atau uji Schefy.
Untuk menguji kemampuan mahasiswa kerjakan Tes Formatif Anova Satu jalur
Tes Formatif Anova satu jalur
Petunjuk:Pilihlah jawaban yang paling benar dari soal-soal di bawah iniSoal1.untuk meningkatkan disiplin kerja pegawai di suatu instansi pemerintah dilakukan penelitian terhadap pegawai berdasarkan jumlah absen pegawai selama setahun . penelitian dilakukan terhadap pegawai golongan II , III dan Golongan IV. Diperoleh data sebagai berikut:no Absensi pegawai
Golongan II Golongan III Golongan IV12345678910111213141516
107954793415101110234
34378101191671237987
151110989659810123478
Hipotesis nol dari kasus di atas adalah:a. terdapat kesamaan absensi kehadiran pegawai golongan I,II dan IIIb. tidak terdapat kesamaan absensi kehadiran pegawai golongan I,II dan III

c. apakah terdapat kesamaan absensi kehadiran pegawai golongan I,II dan IIId. apakah tidak terdapat kesamaan absensi kehadiran pegawai golongan I,II
dan IIIe. paling tidak terdapat satu golongan memiliki perbedaan absensi kehadiran
2. dari soal nomor satu hipotesis alternatif penelitian adalah:a. terdapat kesamaan absensi kehadiran pegawai golongan I,II dan IIIb. tidak terdapat kesamaan absensi kehadiran pegawai golongan I,II dan IIIc. apakah terdapat kesamaan absensi kehadiran pegawai golongan I,II dan IIId. apakah tidak terdapat kesamaan absensi kehadiran pegawai golongan I,II
dan IIIe. paling tidak terdapat satu golongan memiliki perbedaan absensi kehadiran
3. Hipotesis statistik soal no 1 adalah:a. H0 : µA = µB ≠ µC
Ha : salah satu ada yang ≠
b. H0 : µA = µB = µC
Ha : salah satu ada yang ≠
c. H0 : µA = µB = µC
Ha : µA≠ µB ≠ µC
d. H0 : µA≠ µB ≠ µC
Ha : µA = µB = µC
e. H0 : µA = µB = µC
Ha : salah satu ada yang =
4. berdasarkan soal no 1. tabel ringkasan anova satu jalur dengan alpha 5 % adalah:
a.sumber variasi dk JK RK Fh Ftabeltotal 47 543,4792
3,204317
5%0,585841
antar kelompok 2 529,6875 11,77083
dalam kelompok 45 13,79167 6,895833
b.sumber variasi dk JK RK Fh Ftabeltotal 47 543,4792
1,706985%3,204317antar kelompok 2 529,6875 11,77083

dalam kelompok 45 13,79167 6,895833
c.sumber variasi dk JK RK Fh Ftabeltotal 47 13,79167
0,585841
5%3,204317
antar kelompok 2 529,6875 11,77083dalam kelompok 45 543,4792 6,895833
dsumber variasi dk JK RK Fh Ftabeltotal 47 543,4792
0,585841
5%3,204317
antar kelompok 2 529,6875 11,77083dalam kelompok 45 13,79167 6,895833
e.sumber variasi dk JK RK Fh Ftabeltotal 47 529,6875
0,585841
5%3,204317
antar kelompok 2 543,4792 11,77083dalam kelompok 45 13,79167 6,895833
5. Kesimpulan yang dapat diambil dari perhitungan anova pada soal no 1 adalah:a. Tolak Ho, berarti tidak terdapat kesamaan absensi kehadiran pegawai
golongan I,II dan IIIb. Terimah Ho, berarti apakah terdapat kesamaan absensi kehadiran pegawai
golongan I,II dan IIIc. Tolak Ho, berarti apakah tidak terdapat kesamaan absensi kehadiran
pegawai golongan I,II dan IIId. Tolak Ho, berarti paling tidak terdapat satu golongan memiliki perbedaan
absensi kehadirane. Terimah Ho, berarti terdapat kesamaan absensi kehadiran pegawai
golongan I,II dan III
6. untuk mengetahui seberapa besar pengaruh gaya kepemimpinan terhadap efektifitas kerja pegawai , dilakukan penelitian terhadap pegawai berdasakan tiga tipe kepemimpinan yaitu direktif, supportif dan partisipatif, diperoleh data sebagai berikut:No Gaya Kepemimpinan
direktif supportif partisipatif12345
7671566770
7065576056
7577745976

6789101112131415
77456063606156597466
71476760595760547263
73786275746075707165
Hipotesis nol dari kasus di atas adalah:a. terdapat kesamaan produktifitas pegawai berdasarkan gaya kepemimpinan
tipe direktif, supportif dan partisipatifb. tidak terdapat kesamaan produktifitas pegawai berdasarkan gaya
kepemimpinan tipe direktif, supportif dan partisipatifc. apakah terdapat kesamaan produktifitas pegawai berdasarkan gaya
kepemimpinan tipe direktif, supportif dan partisipatifd. apakah tidak terdapat kesamaan produktifitas pegawai berdasarkan gaya
kepemimpinan tipe direktif, supportif dan partisipatife. paling tidak terdapat satu produktifitas pegawai berdasarkan gaya
kepemimpinan tipe direktif, supportif dan partisipatif
7. dari soal nomor 5 hipotesis alternatif penelitian adalah:a. paling tidak terdapat salah satu perbedaan produktifitas kerja pegawai
berdasarkan tipoe kepemimpinanb. tidak terdapat kesamaan produktifitas pegawai berdasarkan gaya
kepemimpinan tipe direktif, supportif dan partisipatifc. apakah terdapat kesamaan produktifitas pegawai berdasarkan gaya
kepemimpinan tipe direktif, supportif dan partisipatifd. apakah tidak terdapat kesamaan produktifitas pegawai berdasarkan gaya
kepemimpinan tipe direktif, supportif dan partisipatife. terdapat kesamaan produktifitas pegawai berdasarkan gaya kepemimpinan
tipe direktif, supportif dan partisipatif
8. Hipotesis statistik soal no 5 adalah:a. H0 : µA = µB ≠ µC
Ha : salah satu ada yang ≠
b. H0 : µA = µB = µC
Ha : salah satu ada yang ≠
c. H0 : µA = µB = µC
Ha : µA≠ µB ≠ µC

d. H0 : µA≠ µB ≠ µC
Ha : µA = µB = µC
e. H0 : µA = µB = µC
Ha : salah satu ada yang =
9. berdasarkan soal no 5. tabel ringkasan anova dengan alpha 5 % adalah:sumber variasi dk JK RK Fh Ftabeltotal 44 3046,8 antar kelompok 42 2296,267 54,67302 0,145691 3,219942dalam kelompok 2 750,5333 375,2667
sumber variasi dk JK RK Fh Ftabeltotal 44 3046,8 antar kelompok 42 2296,267 54,67302 6,863837 3,219942dalam kelompok 2 750,5333 375,2667
sumber variasi dk JK RK Fh Ftabeltotal 44 3046,8 antar kelompok 42 2296,267 375,2667 6,863837 3,219942dalam kelompok 2 750,5333 54,67302
sumber variasi dk JK RK Fh Ftabeltotal 44 2296,267 antar kelompok 42 3046,8 54,67302 6,863837 3,219942dalam kelompok 2 750,5333 375,2667
sumber variasi dk JK RK Fh Ftabeltotal 44 3046,8 3,219942 antar kelompok 42 2296,267 54,67302 6,863837dalam kelompok 2 750,5333 375,2667
9. tabel ringkasan anova satu jalur pada soal no 5. dengan alpha 1 % adalah:a.sumber variasi dk JK RK Fh Ftabeltotal 44 3046,8 antar kelompok 42 2296,267 375,2667 0,145691 5,1491dalam kelompok 2 750,5333 54,67302
b.sumber variasi dk JK RK Fh Ftabeltotal 44 3046,8

antar kelompok 42 2296,267 375,2667 6,863837 5,1491dalam kelompok 2 750,5333 54,67302
c.sumber variasi dk JK RK Fh Ftabeltotal 44 3046,8 3,219942 antar kelompok 42 2296,267 375,2667 6,863837dalam kelompok 2 750,5333 54,67302
d.sumber variasi dk JK RK Fh Ftabeltotal 44 3046,8 54,67302 antar kelompok 42 2296,267 375,2667 6,863837 5,1491dalam kelompok 2 750,5333
e.sumber variasi dk JK RK Fh Ftabeltotal 44 3046,8 antar kelompok 42 2296,267 375,2667 6,863837 3,219942dalam kelompok 2 750,5333 54,67302
10. Kesimpulan yang dapat diambil dari perhitungan anova satu jalur pada soal no 5 dengan alpha 5 % dan 1 % adalah:
a. Terima Ha, berarti paling tidak terdapat salah satu perbedaan produktifitas kerja pegawai berdasarkan tipoe kepemimpinan
b. Terima Ha, berarti tidak terdapat kesamaan produktifitas pegawai berdasarkan gaya kepemimpinan tipe direktif, supportif dan partisipatif
c. Terima Ha, berarti apakah terdapat kesamaan produktifitas pegawai berdasarkan gaya kepemimpinan tipe direktif, supportif dan partisipatif
d. Terima Ho berarti apakah tidak terdapat kesamaan produktifitas pegawai berdasarkan gaya kepemimpinan tipe direktif, supportif dan partisipatif
e. Terima Ho, berarti terdapat kesamaan produktifitas pegawai berdasarkan gaya kepemimpinan tipe direktif, supportif dan partisipatif
DAFTAR PUSTAKA
Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito

Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta
MODUL PEMBELAJARANANALISIS VARIAN DUA JALUR
ANAVA DUA JALUR
Tujuan Pembelajaran menentukan hipotesis uji anava dua jalur
membuat tabel bantu perhitungan anava dua jalur
mencari nilai F hitung anava dua jalur
mencari F tabel anava dua jalur
membuat tabel ringkasan anava dua jalur
membuat suatu kesimpulan anava dua jalur
Analisis varian dua jalur merupakan teknik statistik infrensial parametris yang
digunakan untuk menguji hipotesis komparatif lebih dari dua sampel (k sampel,
k≥2) secara serempak bila setiap sampel terdiri atas dua kategori atau lebih.
Dalam modul ini akan dibahas tentang hipotesis yang menggunakan uji anava dua
jalur, tabel bantu dalam perhitungan anava dua jalur, rumus-rumus yang
diperlukan dalam uji anava dua jalur, tabel ringkasan anava dua jalur , kesimpulan
anava dua jalur dan contoh kasus yang menggunakan anava dua jalur.
Tujuan pembelajaran yang akan dicapai setelah pembelajaran dengan
modul ini adalah:
1. menentukan hipotesis uji anava dua jalur
2. membuat tabel bantu perhitungan anava dua jalur
3. mencari nilai F hitung anava dua jalur
4. mencari F tabel anava dua jalur
5. membuat tabel ringkasan anava dua jalur
6. membuat suatu kesimpulan anava dua jalur

LANGKAH-LANGKAH PENYELESAIAN ANOVA DUA JALUR
11) Uji atau asumsikan bahwa data masing-masing dipilih secara acak.
12) Uji atau asumsikan bahwa data masing-masing berdistribusi normal.
13) Uji atau asumsikan bahwa data masing-masing homogeny.
14) Tulis Ha dan H0 dalam bentuk kalimat.
15) Tulis Ha dan H0 dalam bentuk statistic.
16) Buat tabel penolong untuK perhitungan anova sebagai berikut:
Tabel penolong perhitungan anova dua jalur
Variable Sample I Sample II Sample
III
Total
X1 X12 X2 X2
2 X3 X32 Xtotal Xtotal
2
Kategori
I
X1
X11
X12
.
.
.
X1n
X12
X112
X122
.
.
.
X1n2
X2
X21
X22
.
.
.
X2n
X22
X212
X222
.
.
.
X2n2
X3
X31
X32
.
.
.
X3n
X32
X312
X322
.
.
.
X3n2
Xtotal
Xtotal1
Xtotal2
.
.
.
Xtotal n
Xtotal2
Xtotal 12
Xtotal 22
.
.
.
Xtotal n2
Total
Kategori
I
∑ X1
∑ X12 ∑ X2 ∑ X2
2 ∑ X3 ∑ X32 ∑
Xtotal
∑
Xtotal2
Kategori
II
X1
X11
X12
X112
X2
X21
X22
X212
X3
X31
X32
X312
Xtotal
Xtotal1
Xtotal2
Xtotal 12
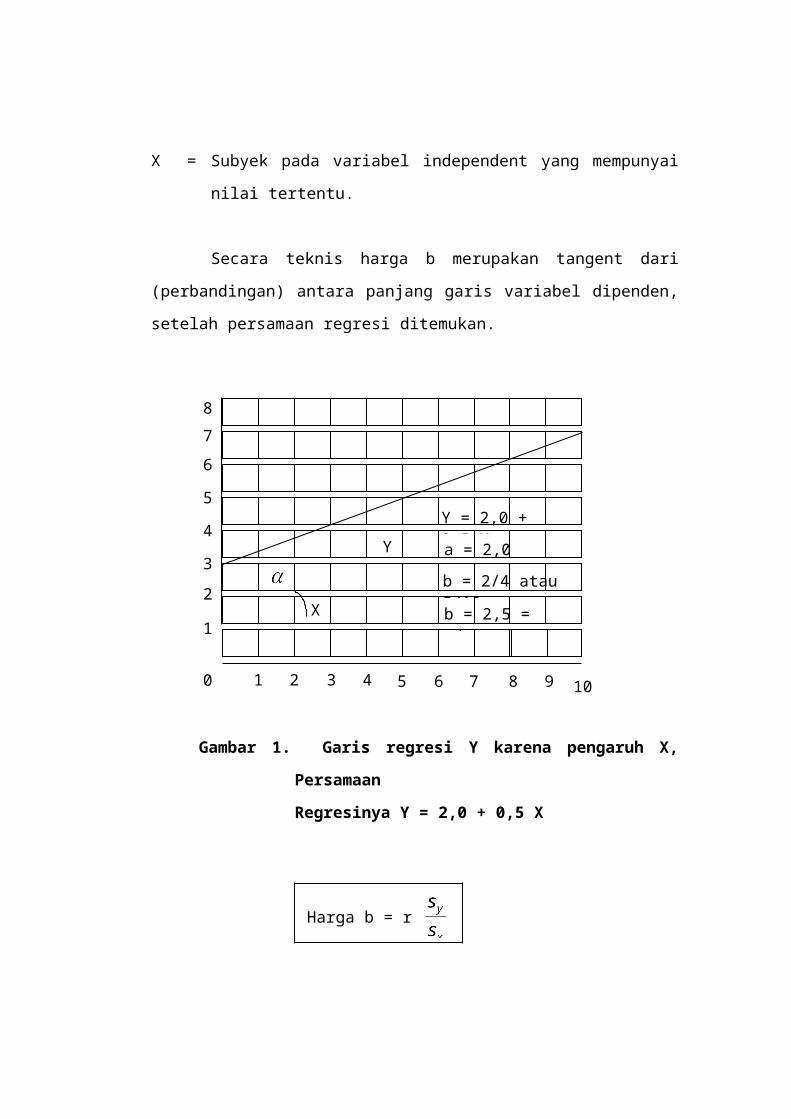
X12
.
.
.
X1n
X122
.
.
.
X1n2
X22
.
.
.
X2n
X222
.
.
.
X2n2
X32
.
.
.
X3n
X322
.
.
.
X3n2
Xtotal2
.
.
.
Xtotal n
Xtotal 22
.
.
.
Xtotal n2
Total
kategoriII
∑ X1
∑ X12 ∑ X2 ∑ X2
2 ∑ X3 ∑ X32 ∑
Xtotal
∑
Xtotal2
Jumlah
total
∑
X1Total ∑
X1total2
∑
X2total
∑
X2total2
∑
X3total
∑
X3total2
∑
Xtotal
∑
Xtotal2
7. Hitung JK total dengan rumus
8. hitung jumlah kuadrat kolom dengan rumus
9. Hitung jumlah kuadrad baris dengan rumus:
10. hitung jumlah kuadrad interaksi, dengan rumus:
11. Hitung Jumlah Kuadrad dalam dengan rumus:
12. Hitung dk untuk

a. dk kolom= k-1
b. dk baris= b-1
c. dk interaksi=dk kolom x dk baris
d. dk dalam= N-kb
e. dk total = N-1
13. Hitung rata-rata kuadrat, dengan rumus:
a. RKKolom = JKkolom: dk kolom
b. RKbaris = JKbaris: dk baris
c. RKint = JKint: dk interaksi
d. RKdalam = JKdalam: dk dalam
14. Hitung harga F hitung kolom, F hitung baris, dan F hitung Interaksi dengan
cara membagi masing – masing RK dengan RK dalam:
a. Fh kolom = RKKolom : RKdalam
b. Fh baris = RKbaris : RKdalam
c. Fh inter= RKinter : RKdalam
15. Bandingkan dengan F tabel
a. F tabel untuk kolom dicari berdasarkan dk antar kolom (pembilang) , dan dk
dalam (penyebut dengan alpha sesuai dengan yang ditentukan.
b. F tabel untuk baris dicari berdasarkan dk antar baris (pembilang), dan dk dalam
(penyebut) dengan alpha sesuai dengan yang ditentukan.
c. F tabel untuk interaksi dicari berdasarkan dk interaksi baris dan kolom
(pembilang), dan dk dalam (penyebut) dengan alpha sesuai dengan yang
ditentukan.
16. Buat tabel ringkasan Anova dua jalur
Tabel Ringkasan Anova dua jalan
Sumber
Variasi
dk Jumlah
Kuadrad
Rata-rata
kuadrad
Fh F tabel

Antar kolom Kolom -1 JK kolom RK kolom Fh kolom F tabel
kolom
Antar baris Baris -1 JK baris RK baris Fh baris F tabel
baris
Interaksi(baris
kolom)
Kolomx
baris
JK
interaksi
RK
interaksi
Fh
Interaksi
F tabel
interaksi
dalam Total-
kolom
xbaris
JK dalam RK dalam
total N-1 JK Total
17. Buat kesimpulan dengan cara membandingkan antara F hitung masing –
masing dengan F tabel masing- masing: kriteria penolakan Ho jika F hitung lebih
besar daripada F tabel. Apabila terima Ha maka uji harus dilanjutkan dengan uji
lanjut yaitu uji t, uji Tukey dan Uji Scefy yang akan dibahas pada modul
pembelajaran uji lanjut.
Contoh.
Dilakukan penelitian untuk mengetahui ada tidaknya perbedaan prestasi kerja
pegawai berdasarkan jenjang pendidikan DIII, S1, S2. pegawai yang diteliti
dikelompokan berdasarkan golongan III dan golongan IV. Dengan data sebagai
berikut:
Gol Prestasi Prestasi Prestasi
kerja
pegawai
lulusan
DIII
kerja
pegawai
lulusan
S1
kerja
pegawai
lulusan
S2
X1 X2 X3
Pegawai
gol III
9
5
7
8
9
7
6
6
5
6
8
5
7
8
7
5
6
7
8
7
6
Pegawai
gol Iv
7
6
7
8
5
6
8
9
6
7
8
5
6
7
5
7
9
9
8
7
8
LANGKAH-LANGKAH PENYELESAIAN ANOVA DUA JALUR
1. Uji atau asumsikan bahwa data masing-masing dipilih secara acak.
2. Uji atau asumsikan bahwa data masing-masing berdistribusi normal.
3. Uji atau asumsikan bahwa data masing-masing homogeny.
4. Tulis Ha dan H0 dalam bentuk kalimat.
a. Ho: tidak terdapat perbedaan prestasi kerja pegawai berdasarkan
jenjang pendidikan
Ha: terdapat perbedaan prestasi kerja pegawai berdasarkan
jenjang pendidikan
b. Ho: tidak terdapat perbedaan prestasi kerja pegawai berdasarkan
golongan kerja
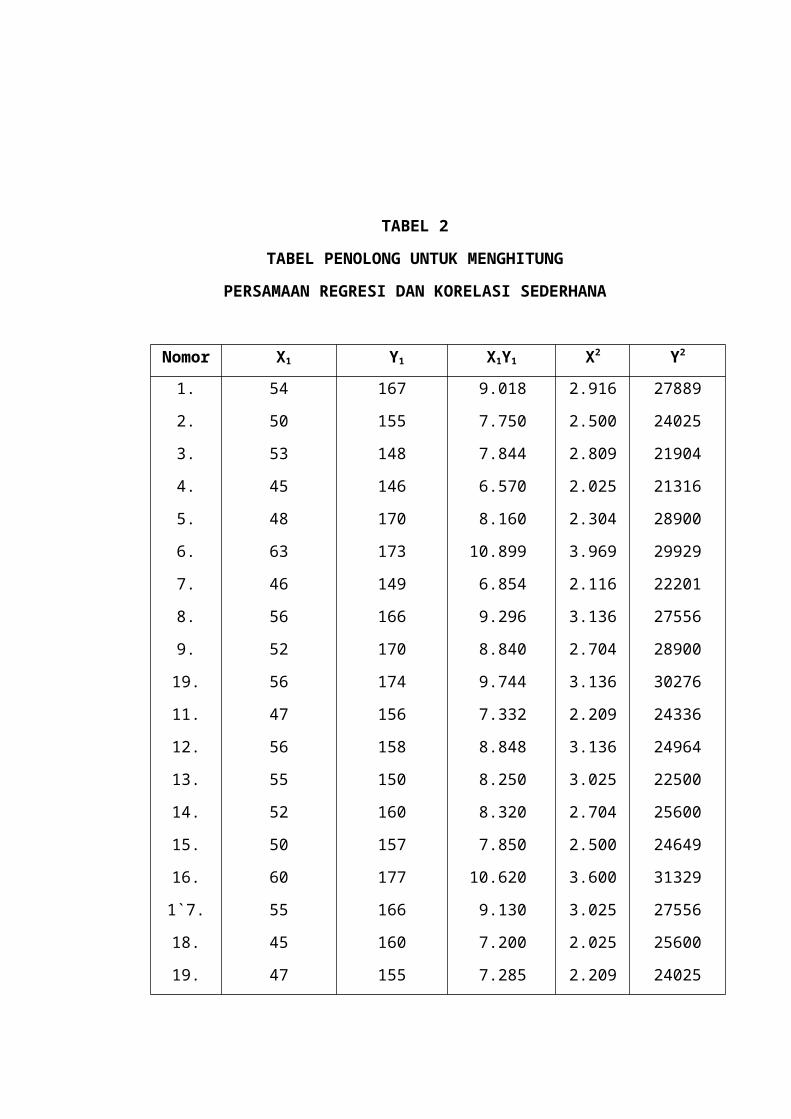
Ha: terdapat perbedaan prestasi kerja pegawai berdasarkan
golongan kerja
c. Ho: Tidak terdapat interaksi antara prestasi kerja pegawai
berdasarkan jenjang pendidikan dengan prestasi kerja
berdasarkan golongan
Ha: terdapat interaksi antara prestasi kerja pegawai
berdasarkan jenjang pendidikan dengan prestasi kerja
berdasarkan golongan
5. Tulis Ha dan H0 dalam bentuk statistic.
a. Ho:μk1 = μk2 = μk3
Ha: μk1 = μk2 ≠μk3
b. H0: μb1 = μb2
Ha: μb1 ≠ μb2
c. Ho: μk1b1 = μk1b2 = μk2b1 = μk2b2 = μk3b1 = μk3b2
Ha: μk1b1 = μk1b2 = μk2b1 = μk2b2 = μk3b1 ≠ μk3b2
6. Buat tabel penolong untuK perhitungan anova sebagai berikut:
Tabel penolong perhitungan anova dua jalur
Gol Prestasi
kerja
pegawai
lulusan
DIII
Prestasi
kerja
pegawai
lulusan
S1
Prestasi
kerja
pegawai
lulusan
S2
Jumlah
Total
X1 X12 X2 X2
2 X3 X32 Xtotal Xtotal
2
Pegawai
gol III
9
5
7
8
9
7
81
25
49
64
81
49
6
5
6
8
5
7
36
25
36
64
25
49
7
5
6
7
8
7
49
25
36
49
64
49
22
15
19
23
22
21
484
225
361
529
484
441

6 36 8 64 6 36 20 400
Jumlah
bag 1
51 385 45 299 46 308 142 2924
Pegawai
gol Iv
7
6
7
8
5
6
8
49
36
49
64
25
36
64
9
6
7
8
5
6
7
81
36
49
64
25
36
49
5
7
9
9
8
7
8
25
49
81
81
64
49
64
21
19
23
25
18
19
23
441
361
529
625
324
361
529
Jumlah
bag 2
47 323 48 340 53 413 148 3170
Jumlah
total
98 708 93 639 99 721 290 6094
7. Hitung JK total dengan rumus
8. hitung jumlah kuadrat kolom dengan rumus
9. Hitung jumlah kuadrad baris dengan rumus:

10. hitung jumlah kuadrad interaksi, dengan rumus:
11. Hitung Jumlah Kuadrad dalam dengan rumus:
12. Hitung dk untuk
a. dk kolom= k-1 = 3-1=2
b. dk baris= b-1=2-1=1
c. dk interaksi=dk kolom x dk baris= 2x 1=2
d. dk dalam= N-kb = 42-6=36
e. dk total = N-1 =42-1=41
13. Hitung rata-rata kuadrat, dengan rumus:
a. RKKolom = JKkolom: dk kolom =1,5:2= 0,75
b. RKbaris = JKbaris: dk baris= 0,84: 1= 0,84
c. RKint = JKint: dk interaksi =4,5:2=2,25
d. RKdalam = JKdalam: dk dalam =58,78:36=1,63
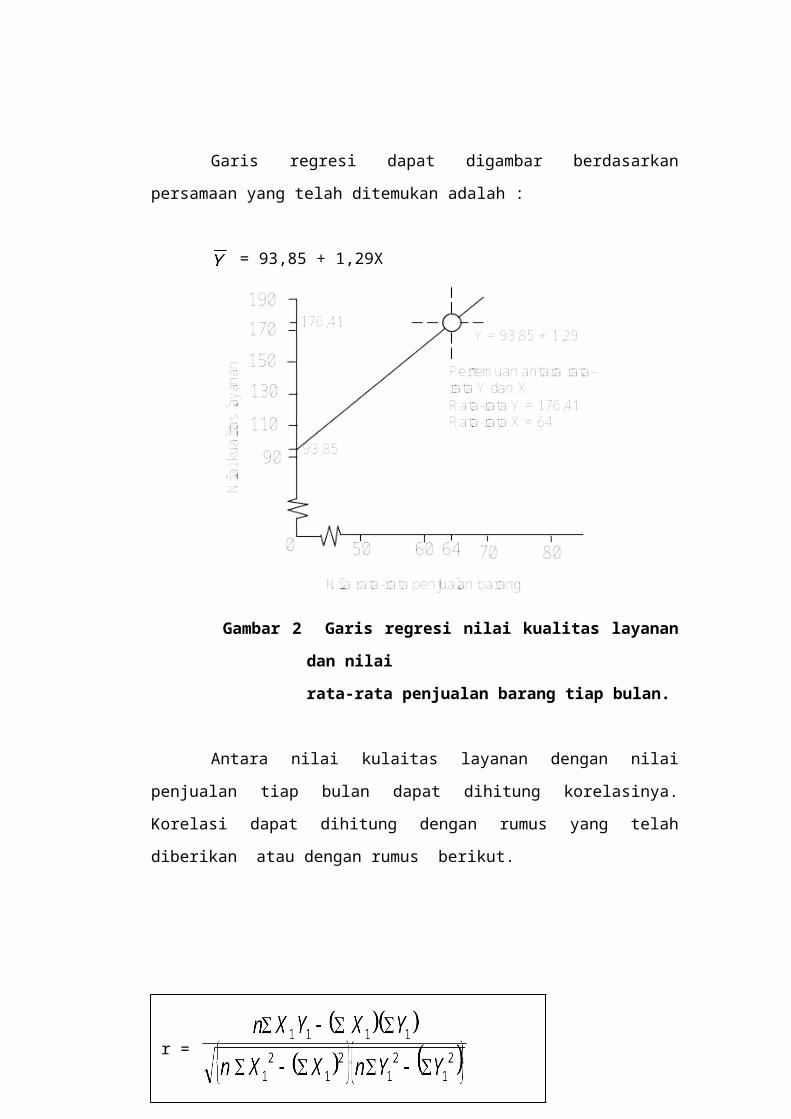
14. Hitung harga F hitung kolom, F hitung baris, dan F hitung Interaksi dengan
cara membagi masing – masing RK dengan RK dalam:
a. Fh kolom = RKKolom : RKdalam= 0,75:1,63= 0,46
b. Fh baris = RKbaris : RKdalam= 0,84:1,63=0,51
c. Fh inter= RKinter : RKdalam = 2,25: 1,63=1,38
15. Bandingkan dengan F tabel
a. F tabel untuk kolom dicari berdasarkan dk antar kolom (pembilang) , dan dk
dalam (penyebut dengan alpha sesuai dengan yang ditentukan. 3,26
b. F tabel untuk baris dicari berdasarkan dk antar baris (pembilang), dan dk dalam
(penyebut) dengan alpha sesuai dengan yang ditentukan. 4,11
c. F tabel untuk interaksi dicari berdasarkan dk interaksi baris dan kolom
(pembilang), dan dk dalam (penyebut) dengan alpha sesuai dengan yang
ditentukan. 3,26
16. Buat tabel ringkasan Anova dua jalur
Tabel Ringkasan Anova dua jalan
Sumber Variasi
dk Jumlah Kuadrad
Rata-rata kuadrad
Fh F tabel
Antar kolom 2 1,5 0,75 0,46 3,26
Antar baris 1 0,84 0,84 0,51 4,11
Interaksi(baris
kolom)
2 4,5 2,25 1,38 3,26
dalam 36 58,78 1,63
total 41 65,62
17. Buat kesimpulan dengan cara membandingkan antara F hitung masing –
masing dengan F tabel masing- masing: kriteria penolakan Ho jika F hitung lebih
besar daripada F tabel. Apabila terima Ha maka uji harus dilanjutkan dengan uji.
Dikarenakan harga Fhitung jauh lebih kecil dari F tabel maka kesimpulan yang
dapat diambil adalah menerima HO.

Untuk menguji kemampuan mahasiswa kerjakan Tes Formatif Anova Dua jalur
Tes Formatif Anova dua jalur
Petunjuk:Pilihlah jawaban yang paling benar dari soal-soal di bawah iniSoal1. .untuk meningkatkan disiplin kerja pegawai di suatu instansi pemerintah dilakukan penelitian terhadap pegawai berdasarkan jumlah absen pegawai selama setahun . penelitian dilakukan terhadap pegawai golongan II , III dan Golongan IV berdasarkan jenis kelamin perempuan dan laki - laki. Diperoleh data sebagai berikut:Jenis kelamin No responden Golongan pegawai
Golongan II Golongan III Gololongan IV
Laki-laki 12345678910
107954793415
3437810119167
1511109896598
Perempuan 12345678910
11898710118713
54271113971211
151110989751013
Hipotesis alternatif penelitian di atas adalah:a. paling tidak terdapat salah satu perbedaan rata-rata disiplin kerja pegawai
golongan II, III dan IV berdasarkan jenis kelamin perempuan dan laki-laki

b. terdapat kesamaan rata-rata disiplin kerja pegawai golongan II, III dan IV berdasarkan jenis kelamin perempuan dan laki-laki
c. tidak ada perbedaan rata-rata disiplin kerja pegawai golongan II, III dan IV berdasarkan jenis kelamin perempuan dan laki-laki
d. terdapat hubungan rata-rata disiplin kerja pegawai golongan II, III dan IV berdasarkan jenis kelamin perempuan dan laki-laki
e. tidak ada hubungan rata-rata disiplin kerja pegawai golongan II, III dan IV berdasarkan jenis kelamin perempuan dan laki-laki
2. nilai F hitung antar kolom pada soal no 1 adalaha.53,1559b-50,656c-51,156d.51,156e.50,656
3. nilai F hitung antar baris pada soal no 1 adalaha.53,1559b-50,656c-51,156d.51,156e.50,656
4. nilai F hitung interaksi baris dan kolom pada soal no 1 adalaha.53,1559b-50,656c-51,156d.51,156e.50,656
5. salah satu kesimpulan yang dapat diambil dari kasus di atas adalaha. terima Ho tidak ada perbedaan rata-rata disiplin kerja pegawai berdasarkan golongan II,III dan golongan IVb. terima Ha paling tidak terdapat salah satu perbedaan rata –rata disiplin kerja pegawai berdasarkan golongan II,III, IVc. terima Ha terdapat perbedaan rata –rata disiplin kerja pegawai laki-laki dengan pegawai perempuand. terima Ho , tidak terdapat perbedaan rata-rata disiplin kerja pegawai golongan II, III dan IV berdasarkan jenis kelamin perempuan dan laki-lakie.terima Ho, tidak ada hubungan antara disiplin kerja pegawai golongan II, III dan IV
6. ingin diketahui ada tidak pengaruh program kerja baru terhadap produktivitas kerja pegawai berdasarkan tingkat pendidikan dan masa kerja, berikut data hasil penelitianMasa kerja/ lulusan
DIII(x1) x12
S1 (X2) x22 x total Xtotal2
20 400 44 1936 64 4096<5 tahun 25 625 45 2025 70 4900 30 900 50 2500 80 6400 45 2025 55 3025 100 10000 35 1225 53 2809 88 7744 30 900 44 1936 74 5476 40 1600 45 2025 85 7225 40 1600 30 900 70 4900 40 1600 35 1225 75 5625 34 1156 30 900 64 4096 40 1600 27 729 67 4489 20 400 35 1225 55 3025total 399 14031 493 21235 892 795664 >5tahun 45 2025 35 1225 80 6400 60 3600 27 729 87 7569 65 4225 65 4225 130 16900
67 4489 55 3025 122 14884 40 1600 50 2500 90 8100 40 1600 45 2025 85 7225 35 1225 60 3600 95 9025 30 900 75 5625 105 11025 25 625 30 900 55 3025 33 1089 27 729 60 3600 34 1156 30 900 64 4096 33 1089 25 625 58 3364 total 507 23623 524 26108 1031 95213 Grand total 906 37654 1017 47343 1923 890877
Hipotesis interaksi nol dari kasus di atas adalaha. tidak ada perbedaan rata-rata produktivitas kerja pegawai lulusan DIII dengan lulusan S1

b.tidak ada perbedaan rata-rata produktivitas kerja pegawai masa kerja < 5 thaun dengan pegawai yang masa kerja >5tahunc. terdapat perbedaan rata –rata produktivitas kerja pegawai lulusan DIII dan S1 berdasarkan masa kerjad.tidak ada interaksi antara rata-rata produktivitas kerja berdasarkan lulusan dengan masa kerjae. terdapat interaksi antara rata-rata produktivitas kerja berdasarkan lulusan dengan masa kerja
7. nilai F hitung antar kolom pada soal no 6 adalaha.41,5066b.-41,5066c.43,506d-43,506e.4,068. nilai F hitung antar baris pada soal no 6 adalaha.41,5066b.-41,5066c.43,506d-43,506e.4,06
9. nilai F hitung interaksi baris dan kolom pada soal no 6 adalaha.41,5066b.-41,5066c.43,506d-43,506e.4,06
10.berdasarkan perbandingan antara nilai F hitung dengan F tabel maka kesimpulan yang dapat diambil pada soal no 6 adalaha. Terdapat perbedaan rata-rata produktivitas kerja pegawai lulusan DIII dengan lulusan S1b.terdapat perbedaan rata-rata produktivitas kerja pegawai masa kerja < 5 thaun dengan pegawai yang masa kerja >5tahunc. terdapat hubungan rata –rata produktivitas kerja pegawai lulusan DIII dan S1 berdasarkan masa kerjad.tidak ada interaksi antara rata-rata produktivitas kerja berdasarkan lulusan dengan masa kerjae. terdapat interaksi antara rata-rata produktivitas kerja berdasarkan lulusan dengan masa kerja
DAFTAR PUSTAKA

Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta
MODUL PEMBELAJARAN
UJI LANJUT
UJI TUKEY DAN UJI SHEFFE
Tujuan Pembelajaran
menguji hipotesis uji lanjut menggunakan uji Tukey
menguji hipotesis uji lanjut menggunakan uji Scheffe
Pendahuluan

Dalam pengujian ANAVA, kita dapat menarik kesimpulan apakah
menerima atau menolak hipotesis. Jika kita menolak hipotesis, artinya bahwa dari
variabel-variabel yang kita uji, terdapat perbedaan yang signifikan. Misalnya jika
kita menguji perbedaan 4 metode mengajar terhadap prestasi siswa, kita bisa
menyimpulkan bahwa ada perbedaan dari keempat metode tersebut. Akan tetapi,
kita tidak mengetahui, metode manakah yang berbeda dari keempatnya. Secara
statistik, kita tidak bisa mengatakan bahwa yang terbaik hanya dengan
memperhatikan rata-rata dari setiap metode tersebut.
Untuk menjawab pertanyaan metode manakah yang berbeda, maka
statistika memiliki teknik uji lanjut untuk mengetahui, variabel manakah yang
memiliki perbedaan yang signifikan. Ada banyak metode yang ada yang dapat
mengujinya dalam modul ini hanya akan dibahas uji Tukey dan Uji Scheffe pada
anava satu jalur.
Tujuan pembelajaran yang akan dicapai setelah mahasiswa mempelajari
modul pembelajaran ini adalah:
1. menguji hipotesis uji lanjut menggunakan uji Tukey
2. menguji hipotesis uji lanjut menggunakan uji Scheffe
1. Uji Tukey
Syarat
Ukuran kelompok semuanya harus sama (atau direratakan secara rerata
harmonik)
Jenis Pengujian
Ada dua jenis pengujian, melalui Jumlah pada kelompok, T dan Rerata pada
kelompok, X
Hipotesis-hipotesis
- Dua Sisi
H0: tidak terdapat perbedaan yang signifikan antara X1, X2, X3 dan seterusnya (X1 = X2 = X3 = …)

H1: minimal terdapat satu perbedaan yang signifikan antara X1 X2, X3 dan seterusnya. Seperti (X1 ≠ X2 ≠ X3 = …), (X1 ≠ X2 = X3 = …) atau (X1
= X2 ≠ X3 = …) dan sebagainya.
- Satu Sisi
H0: tidak terdapat perbedaan yang signifikan antara X1, X2, X3 dan seterusnya (X1 = X2 = X3 = …).
H1: ada kecenderungan X1 lebih besar dibandingkan X2 dan seterusnya (X1 > X2 > X3 > …).
- Satu Sisi
H0: tidak terdapat perbedaan yang signifikan antara X1, X2, X3 dan seterusnya (X1 = X2 = X3 = …).
H1: ada kecenderungan X1 lebih kecil dibandingkan X2 dan seterusnya (X1 < X2 < X3 < …).
Notasi yang digunakan
k : banyaknya kelompok
n : ukuran kelompok
n = n - k
Ti, Tj : jumlah pada kelompok
Xi, Xj : rerata pada kelompok
a : taraf signifikansi
q(a)(k,n) : pada tabel Tukey
Kriteria pengujian
- Jenis jumlah pada kelompok
Berbeda jika |Ti - Tj| ³ BT
- Jenis rerata kelompok
Berbeda jika |Xi - Xj| ³ BR
Contoh:
Pada modul pembelajaran anava satu jalur pada kasus untuk melihat perbedaan
pengeluaran perbulanb antara PNS,Petani dan pedagang, diketahui pada uji anava
ternyata kesimpulan yang didapat adalah menerima Ha atau paling tidak ada satu
yang memiliki pengeluaran /bulan yang berbeda, untuk mengetahui dimana letak

yang berbeda dapat dilanjutkan menggunakan uji Tukey ataupun uji Sheffe.
Berikut data Pengeluaran /bulan PNS, petani dan pedagang:
Tabel bantu Anova
PNS Petani Pedagang Jumlah Total
X1
121310151314101213141310131015
X12
144169100225169196100144169196169100169100225
X2
131512181517182014161816151316
X22
169225144324225289324400196256324256225169256
X3
181814201519202118171719161714
X32
324324196400225361400441324289289361256289196
Xtotal
434636534350485345474845444045
Xtotal2
637718440949619846824985689741782657650558637
187 2375 236 3722 263 4635 686 10732
n1 =15 n2 =15 n3 =15 N=45
Dari data di atas di dapat tabel ringkasan anava sebagai berikut:
Tabel Ringkasan Anava satu jalur
Sumber
variasi
dk Jumlah
Kuadrat
RK Fh F tabel Keputusa
n
Total 44 374,31 - 23,75 Dk pembilang=m-
1
Dk penyebut=N-m
Terima HaAntar
Kelompok
2 198,58 99,29

Alpha 5 % =3,22Dalam
kelompok
42 175,73 4,18
Untuk melihat dimana letak perbedaan dapat digunakan uji Tukey dan uji Scheffe:
1. Uji Tukey
Dari tabel di atas diketahui:
VARD = 4,18 N = 45 n = 15 a = 0,05
T1 = 187 = 187 / 15 = 12,5
T2 = 236 = 236 /15 = 15,7
T3 = 263 = 263/ 15 = 17,5
Pengujian dilakukan terhadap selisih pasangan rerata
m1 - m2
m2 - m3
m1 - m3
Kriteria pengujian, signifikan jika Q hitung > Q tabel
Dari tabel Tukey q(0,05)(3,42) = 3,42 sehingga
Pengujian melalui jumlah pada kelompok dengan kriteria 27
(a) |T1 - T2| = 49 signifikan
(b) |T1 - T3| = 76 signifikan
(c) |T2 - T3| = 27 Signifikan
Pengujian melalui rerata pada kelompok dengan riteria 1,77

(a) | - | = 3,2 Signifikan X1 ≠ X2
(b) | - | = 5 Signifikan X1 ≠ X3
(c) | - | = 1,8 Signifikan X2 ≠ X3
Kesimpulan
X1 ≠ X2 ≠ X3
2. Uji Sceffe
Uji Scheffe dilakukan melalui distribusi probabilitas pensampelan F-Fisher
Snedecor
Hipotesis-hipotesis
- Dua Sisi
H0: tidak terdapat perbedaan yang signifikan antara X1, X2, X3 dan seterusnya (X1 = X2 = X3 = …)
H1: minimal terdapat satu perbedaan yang signifikan antara X1 X2, X3 dan seterusnya. Seperti (X1 ≠ X2 ≠ X3 = …), (X1 ≠ X2 = X3 = …) atau (X1
= X2 ≠ X3 = …) dan sebagainya.
- Satu Sisi
H0: tidak terdapat perbedaan yang signifikan antara X1, X2, X3 dan seterusnya (X1 = X2 = X3 = …).
H1: ada kecenderungan X1 lebih besar dibandingkan X2 dan seterusnya (X1 > X2 > X3 > …).
- Satu Sisi
H0: tidak terdapat perbedaan yang signifikan antara X1, X2, X3 dan seterusnya (X1 = X2 = X3 = …).
H1: ada kecenderungan X1 lebih kecil dibandingkan X2 dan seterusnya (X1 < X2 < X3 < …).
Statistik uji
natas = k - 1
nbawah = n - k
k : banyaknya kelompok
ni, nj : ukuran kelompok

n : jumlah semua ukuran
kelompok
: rerata kelompok pada sampel

Komparasi ganda Scheffe diterapkan pada contoh di atas dengan taraf
signifikansi 0,05
VARD =4,18 N = 45 k = 3 a = 0,05
= 187 / 15 = 12,5
= 236 /15 = 15,7
= 263/ 15 = 17,5
Pengujian dilakukan terhadap selisih pasangan rerata
m1 - m2
m2 - m3
m1 - m3
Statistik uji
Karena n1 = n2 = n3 = 15, maka untuk semua pasang selisih rerata, terdapat
kesamaan pada
Kriteria pengujian
Nilai kritis F(0,95)(2)42) = 3,22 signifikan atau berbeda apabila F table < F
hitung
Pengujian
(a) m1 - m2 = -3,2
F = (10,24) / (0,468) = 21,9
signifikan X1≠ X2
(b) m1 - m3 =12,5 – 17,5= -5
F= (25) / (0,468) = 53,41
98

Signifikan X1 ≠ X3
(c) m2 - m3 = 15,7- 17,5=-1,8
F = (3,24) / (0,468) = 6,92
Signifikan X2 ≠ X3
Kesimpulan
X1 ≠ X2 ≠X3
99

100

Untuk menguji kemampuan mahasiswa kerjakan Tes Formatif Uji Tukey dan uji
Shceffe
Tes Formatif Uji lanjut
Petunjuk:Pilihlah jawaban yang paling benar dari soal-soal di bawah iniSoal
1. uji lanjut dilakukan untuk mengujia.hipotesis lanjutan apabila uji anova menerima HOb. hipotesis lanjutan apabila uji anova menerima Hac. hipotesis lanjutan apabila uji anova menolak Had. perbedaan dua rata-rata atau lebihe. hubungan antara dua variabel atau lebih
2. uji tukey biasa digunakan untuk uji lanjut yang memiliki jumlah kelompok sampel
a. besarb. kecilc. samad. berbedae. > 3
3. uji scheffe biasa digunakan untuk uji lanjut yang memiliki jumlah kelompok sampel
a. besarb. kecilc. samad. berbedae. > 3
101
4. pada anova satu jalur yang terdiri dari 5 kelompok sampel, apabila menolak HO maka pasanga perbedaan rata –rata yang akan diujikan berjumlah
a. 5b. 7c. 10d. 15e. 20
5. pada anova dua jalur 2X3, apabila menolak HO maka pasanga perbedaan rata –rata yang akan diujikan berjumlaha.2b.3c.6d.8e.12
6. data berikut adalah data pengeluaran /bulan 5 kantor kecamatan di kabupaten X dalam puluhan juta rupiah, ingin diketahui apakah ada perbedaan pengeluaran masing-masing kecamatan
X1 X2 X3 X4 X5
10 11 16 23 26
9 9 16 21 24
9 7 14 20 22
6 7 13 20 20
6 7 12 17 20
jumlahrata-rata Varian
x1 40 8 3,5x2 41 8,2 3,2x3 71 14,2 3,2x4 101 20,2 4,7x5 112 22,4 6,8
Tabel ringkasan anava sumber variasi dk JK RK Fh Ftabeltotal 24 970
51,66
5%2,86
antar kelompok 4 884,4 221,1
dalam kelompok 20 85,6 4,28
102

Kesimpulan yang dapat diambil pada menggunakan uji tukey adalaha. X1≠ X2 ≠ X3≠ X4 ≠ X5
b. X1 ≠ X2 = X3≠ X4 ≠ X5
c. X1 = X2 ≠ X3= X4 ≠ X5
d. X1 = X2 ≠ X3≠ X4 = X5
e. X1 = X2 ≠ X3≠ X4 ≠ X5
7.pada soal no. 6 kesimpulan yang dapat diambil menggunakan uji scheffe
adalah
a. X1≠ X2 ≠ X3≠ X4 ≠ X5
b. X1 ≠ X2 = X3≠ X4 ≠ X5
c. X1 = X2 ≠ X3= X4 ≠ X5
d. X1 = X2 ≠ X3≠ X4 = X5
e. X1 = X2 ≠ X3≠ X4 ≠ X5
8.jumlah pasangan rata yang akan dilihat perbedaannya pada soal tes formatif
anova dua arah no 6 adalah
a.2
b.4
c.6
d.8
e.10
9. jumlah pasangan rata yang akan dilihat perbedaannya pada soal tes formatif
anova dua arah no 1 adalah
a.6
b.12
c.18
d.24
e.25
10. pada soal no 6 tes formatif anova dua arah hanya hipotesis interaksi yang
menerima Ha, maka yang perlu dilihat perbedaannya adalah
a. rata-rata produktivitas kerja pegawai lulusan DIII dengan lulusan S1
103

b.rata-rata produktivitas kerja pegawai masa kerja < 5 tahun dengan pegawai yang masa kerja >5tahunc. hubungan rata –rata produktivitas kerja pegawai lulusan DIII dan S1 berdasarkan masa kerjad. rata-rata interaksi produktivitas kerja berdasarkan lulusan dengan masa kerjae. varian produktivitas kerja berdasarkan lulusan dengan masa kerja
DAFTAR PUSTAKA
Furqon (2002). Statistika Terapan Untuk Penelitian.Bandung. Alfabeta
Subagyo, Pangestu (2004). Statistika Terapan. Yogyakarta.BPFE
Sudjana (1996). Metoda Statistika. Bandung.Tarsito
Sugiyono (2004). Statistika Untuk Penelitian. Bandung. Alfabeta
________(2005)._________________________________________
Wijaya (2001).Statistika Non Parametris. Bandung. Alfabeta
MODUL
STATISTIK NONPARAMETRIS
Statistik nonparametris yang digunakan untuk menguji signifkasi hipotesis
komparatif k sample yang berpasangan antara lain adalah Chi Kuadrat, Test
Cochran, dan Friedman.
1) Chi Kuadrat k sample
Chi Kuadrat k sample digunakan untuk menguji hipotesis komparatif lebih
dari dua sampel, bila datanya berbentuk diskrit atau nominal. Rumus dasar yang
104

digunakan untuk pengujian adalah sama dengan komparatif dua sampel
independent, yaitu sebagai berikut.
Contoh :
Dilakukan penelitian untuk mengetahui ada tidaknya perbedaan harapan
hidup
( life expectation ) antar penduduk yang ada di Pulau Jawa, yaitu DKI
Jakarta, Jawa Barat, Jawa Tengah, Jawa Timur, dan Daerah Istimewa
Yogyakarta (DIY).Dalam hal ini umur harapan hidup dikelompokkan
menjadi dua yaitu di atas 70 tahun ke atas, dan dibawah 70 tahun.
Berdasarkan 1100 sampel untuk DKI Jakarta, 300 orang berumur 70 ke
atas, dan 800 orang berumur di bawah 70 tahun.Dari sampel 1300 orang
untuk Jawa Barat, 700 orang berumur 70 ke atas, dan 600 orang berumur
di bawah 70 tahun. Dari 1300 sampel untuk Jawa Tengah, 800 orang
berumur 70 ke atas, dan 500 orang berumur di bawah 70 tahun. Dari 1200
sampel untuk Jawa Timur, 700 orang berumur 70 tahun ke atas, dan 500
orang berumur di bawah 70 tahun. Selanjutnya dari 900 sampel untuk
DIY, 600 orang berumur 70 ke atas, dan 300 orang berumur di bawah 70
tahun.
Dari data tersebut selanjutnya disusun ke dalam table berikut.Untuk dapat
mengisi seluruh kolom yang ada pada table, maka perlu dihitung frekuensi yang
diharapkan (fn) untuk kelima kelompok sampel tersebut dalam setiap aspek. Untuk
mengetahui frekuensi yang diharakan (fn) pertama-tama harus dihitung berapa
prosen dari keseluruhan sampel umur 70 tahun ke atas dan di bawah 70 tahun.
105
∑ ( f o – fh ) 2 X2 = ∑ fh
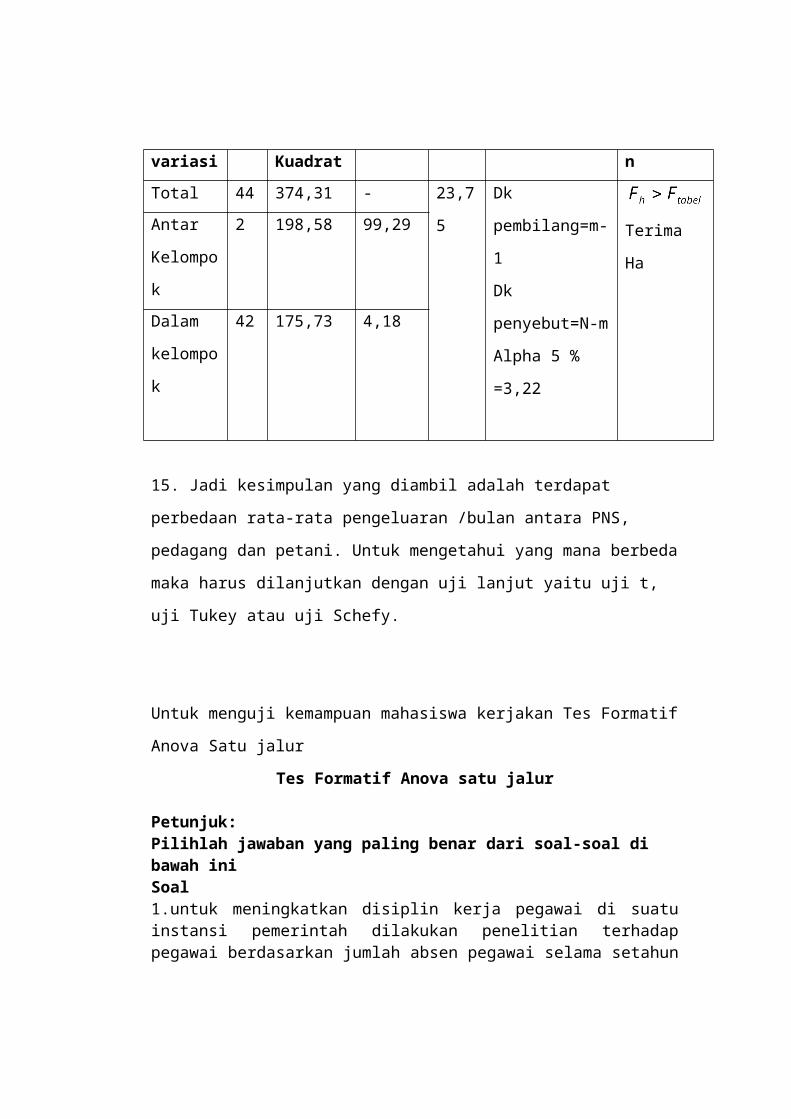
Jumlah seluruh anggota sampel untuk 5 propinsi tersebut adalah : 1100 + 1300 +
1200 + 900 = 5800.
Persentase umur 70 tahun ke atas adalah ( p1) :
P1 = 300 + 700 + 800 + 600 = 3.100 x 100 % = 53,45 %
5800 5.800
Frekuensi yang diharapkan (fn) untuk umur di atas 70 tahun untuk 5 propinsi
adalah sebagai berikut :
1. DKI Jakarta = 1.100 x 53,45 % = 587,95
2. Jawa Barat = 1.300 x 53,45 % = 694,85
3. Jawa Tengah = 1.300 x 53,45 % = 694,85
4. Jawa Timur = 1.200 x 53,45 % = 641,40
5.DIY = 900 x 53,45 % = 481,05
Persentase umur 70 tahun ke bawah adalah ( p2 ) :
P1 = 800 + 600 + 500 + 500 + 300 = 2700 x 100 % = 46,55 %
5.800 5.800
Frekuensi yang diharapkan ( fh ) untuk umur dibawah 70 tahun untuk 5 propinsi
adalah sebagai berikut :
1. DKI Jakarta = 1.100 x 46,55 % = 512,05
2. Jawa Barat = 1.300 x 46,55 % = 605,15
3.Jawa Tengah = 1.300 x 46,55 % = 605,15
4.Jawa Timur = 1.200 x 46,55 % = 558,60
5.DIY = 900 x 46,55 % = 418,95
Harga-harga tersebut selanjutnya dimasukkan ke dalam table sehingga harga Chi
Kuadrat dapat dihitung.
TABEL
PERBANDINGAN HARAPAN HIDUP PENDUDUK
LIMA PROPINSI DI JAWA
106

PropinsiHarapanHidup/umur
fo fh ( fo-fh )2 ( fo-fh )2 ( fo-fh ) 2 fh
DKIJakarta
≥ 70 thn< 70 thn
300800
587,95512,05
- 287,95 287,95
82915,282915,2
141,02161,93
JawaBarat
≥ 70 thn< 70 thn
700600
694,85605,15
5,15- 5,15
26,5226,52
0,040,04
JawaTengah
≥ 70 thn< 70 thn
800500
694,85605,15
105,15- 105,15
11056,5211056,52
15,9118,27
JawaTimur
≥ 70 thn< 70 thn
700500
641,40558,60
58,6- 58,6
3433,963433,96
5,356,15
DIY≥ 70 thn< 70 thn
600300
481,05418,95
118,95- 118,95
14149,114149,1
29,4133,77
Jml 5.800 5.800 0,00 411,90
Hipotesis statistik yang diajukan dalam penelitian tersebut adalah sebagai berikut:
Ho : Tidak terdapat perbedaan harapan hidup penduduk di lima proponsi
yang ada di Pulau Jawa.
Ha : Terdapat perbedaan harapan hidup penduduk di lima propinsi yang
ada di Pulau Jawa.
Ho : μ1 = μ2 = μ3 = μ4 = μ5
Ha : μ1 = μ2 = μ3 = μ4 = μ5 ( salah satu beda )
Bila Ho diterima, itu berarti juga keadaan yang ada pada sampel itu yang
betul-betul mencerminkan keadaan propinsi, sedangkan bila Ho ditolak, maka
keadaan pada sampel itu hanya berlaku untuk sampel itu, dia mungkin terjadi
kesalahan dalam memilih sampel.
Berdasarkan perhitungan yang telah dirumuskan ke dalam tabel terlihat
bahwa Chi Kuadrat hitung = 411,90. Untuk memberikan interpretasi terhadap nilai
ini maka perlu dibandingkan dengan harga Chi Kuadrat table dengan dk dan taraf
kesalahan tertentu.
107

Dalam hal ini besarnya dk = ( s - 1) x ( k – 1 ) = ( 5 -1 ) x ( 2 – 1 ) = 4. ( s
jumlah kelompok sampel = 5, k banyak kategori dalam sampel 2 ). Berdasarkan
dk = 4 dan taraf kesalahan = 5 %, maka harga Chi Kuadrat hitung = 9.488.
Harga Chi Kuadrat hitung, ternyata lebih besar dari tabel ( 411,90 >
9,488 ) karena harga Chi Kuadrat hitung lebih besar dari tabel, maka Ho ditolak
dan Ha diterima. Hal ini berarti terdapat perbedaan yang signifikan antara harapan
hidup penduduk di lima propinsi yang ada di Pulau Jawa, dan perbedaan itu
tercermin seperti data dalam sampel.
Pengujian hipotesis di atas adalah menguji perbedaan atau persamaan
seluruh sampel secara bersama-sama. Untuk menguji antara satu sampel dengan
sampel lain berbeda atau tidak, maka diperlukan lebih lanjut pengujian antar dua
sampel. Bila dalam pengujian hipotesis untuk k sampel tersebut dinyatakan Ho
diterima, itu juga berarti antar dua sampel juga tidak ada perbedaan, tetapi kalau
Ho ditolak, bisa terjadi hanya antar dua sampel tertentu saja yang berbeda,
mungkin sampai yang lain tidak.
108