bab 5. pengumpulan data dan analisis
TRANSCRIPT

BAB5PENGUMPULAN DATA DAN ANALISIS
Tujuan Instruksional Khusus
Mahasiswa mampu mernmuskan pengumpulandata1. Mahasiswa dapat membuat kerangka
pengumpulan data2. Mahasiswa dapat menguraikan dan
membedakan berbagai distribusi statistik3. Mahasiswa dapat menggunakan uji kebaikan
sual
Tujuan Instruksional Umum
5.1. PendahuluanDalam proyek simulasi, penggunaan data input paling penting adalah untuk
mendorong simulasi. Proses ini melibatkan pengumpulan data input, analisis inputdata, dan penggunaan analisis data input dalam model simulasi. Input data mungkindiperoleh dari catatan sejarah atau dikumpulkan secara waktu nyata sebagai tugasdalam proyek simulasi. Analisis melibatkan identifikasi distribusi teoritis yangmewakili data input. Penggunaan data input dalam model termasuk menentukandistribusi teoritis dalam kode program simulasi.
Pertanyaan umum adalah mengapa kita perlu mempertimbangkanpenyesuaian data dengan distribusi teoretis jika kita telah mengumpulkan nilai data.Alasan yang mendasar adalah bahwa ketika para praktisi mengumpulkan data, hanyasampel dari distribusi data sebenamya yang dikumpulkan. Walaupun praktisi tidakmelihat nilai-nilai tertentu, itu tidak berarti bahwa nilai-nilai data tidak teramati tidakbenar-benar ada di sistem. Jika kita berhasil mengamati sesuai dengan data untukdistribusi teoretis, maka setiap nilai data dari distribusi teoritis dapat mendorongmodel simulasi. Ini adalah situasi yang jauh lebih realistis daripada menjalankansimulasi dengan hanya nilai data yang diamati.
Salah satu kelemahan dari pendekatan ini adalah bahwa distribusi teoritisdapat secara berkala menghasilkan nilai yang tidak biasa yang mungkin tidak benar-benar pemah hadir dalam sistem nyata. Contoh adalah waktu antar kedatangandengan nilai yang sangat panjang. Meskipun hal ini tidak terlalu sering teljadi,praktisi hams menyadari kemungkinan ini. Jika model ini memperlihatkan perilakuyang tidak biasa yang bisa saja akibat distribusi teoretis, maka praktisi dapatmengambil tindakan. Penting untuk menekankan bahwa ini adalah peristiwa yang
83

sangat tidak mungkin dan bahwa adalah mungkin untuk membuat banyak modelsimulasi selamabertahun-tahun tanpa menghadapi situasi ini.
Pengumpulan data input sering dianggap sebagai proses yang paling sulitdalam melakukan simulasi pemodelan dan analisis proyek. Bagian ini berkaitandengan fakta bahwa analis simulasi dapat tergantung pada individu dan operasi diluar kendali dari analis. Hal ini berlaku terlepas dari apakah data input historis secaraalami atau akan dikumpulkan dalam waktu-nyata sebagai bagian dari proyek. Dalamsituasi lain, data input yang diperlukan mungkin tidak ada. Keadaan ini seringdijumpai ketika proyek melibatkan analisis peralatan model baru. Untuk membantupara praktisi dalam pengumpulan data dan proses analisis, bagian ini termasukdiskusi pada:1. Sumber data input2. Pengumpulan data input3. Data input deterministikvs probabilistik4. Data input diskrit vs kontinu5. Distribusi data inputyang umum6. Penganalisaan data input
5.2 Sumber Input Data
Ada banyak sumber yang dapat praktisi gunakan untuk memperoleh datainput. Data ini dapat menjadi sejarah, anekdot, atau observasi. Bahkan jika suatumodel sistem sebenamya tidak ada, adalah mungkin bagi praktisi untuk memperolehmasukan yang diperlukan dari sumber lain. Sumber-sumber yang tersedia untuk parapraktisi meliputi, tetapi tidak terbatas pada, catatan sejarah, spesifikasi produsen,klaim vendor, perkiraan operator, perkiraan manajemen, pengumpul data otomatis,dan observasi langsung.
Data Historis. Jika sistem dasar atau yang menyerupai telah ada selamabeberapa waktu, kemungkinan bahwa ada beberapa bentuk catatan sejarah tersediauntuk para praktisi. Karena catatan sudah ada dan tidak akan memerlukanpengumpulan data waktu nyata, pendekatan ini mungkin muncul untuk menjadipilihan yang sangatmenarik bagi praktisi. Hal inijuga sering menarik bagi organisasipengarah, yang percaya bahwa uang akan diselamatkan dengan menggunakanpendekatan ini. Namun, penggunaan catatan sejarah bukannya tanpa risiko besar.Risiko pertama adalah bahwa sistem sejarah asli telah berubah entah bagaimana atautidak persis sarna dengan sistem yang sekarang atau yang diusulkan. Berdasarkanperbandingan setiap jenis data dengan keandalan yang dipertanyakan pada masa
84

depan pasti mengalami kesulitan. Diduga, karena sistem tidak sarna, setiap usahauntuk memvalidasi model dengan sistemdata yang sekarang pasti gagal.
Masalah lain adalah bahwa data historis tidak mungkin dikumpulkan denganmodel simulasi secara khusus dalam pikiran. Ini berarti bahwa data yang benar-benardibutuhkan tidak benar-benar tersedia. Terlalu sering, praktisi tidak menyadari halini sampai sudahjauh ke dalam model terjemahan atau bahkan tahap validasi proyeksimulasi. Pada waktu itu, proyek bisa begitu ditekan sehingga tidak mungkin untukkembali ke sistemaktual danmengumpulkan data input model yang benar.
Karena potensi masalah substansial yang terkait dengan penggunaan catatansejarah, praktisi hams berpikir panjang dan keras sebelum menggunakannya. Hal iniyang akan membuat praktisi bekerja ekstrajika pendekatan iniberjalan masam.
Spesifikasi Produsen. Spesifikasi produsen juga menawarkan praktisikesempatan untuk menggunakan data yang telah dikompilasi orang lain. Jelas,sebagian besar produsen akan menyediakan sebuah teori berdasarkan spesifikasiuntuk peralatan mereka. Apakah klaim ini benar-benar dapat dicapai dalamlingkungan yang sesungguhnya hams dibuktikan.
Klaim Vendor. Klaim vendor atau distributor mungkin akan jatuh di antaraspesifikasi pabrik dan realitas. Vendor atau distributor hams sudah memilikipengalaman dengan tipe sistem yang sedang dipertimbangkan. Beberapa organisasimanufaktur membutuhkan vendor dan distributor untuk menciptakan modelsimulasi untuk membuktikan kemampuan peralatan mereka.
Perkiraan Operator. Operator peralatan yang ada dapat menjadi sumberdata yang berharga ketika praktisi tidak memiliki waktu atau sumber pengumpulandata untuk mengumpulkan data aktual. Jika operator memiliki pengetahuan tentangsistem, adalah mungkin untuk mendapatkan beberapa perkiraan kinerja yang dapatdigunakan sebagai data masukan. Sebagai contoh, operator dapat ditanyakan waktupemrosesan terpendek, paling umum, dan terpanjang untuk operasi tertentu. Praktisikemudian dapat menggunakan data ini sebagai perkiraan pertama dengan distribusisegitiga.
Perkiraan Manajemen. Praktisi juga dapat mempertimbangkan untukmeminta manajer atau teknisi yang berkaitan dengan sistem. Meskipun orang-orangini mungkin tidak memiliki hubungan kedekatan yang sarnadengan proses, masukanmereka mungkin akan membantu bila operator yang berpengalaman tidak tersediauntuk memberi masukan.
85

--
Pengumpul Data Otomatis. Dimungkinkan untuk membuat semacamsistem pengambilan data otomatis. Hal ini analog ke monitor volume lalu lintas yangsering dijumpai di jalan. Monitor ini menghitung frekuensi mobil yang lewat titiktertentu selama jangka waktu tertentu. Akses elektronik atau informasi lain yangberbasis sistem mungkinjuga dapat menangkap jenis data yang dibutuhkan praktisiuntuk model simulasi.
Observasi langsung. Hal yang paling menuntut secara fisik dan mentalbentuk pengumpulan data adalah pengamatan langsung. Pengamatan langsungadalah dimana praktisi atau orang lain benar-benar pergi ke lokasi sistem danmengumpulkan data visual. Data dikumpulkan oleh pena dan buku catatan ataumungkin dengan bantuan teknologi. Jika pendekatan teknologi rendah pena danpapan yang digunakan, praktisi mungkin ingin mengembangkan semacampengumpulan data formulir untuk menjaga proses terorganisir sebisamungkin.
5.3 Mengumpulkan Data Input
Dari pembahasan sebelumnya, kita hams yakin bahwa kebijakan yang terbaikadalah mengumpulkan data input menggunakan pengamatan. Hal ini, tentu saja,dapat dilakukan asalkan waktu dan sumber daya memungkinkan pendekatansemacam itu.
5.3.1 Peralatan Pengumpulan Data
Jika input data dikumpulkan secara waktu nyata, hal itu dapat dikumpulkansecara manual atau dengan bantuan perangkat elektronik. Jika data dikumpulkansecara manual dengan alat pengatur waktu, mungkin akan membantu untukmembuat formulir untuk membantu menjaga proses pengumpulan data sebisamungkin terorganisasi. Praktisi dapat menjaga terorganisasinya data denganmengamankan secara mekanis atau menggunakan jam henti elektronik ke papanpengumpulan data.
Berbagai pilihan perangkat elektronik studi waktu mungkin akandimanfaatkan. Atau, analis dapat memilih untuk mengembangkan programsederhana pada komputer notebook untuk membantu pengumpulan data. Diprogramdengan menekan tombol, praktisi dapat melacak tingkat antar kedatangan tanpahams menuliskan waktunya. Keindahan dari pendekatan ini adalah bahwa data dapatsecara otomatis dicatat dalam sebuah berkas untuk analisis. Ini akan menghindarkanpraktisi pada proses yang sangat membosankan untuk transkripsi data dari kertas kekomputer.
86

Penggunaan alat perekam video menawarkan kemungkinan lain lagi untukmengumpulkan data ketika masalah privasi tidak perlu dipertimbangkan.Kebanyakan alat perekam video memiliki layar pengamatan bergerak. Jadi, adalahmungkin untuk merekam proses yang berbeda tanpa terlihat terlalu jelas. Karenapemutaran dapat dilakukan dalam jumlah tak terbatas, adalah sering untukmengamati kegiatan yang biasanya telah terlewatkan pada waktu nyata.
5.3.2 Model dan Unit Pengumpulan Data.
Isu penting untuk simulasi input data mengenai interval waktu adalah satuanwaktu yang hams digunakan. Praktisi pemula sering diamati dapat merekam waktuabsolut atau jam waktu ketika entitas yang berbeda tiba ke dalam sistem. Jikapendekatan ini diambil, pekeIjaan tambahan akan diperlukan untuk mengubahwaktu absolut ke waktu relatif sehingga waktu antar kedatangan dapat dihitung.Biasanya dibutuhkan tenaga keIja kurang intensif untuk mengumpulkan data denganbenar di tempat pertama menggunakan relatif, pendekatan waktu antarkedatangan.
Isu pengumpulan data kedua adalah jenis unit yang akan digunakan.Penghitungan tujuan, mungkin sulit untuk digunakan sebagai sebuah satuan waktukecil seperti detik. Hal ini lebih mudah dipahami ketika menjalankan simulasi baikdilakukan untuk 8jam atau 480 menit, tidak 28.800 detik. Jika diambil unit tengah,dan sebuah unit waktu simulasi menit dipilih, semua nilai data baik itu hamsdikumpulkan dalam satuan waktu yang sarna atau diubah di beberapa titik. Sebagaicontoh, jika waktu layanan diambil dalam beberapa menit dan detik, yang detikakhirnya hams dikonversi ke dalam pecahan menit. Meskipun konversi data dengancara ini dapat dilakukan dalam sebuah pengolah data elektronik,juga dimungkinkanuntuk memperoleh apa yang dikenal sebagai desimal menitjam henti. Jenisjam hentikhusus mencatat menit sebagai menit dan detik sebagai perseratus menit. Ketikapenghenti desimal jam henti digunakan, data dikumpulkan dalam sebuah formatyang segera dapat digunakan. Ingatlah selalu bahwa proses konversi satuan waktumenjadi terlalu memberatkan.
5.3.3 Pertimbangan Pengumpulan Data Lainnya.
Praktisi simulasi hams juga beIjuang untuk menjadi selalu terbuka tapi jugasesederhana mungkin saat mengumpulkan data. Setidaknya ada dua alasan untuk ini,yaitu (1)Anda ingin data tidak bias; dan (2)Anda tidak ingin mengganggu proses.
87

- -
Data tidak bias. Pertama, jika adalah jelas bahwa praktisi mengumpulkandata kinerja jenis tertentu, beberapa pekerja mungkin bernsaha untuk memberikanbias pada hasil pengumpulan data. Beberapa pekerja mungkin untuk sementaramempercepat laju pekerjaan mereka supaya terlihat menjadi produktif. Pekerja lainmungkin sengaja memperlambat laju pekerjaan mereka untuk mencegah standarkerja yang tinggi dari yang ditetapkan. Jika data bias dari salah satu perilaku ini,dapat mengarah pada sebuah model yang dapat menghasilkan hasil yang tidakakurat. Jadi tindakan terbaik adalah dengan memberikan pengarahan singkat kepadapara pekerja. Dalam pengarahan singkat ini, praktisi harns menjelaskan tujuan daripengumpulan data.
Hindari Gangguan Proses. Tujuan lain bahwa praktisi harns bernsaha untuktidak mengganggu operasi yang sedang berlangsung. Jika praktisi mempertahankanprofil yang tinggi di tengah proses, kemudian pelanggan atau operator yang belummenerima pengarahan dapat menjadi penasaran. Individu ini mungkin tidak hanyaberperilaku tidak normal, tetapi dapat juga mengalihkan perhatian para praktisidengan pertanyaan. Jika praktisi terganggu, lalu masukan penting data tersebut dapathilang atau rnsak. Dalam kasus ekstrim, masalah-masalah lain dapat terjadi.Operator atau pelanggan kurang informasi mungkin menghubungi keamanan ataupenegak hukum dan melaporkan kegiatan pengumpulan data yang mencurigakan.
5.4 Data Deterministik versus probabilitik
Sementara mengumpulkan data input, praktisi harns menyadari bahwa adaberbagai klasifikasi data. Satu metode untuk mengklasifikasi data adalah apakahdeterministik atau probabilistik. Setiap individu proyek akan menggunakansekumpulan unik atau jenis data input. Beberapa jenis input data tersebut dapatdeterministik, danjenis lainnya probabilistik.
Data Deterministik. Data deterministik berarti bahwa peristiwa yangmelibatkan data yang terjadi dengan cara yang sarna atau dalam cara yang dapatdiprediksi setiap kalinya. Ini berarti bahwa jenis data perlu dikumpulkan hanyasekali karena itu tidak pemah bervariasi nilainya. Contoh proses input deterministikmeliputi:1. Program komputer mesin dikontrol secara numerik waktu pemrosesan.2. Interval perawatan preventif.3. Kecepatan conveyor
88

Waktu pemrosesan program komputer mesin dikontrol secara numerik adalahdeterministik karena kecuali ada semacam masalah, program selalu mengambiljumlah waktu yang sarna untuk menjalankannya. Program-program ini mengikutisatu himpunan sejumlah langkah masukan pemrosesan dengan nilai yang telahditentukan sebagai alat mesin yang dikendalikan oleh komputer. Kecuali adasemacam masalah mesin, tidak ada kemungkinan penyimpangan dari programkomputer.
Jadwal pemeliharaan preventifjuga dapat ditentukan dengan interval tertentu.Interval dapat berdasarkan jumlah komponen telah diproses atau setelah selangwaktu tertentu telah berlalu. Dalam kedua kasus, jumlah atau selang waktu yangditentukan di awal dan bisa sarna untuk setiap siklus pemeliharaan preventif.Demikian pula, sebagian besar konveyor beroperasi pada kecepatan tertentu.Kecepatan ditentukan oleh kecepatan motor dan gearing yang menggerakkan banbeIjalan. Ini berarti bahwa kecepatan konveyor dapat diatur ke nilai-nilai yangberbeda, tetapi, sementara ban beIjalan, hal itu akan dijalankan pada kecepatan yangditetapkan. Sementara kecepatan ban beIjalan akan berubah hanyaj ika ada semacamkerusakan atau kegagalan.
Input Data Probabilistik. Berbeda dengan proses deterministik, sebuahproses probabilistik tidak teIjadi dengan jenis keteraturan yang sarna. Dalam kasusini, proses akan mengikuti beberapa distribusi probabilistik. Dengan demikian, tidakdiketahui dengan keyakinan yang sarna bahwa proses itu akan mengikuti perilakuyang diketahui dengan pasti. Contoh data probabilistik meliputi waktu antarkedatangan, proses pelayanan pelanggan, dan waktu perbaikan.
Waktu antar kedatangan untuk entitas yang masuk ke sistem hampir selaluprobabilistik. Interval antara entitas terakhir dengan entitas berikutnya mungkinpendek, atau mungkin akan lama. Tidak diketahui dengan pasti kapan entitasberikutnya akan tiba. Namun, dengan mengumpulkan data antar kedatangan massa,adalah mungkin untuk melihat apakah data mengikuti distribusi tertentu. Jikajumlahentitas pendatang dalam jangka waktu tertentu benar-benar acak, maka waktu antarkedatangan entitas benar-benarmengikuti distribusi eksponensial.
Waktu pelayanan pelanggan juga dapat diharapkan bersifat probabilistik.Dengan kata lain, jumlah waktu yang dibutuhkan untuk memproses pelangganindividu di sebuah pusat layanan akan bervariasi, tergantung pada apa yangdibutuhkan pelanggan. Selain itu, setiap kali seorang manusia terlibat dalam prosespelayanan, ada kemungkinan akan teIjadi beberapa varian dalam waktu pelayanan.
89

Pada umumnya, dalam proses pelayanan, sejumlah kecil pelanggan akan diproseslebih cepat daripada yang lain. Demikian pula, sejumlah kedl pe1angganmungkinmemerlukan waktu lebih lama untuk diproses. Sebagian besar pelanggan mungkinmemerlukan waktu antara dua ekstrem.
Pola yang menggambarkan jumlah pengamatan terhadap waktu pemrosesanmenciptakan sebuah distribusi probabilistik. Sekali lagi, meskipun beberapainformasi tersedia tentang pola probabilitas waktu pemrosesan yang berikut,waktu pemrosesan pelanggan individu di masa depan tidak dapat diprediksi dengantepat. Namun, temyata sering ditemukan bahwa waktu pelayanan pelangganmengikuti distribusi normal karena proses sebenamya merupakan jumlah darisejumlah kecil waktu sub proses.
Seperti waktu pelayanan, waktu perbaikan cenderung probabilistik secaraalami. Hal ini karena adalah mustahil untuk memprediksi masalah macam apa yangperlu diperbaiki. Jika masalah ini tidak serius, maka diharapkan bahwa waktuperbaikan akan lebih pendek. Sebaliknya, jika masalah berat atau memerlukanbagian lain, waktu perbaikan akan lebihpanjang.
5.5 Data Diskrit vs Kontinu
Klasifikasi lain input data adalah apakah data diskrit atau kontinu. Jenis datadiskrit hanya dapat mengambil nilai-nilai tertentu. Biasanya ini berarti seluruhnomor. Contoh dari data diskrit dalam aplikasi simulasi adalah:1. Jumlah orang yang datang dalam suatu sistem sebagai suatu kelompok atau
batch2. Jumlah pekerjaan diproses sebelum sebuah mesin mengalami kerusakan
Batch pendatang biasanya terjadi dalam pelayanan dan sistem jenis hiburan.Jumlah pelanggan dalam batch hanya dapat diasumsikan dalam nilai bilangan bulat.Tidak mungkin untuk memiliki pelanggan fraksional. Demikian pula, jumlahpekerjaan diproses melalui mesin sebelum mengalami kerusakan adalah sebuahangka bulat. Pekerjaan baik yang selesai maupun tidak selesai. Distribusi kontinu, disisi lain, dapat mengambil nilai dalam kisaran yang diamati. Ini berarti bahwa angka-angka pecahan kemungkinannya besar terjadi. Contoh dari data jenis kontinumeliputi waktu antarapendatang, waktu pelayanan, danwaktu rute.
Jelas, waktu antara entitas pendatang dalam suatu sistem dapat mengambilsetiap nilai antara 0 dan tak terhingga terlepas dari satuan waktu yang digunakan. Ini
90

jelas termasuk waktu pecahan nilai. Meskipun beberapa waktu pelayanan mungkinlebih sering diamati daripada yang lain, waktu pelayanan dapatjuga mengambil nilaiapapun dalam rentang walctu yang diamati. Bagaimanapun waktu pelayananmungkin memiliki beberapa nilai spesifIkdi bawah batas bawah yang tidak mungkinuntuk diamati. Demikian pula, waktu perjalanan entitas dengan berjalan kaki jugadapat mengambil setiap nilai dalamkisaran yang masuk akal.
5.6 Distribusi Data Input Umum
Tujuan dari bagian ini bukanlah untuk mengubah praktisi menjadi ahlistatistik, tapi untuk memberikan beberapa tingkat pengenalan dengan beberapadistribusi data input yang paling umum. Ada banyak lagi jenis distribusi probabilitasyang praktisi mungkin benar-benar hadapi. Kadang-kadang praktisi mungkinmenghadapi distribusi ini hanya sebagai hasil dari program sesuai dataterkomputerisasi. Dalamjenis kasus ini, hasil tertentu tidak selalu berarti bahwa adaalasan rasional mengapa data paling cocok dengan distribusi tertentu. Kadang-kadang distribusi teoretis yang masuk akal akan hampir sarna baiknya dan cocok.Dalam kasus ini, praktisi hams memutuskan sendiri apakah akan menggunakanmatematika sesuai yang terbaik atau sangat dekat sesuai yang masuk akal.
Distribusi statistik teoritis umum yang akan dibahas adalah distribusiBernoulli, Seragam, eksponensial, Normal, dan Segitiga. Ada juga diskusi terbatasdistribusi yang kurang umum seperti Beta, Gamma, Weibull.
Distribusi Bernoulli. Distribusi Bernoulli digunakan untuk model kejadianacak dengan salah satu dari dua kemungkinan hasil. Kemungkinan hasil seringdisebut sebagai suatu keberhasilan atau kegagalan. Nilai rata-rata dan varians daridistribusi Bernoulli adalah:
rata -rata = pVar = p (I-p)
di mana p = fraksi keberhasilan dan (I - p) = fraksi kegagalan. Contoh distribusiBernoulli dalam simulasi dapat ditemukan di (I) proses inspeksi gagal/berhasil, (2)penumpang kelas pertama vs penumpang ekonomi, (3) pesanan bum-bum vsprioritas teratur.
Dalam kasus berhasil vs gagal melewati proses inspeksi, komponen hanyadapat salah satu dari kedua status. Jika 95% dari komponen berhasil melewatipemeriksaan, maka nilai p akan menjadi 0.95. Sebesar 5% tingkat kegagalan akandiwakili oleh 0.05. Penumpang kelas pertama vs ekonomi tidak benar-benar seperti
91

kategorisasi kegagalan vs keberhasilan. Dalam hal ini hanyalah persentasepenumpang ke1aspertama dan ke1aspenumpang ekonomi harus total 1.0.
Situasi yang serupa terjadi dengan pesanan prioritas terburu-buru vs reguler.Tidak ada keberhasilan atau kegagalan yang berhubungan dengan terburu-buru atauperintah biasa. Hanya ada dua jenis pemesanan dengan persentase yang berbedakemungkinan.
Distribusi Uniform. Sebuah distribusi uniform berarti bahwa selama rentangnilai yang mungkin, masing-masing individu memiliki kemungkinan nilai yangsarna harus diamati. Contoh yang umum dari suatu distribusi seragam adalahperilaku dadu tunggal dengan nilai 6. Nilai minimum mungkin adalah 1 dan nilaimaksimal adalah 6. Karena semuabagian adalah sarna, ada kemungkinan yang sarnamenerima salah satu dari nilai-nilai antara 1 dan 6. Walaupun ada sedikitkemungkinan menghadapi model simulasi yang menggunakan dadu tunggal sisienam, distribusi seragam memang memiliki beberapa aplikasi dalam dunia simulasi.Distribusi seragam dapat digunakan sebagai model pertama sebagai contoh untukdata input dari sebuah proses jika ada sedikit pengetahuan tentang proses. Semuayang dibutuhkan untuk menggunakan distribusi seragam hanyalah waktu minimumdan waktu maksimum proses. Walaupun belum tentu asumsi valid bahwa dataterdistribusi secara seragam, distribusi seragam mengizinkan praktisi untuk mulaimembangun model simulasi. Begitu model menjadi lebih rumit, praktisi dapatmemberikan pemikiran untuk menggunakan distribusi yang lebih akurat atau lebihtepat.
Distribusi seragam dapat bersifat diskrit atau kontinu. Dalam kasus dadutunggal dengan sisi enam, distribusi dianggap diskrit. Ini berarti bahwa nilai-nilaidata hanya dapat mengambil seluruh bilangan dalam batas yang berlaku. Padakenyataannya, kebanyakan proses simulasi yang sebenarnya secara seragamterdistribusi dapat mengambil nilai apapun termasuk angka pecahan antaraminimum dan nilai maksimum. Jenis data ini adalah distribusi seragam kontinu.Formula untuk nilai rata-rata dan varians distribusi seragam adalah:
Rata-rata = (a+bi ; Var = (b_a)22 12
Di mana a adalah nilai minimum danb adalah nilai maksimum.
Distribusi eksponensial. Distribusi eksponensial biasanya digunakan dalamhubungannya dengan proses antar kedatangan dalam model simulasi karena
92

kedatangan entitas dalam banyak sistem telah terbukti baik atau diasumsikan acakatau proses Poisson. Ini berarti bahwa jumlah acak entitas akan tiba dalam satuanwaktu tertentu. Bahkan meskipun proses acak, masih akan ada beberapa rata-ratajumlah kedatangan dalam satuan waktu. Jumlah pendatang yang dapat diharapkantiba pada unit waktu didistribusikan secara acak di sekitar nilai rata-rata.
Ketika suatu sistem menampilkan keacakan atau distribusi Poisson untukjumlah pendatang untuk jangka waktu tertentu, waktu antara kedatangan temyataterdistribusi secara eksponensial. Distribusi eksponensial hanya memiliki satuparameter. Nilai ini adalah nilai rata-rata. Jika waktu antar kedatangan menunjukkandistribusi eksponensial, akan ada lebih banyak pengamatan dengan waktu antarkedatangan lebih kecil dari nilai rata-rata. Juga akan ada lebih sedikit pengamatandengan waktu antar kedatangan lebih besar daripada nilai rata-rata. Dengandemikian, jumlah observasi terns menurun seiring peningkatan waktu antarkedatangan. Persamaan statistik untuk nilai rata dan varians dari distribusieksponensial adalah:
Probabilitas diwakili oleh rnmus berikut:
Rata - rata = B ; Var = B2
di mana B adalah rata-rata dari data sampel dan x adalah nilai data. Hal inijugamemungkinkan untuk memanipulasi persamaan distribusi eksponensial untukkeperluan lain. Secara khusus, jika kita mengintegrasikan persamaan ini danmelakukan transformasi invers, kita dapat mengetahui persentase kumulatifpengamatan apakah berada di bawah nilai tertentu. Sebaliknya,jika kita menetapkanpersentase kumulatif, maka kita juga dapat menemukan nilai kritis. Ini berarti bahwauntuk didistribusikan secara eksponensial himpunan data dengan rata-rata B,persentase F (x) data akan ada dengan nilai kurang dari atau sarna dengan x. Sebagaicontoh, jika himpunan data terdistribusi secara eksponensial dengan rata-rata 5,maka kita dapat menghitung nilai kritis untuk persentase kumulatifO.75:
6.93 = -5 x In (1-0.75)
Ini berarti bahwa 75% dari pengamatan yang terdistribusi secara eksponensialdalam himpunan data dengan rata-rata 5 akan memiliki nilai 6.93 atau kurang.Kemampuan untuk mengubah persentase kumulatifke nilai kritis ini sangat bergunaketika seseorang mencoba melakukan uji kebaikan suai untuk menentukan apakahsuatu kumpulan data bisa berasal dari distribusi eksponensial.
93

Contoh proses yang mungkin akanmengikuti distribusi eksponensial meliputi:antar kedatangan pelanggan, antar kedatangan perintah, dan antar kemsakan ataukegagalan mesin.
Perhatikan bahwa masing-masing contoh ini melibatkan waktu antarkedatangan. Sebagaimana dibahas sebelumnya, distribusi eksponensial berlakuketika jumlah pendatang, apa pun bentuknya, secara acak didistribusikan denganbeberapa nilai rata-rata selama jangka waktu tertentu' Ini tidakberarti bahwadistribusi eksponensial tidak dapat digunakan untuk model jenis proses lainnya.Namun,jika tidak ada alasan mendasar untuk distribusi teoritis yang digunakan, datayang teramati hams sesuai dengan distribusi teoritis khusus agar penggunaannyamenjadi sah.
Distribusi Segitiga. Distribusi segitiga dapat digunakan dalam situasi di manapraktisi tidak memiliki pengetahuan lengkap tentang sistem, tetapi dapat mendugabahwa data tidak secara seragam terdistribusi. Secara khusus, kalau praktisimencurigai bahwa data terdistribusi secara normal, distribusi segitiga mungkinpendekatan pertama yang baik. Distribusi segitiga hanya memiliki tiga parameter:nilai minimum mungkin, nilai yang paling umum, dan nilai yang paling maksimum.Karena nilai yang paling umum tidak hams sarna antara minimum dan nilaimaksimum, distribusi segitiga tidak selalu hams simetris.
Jika praktisi menganggap bahwa data didistribusikan secara triangular(segitiga), tidak perlu untuk mengumpulkan banyak data. Bahkan, praktisi benar-benar hanya hams mengenal tiga nilai parameter. Dalam praktiknya, nilai-nilai inidapat diperoleh dengan meminta seorang manajer atau operator mesin untukmemberikan perkiraan. Nilai rata-rata dan varians dari distribusi segitiga adalah:
Rata - rata = a+m+b; Var = (a2+m2+b2-ma-ab-mb)3 18
Di mana a = nilai minimum, m = nilai yang paling umum (modus), b = nilaimaksimum
Contoh penggunaan distribusi segitiga meliputi waktu pemrosesanmanufaktur, waktu pelayanan pelanggan, dan waktu perjalanan. Waktu prosesmanufaktur dapat mencakup proses probabilistik. Ini berarti bahwa prosesmanufaktur kemungkinan besar memerlukan kehadiran manusia di suatu tempatdalam proses. Dapat juga proses yang lebih deterministik di mana masih ada
94

berbagai pekerjaan yang berbeda. Waktu layanan pelanggan dapat berhasildimodelkan dengan distribusi segitiga.Akhir minimum distribusi mungkin mewakilijumlah waktu untuk mencatat data demografis atau mengakses catatan pelanggandalam basis data. Waktu yang paling umum akan mencerminkan semua prosestransaksi yang khas. Waktu maksimum akan mewakili layanan yang sangatkompleks.dimodelkan dengan distribusi segitiga.Akhir minimum distribusi mungkin mewakilijumlah waktu untuk mencatat data demografis atau mengakses catatan pelanggandalam basis data. Waktu yang paling umum akan mencerminkan semua prosestransaksi yang khas. Waktu maksimum akan mewakili layanan yang sangatkompleks.
Waktu perjalanan juga dapat dimodelkan dengan distribusi segitiga. Dalamkasus pemodelan waktu perjalanan di bandara, waktu minimum akan sesuai denganseseorang berlari antara lokasi tanpa bagasi. Waktu paling umum setara denganorang berlari hanya dengan satu atau dua kantong yang mudah dikelola. Waktumaksimum setara dengan orang berjalan denganbeban koper besar.
Distribusi Normal. Lama waktu untuk banyak proses pelayanan mengikutidistribusi normal. Alasan untuk ini adalah bahwa banyak proses yang sebenarnyaterdiri dari sejumlah subproses. Terlepas dari distribusi probabilitas dari setiapindividu subproses, ketika waktu subproses ditambahkan bersama-sama, durasiwaktu yang dihasilkan sering menjadi terdistribusi secara normal. Distribusi normalmemiliki dua parameter: rata-rata dan standar deviasi. Distribusi normal jugasimetris. Nilai rata-rata yang sarna denganjumlah pengamatan kurang dari dan lebihbesar dari rata-rata data. Pola atau distribusi dari pengamatan di masing-masingpihakjuga serupa.
Rumus matematika untuk probabilitas distribusi normal adalah:
f(x) =~ e-(x-~)2/2cr2'LV21t
Di mana JJ adalah nilai rata-rata dan a adalah standar deviasi. Distribusi normalsering dibahas dalam kaitannya dengan distribusi normal standar atau Z. Distribusi Zadalah bentuk khusus dari distribusi normal dimana nilai rata-rata adalah 0 danstandar deviasi adalah 1. Dengan distribusi normal standar 68% dari data yangterletak di antara plus atau minus satu standar deviasi dari nilai rata-rata; 95% daridata yang dapat diamati antara plus atau minus dua standar deviasi dari nilai rata-ratadan 99.7% dari data adalah antara plus atau minus tiga standar deviasi dari nilai rata-
95

rata. Untuk data terdistribusi normal, distribusi normal standar dapat dikonversi kenilai data aktual dengan persamaan berikut:
X=JlTO'Z
di mana ~ adalah nilai rata-ratapopulasiyang sebenamyadan CJ adalah standardeviasi populasi sebenamya. Dalam prakteknya, nilai rata-rata populasi yang benardiperkirakan dengan nilai rata-rata sampel, dan standar deviasi populasi sebenamyadiperkirakan dengan standar deviasi sampel. Ini berarti bahwa, misalnya, jika kitapunya sampel nilai rata-rata 10 dan standar deviasi sampel 2, kita bisa menghitungbatas 68% dari distribusi normal dengan:
8=10-212 = 10 + 2
Jadi kira-kira 68% dari pengamatan himpunan data yang terdistribusi normaldengan rata-rata 10 dan standar deviasi 2 akan berada antara nilai-nilai 8 dan 12.Demikian pula, kita bisa menghitung batas sekitar 95.45% dari pengamatan dengan:
10 - 2 (2) sampai 10 + 2 (2) = 6 - 14
Ini berarti bahwa jika data terdistribusi normal dengan ni1airata-rata 10dan standardeviasi 2, maka 95% dari pengamatan akan berada di antara 6 dan 14.
Menggunakan Tabel Distribusi Normal. Kita juga dapat memanipulasipersamaan ini untuk mengetahui nilai persentase kumulatif tertentu. Ini dilakukandengan penggunaan tabel normal standar atau Z. Ingat kembali pelajaran Statistikadalam menggunakan tabel normal baku.
Sebagai contoh, kita ingin mengetahui nilai 80% dari pengamatan untukdistribusi normal dengan nilai rata-rata 10 dan standar deviasi 2, kita akan ikutilangkah berikut ini:
1. Mencari nilai terdekat di bagian tabel untuk 0.80. Nilai ini ada diurutankesembilan, kolom kelima. Nilai Z yang sesuai dengan baris ini adalah 0 . 8
dari sembilan baris dan 0.04 dari kolom kelima. Dengan demikian nilai Z adalah0.84.
2. Memperolehnilai aktual denganmenghitungx: x = 10+2 x 0.84 = 11.68.
Jadi, 80% dari himpunan data pengamatan yang terdistribusi normal denganrata-rata 10 dan standar deviasi 2 dapat ditemukan di bawah 11.68. Prosedur untuk
96

mencari nilai-nilai yang kurang dari 50% adalah sernpa. Sebagai contoh, kita akanmenggunakan prosedur berikut untuk mencari nilai persentase kumulatif0.39:
1. Misalkan kita hanya memiliki sisi kanan tabel, kita harns mengkonversi nilaipersentase kumulatif. Sebuah kumulatif adalah 0.39 persen dari 0.11 ke kiridari nilai rata-rata. Untuk mengubahnya ke sisi kanan, kita menambahkan0.11+0.50. Sekarang kita bisa mencari nilai kumulatif 0.61. Nilai iniditemukan di baris ketiga, kolom sembilan.Nilai Z yang sesuai adalah 0.28.
2. Memperoleh nilai aktual dengan menghitung x: x = 10 - 2 x 0.28 = 9.44. Iniberarti bahwa untuk himpunan data yang terdistribusi normal dengan rata-rata 10dan standar deviasi 2 bahwa 39% dari pengamatan akan memiliki nilai9.44 atau kurang. Penggunaan tabel distribusi normal adalah penting bagipraktisi. Beberapa prosedur berikutnya memerlukan penentuan apakah suatudistribusi normal atau tidak. Dalam rangka untuk membuat keputusan ini,perlu untuk dapat mengidentifikasi nilai kritis untuk berbagai persentasekumulatif distribusi normal.
Simulasi Penggunaan Distribusi Normal. Ketika menggunakan distribusinormal untuk model penundaan pelayanan, praktisi harns menunjukkan perhatianketika nilai rata-rata waktu layanan kecil. Dalam situasi ini, varians dari data yangdapat menyebabkan nilai kurang dari nilai rata-rata untuk menjadi negatif. Karenawaktu layanan tidak boleh kurang dari nol, praktisi hams memastikan bahwa waktulayanan dihasilkan selama simulasi tidak akan negatif. Untungnya, sebagian besarpaket simulasi memungkinkan praktisi untuk menentukan bahwa nilai-nilai apapunyang dihasilkan oleh distribusi normal dibuangjika mereka negatif.
Contoh proses yang sering dimodelkan dengan distribusi normal meliputipemrosesan manufaktur, waktu pelayanan pelanggan, dan waktu perjalanan.Perhatikan bahwa contoh tersebut adalah proses yang sarna yang mungkin padaawalnya praktisi perkirakan dalam ketiadaan data sebagai distribusi segitiga. Dalamkasus ini, penggunaan distribusi normal kemungkinan besar akan teIjadi sebagaiakibat dari distribusi normal yang cocok dengan data empiris dan bukan sebagaiperkiraan. Tanpa benar-benar melakukan uji kebaikan suai, akan dipertanyakansecara otomatis jika mengasumsikan bahwa sebuah proses berdistribusi normal danbahwa nilai rata-rata dan standar deviasi dapat diperkirakan secara akurat.
Distribusi Poisson. Distribusi Poisson digunakan untuk memodelkanperistiwa acak yang akan teIjadi dalam suatu interval waktu. Distribusi Poissonhanya memiliki satu parameter, A.Distribusi ini adalah unik dalam hal bahwa nilai
97

rata-rata dan varians keduanya sarna dengan A.Probabilitas mengamati nilai tertentuadalah: -A x
P(x)= e A.X!
di mana Aadalah baik nilai rata-rata dan varians dan x adalah nilai dari variabel acak.Simulasi penggunaan distribusi Poisson meliputi jumlah kedatangan dalam suatuinterval waktu danjumlah entitas dalam sebuah batch.
Distribusi Kurang Umum. Distribusi yang kurang umum digunakanmeliputi distribusi Weibull, gamma, beta, dan geometris. Para praktisi diperingatkanbahwa matematika yang terkait dengan distribusi ini dibatasi dalam aplikasisebenarnya ke praktisi. Dalam kebanyakan kasus, distribusi ini akan ditemui hanyasebagai paling cocok dari paket perangkat lunak data terkomputerisasi. Ketikasebuah paket perangkat lunak menunjukkan bahwa distribusi tertentu adalah palingcocok, paket ini juga akan memberikan parameter distribusi yang terkait dengancocok. Praktisi normalnya menggunakan informasi ini untuk memasukkanparameter tersebut ke dalam program simulasi. Meskipun beberapa akanberpendapat sebaliknya, matematika di balik beberapa distribusi yang kurang umumini memiliki arti yang terbatas pada praktisi.
Distribusi Weibull. Distribusi Weibull sering digunakan untuk mewakilidistribusi yang tidak dapat memiliki nilai kurang dari nol. Situasi ini sering adadengan distribusi simetris seperti distribusi normal yang mewakili waktu layananatau proses. Jika nilai rata-rata kecil dan standar deviasi cukup besar, banyakpengamatan akan terakumulasi pada sisi kiri dari distribusi dekat O. Hal inimenghasilkan distribusi tidak simetris. Sisi kanan distribusi masih menampilkanekor distribusi normal klasik.
Distribusi Weibull memiliki dua parameter, yaitu sebuah parameter bentuk adan parameter skala J3.Tergantung pada nilai kedua parameter, Weibull dapatmengambil bentuk mulai dari distribusi eksponensial sampai distribusi normal.Matematika yang terkait dengan distribusi Weibull seharusnya tidak adahubungannya dengan praktisi. Persamaan yang disertakan di sini untuk kepentingankelengkapan. Dalam prakteknya, satu-satunya informasi yang benar-benar praktisiperlu perhatikan adalah parameter a dan J3.Fungsi probabilitas panjang untukWeibull adalah:
F( ) A-a a-I -(x/j3)a tuk >0X =a, X e ,un X
F(x) = 0, untuk lainnyadimana a adalah parameter bentuk dan J3adalahparameter skala.
98

Distribusi Gamma. Distribusi gamma adalah distribusi lain yang mungkinkurang umum bagi praktisi. Distribusi gamma juga dapat agak menakutkan bagipraktisi. Komentar yang sarna dari distribusi Weibull berlaku untuk distribusigamma. Seperti dengan distribusi Weibull, distribusi gamma memanfaatkan sebuahbentuk a dan parameterskala 13. Persamaanprobabilitasdensitasuntuk distribusi
gammaadalah: F(x) = I Xa-1e-xlPx>Orn1a) ,
0, untuk lainnya
Di mana a, 13,dan r didefmisikan sebagai dalam distribusi Weibull. Untungnya,nilai rata-rata dan varians dari distribusi gamma mudah diwakili bleh al3 dan al3secara berturut-turut. Distribusi gamma tidak memiliki salah satu karakteristik yangpotensial menarik minatbagi praktisi.
Dalam keadaan tertentu, distribusi gamma dapat merosot ke representasimatematika yang sarna sebagai distribusi eksponensial. Keadaan ini teIjadi ketikabentuk parameter a kebetulan sarna dengan I. Jika bentuk parameter a mendekati I,maka distribusi eksponensial seperti juga mungkin cocok. Seperti dengan distribusiWeibull, distribusi gamma tidak bisa dibawah O.Ketika bentuk parameter a melebihinilai 2, distribusi gamma dapat mengambil bentuk mirip dengan distribusi Weibull.Ini berarti bahwa distribusi gamma juga mungkin berlaku ketika layanan ataudistribusi proses simetris memiliki nilai rata-rata kecil dan varians besar.
Distribusi Beta. Sebuah persamaan terakhir yang praktisi dapat jumpaiadalah distribusi beta. Distribusi ini sedikit berbeda dari sebagian besar distribusiyang sebelumnya diajukan. Distribusi beta menjadi berbeda karena mampu hanyamencakup rentang antara 0 dan 1. Sementara distribusi sendiri hanya dapat antara 0dan 1, adalah mungkin untuk mengimbangi dan atau membuat skala dengan nilaipengganda. Distribusi beta memiliki dua parameter yang berbeda, yaitu parameterbentuk a dan parameter bentuk 13. Rumus matematika untuk densitas probabilitas
distribusi betaadalah: r(a+f3) 0.-],. /}-IF(x) = x ~1-x) , untuk O<x<1
r(a)r(f3)0, untuk lainnya
Dimana a dan 13 adalah parameter bentuk I dan 2, secara berturut-turut, dan r sarnadengan dalam distribusi Weibull, dan gamma. Nilai rata-rata dan varians daridistribusi beta adalah:
aRata - rata = -
a+af3
Varians = (a+f3)2(a+f3+ 1)
99

-- --
Selain karena kebetulan data yang sesuai dengan distribusi beta, praktisimungkin memang memerlukan distribusi ini karena penting untuk menyesuaikandata yang miring ke kanan daripada kiri seperti pada distribusi Weibull dan gamma.Ini mewakili beberapa waktu maksimum yang dapat diambil untuk proses tertentu.
Distribusi Geometrik. Berbeda dengan distribusi sebelumnya yang kurangumum, distribusi geometrik adalah diskrit. Seperti yang anda ingat, ini berarti bahwanilai-nilai yang diambil oleh distribusi geometrik harns bilangan bulat. Distribusigeometrik memiliki satu parameter p, yang menunjukkan probabilitas keberhasilanpada setiap usaha; (1 - p) adalah probabilitas kegagalan pada usaha tertentu.Probabilitas dari x-I kegagalan sebelum sukses di usaha ke-x diwakili oleh:
P(x) = p (l-pt\ x = 1,2,...
Nilai rata-rata dan varians dari distribusi geometrik diwakili oleh:
Rata - rata = 1-p ; Varians = 1-p- -P 2P
Distribusi geometrik dapat digunakan dalam program simulasiuntuk:1. Ukuran batch kedatangan2. Jumlah item diinspeksi sebelum kegagalan ditemukan
Distribusi geometrik dapat memodelkan ukuran kedatangan batch. Secarakhusus, distribusi geometrik telah digunakan untuk memodelkan secara akuratjumlah orang yang dalam suatu batch di pos pemeriksaan sistem keamanan bandara.Batch merepresentasikan penumpang tunggal, suami dan istri, keluarga dengananak-anak, dan pelancong bisnis dalam kelompok. Untuk ukuran batch kedatangan,kita tertarik pada probabilitas yang diasosiasikan dengan ukuran batch x.Penggunaan lain model distribusi geometris adalah jumlah kegagalan yang adasebelum sukses. Untuk membuat lebih masuk akal dalam sebuah program simulasi,persentase antara keberhasilan dan kegagalan dapat diaktifkan. Jadi, kita akan benar-benar memodelkan jumlah sukses sebelum terjadinya kegagalan pertama.
5.7 Distribusi Kombinasi
Beberapa jenis data input sebenamya merupakan kombinasi komponendeterministik dan probabilistik. Proses jenis ini umumnya memiliki waktuminimum, yang merupakan komponen deterministik. Komponen yang tersisa dariwaktu mengikuti semacam distribusi. Contoh kasus yang menunjukkan distribusikombinasi adalah:
100

-- .--_...--_....
I. Teknisidukungan telepon2. Penggantian olipada mobil3. Siklus sistem manufaktur tleksibel
Dalam sistem dukungan teknis telepon umumnya, jumlah waktu minimumselalu dibutuhkan untuk setiap panggilan. Selama beberapa menit awal, teknisitelepon harns menetapkan siapa pelanggan dan apakah ia berhak untuk dukunganteknis telepon. Jika pelanggan tidak memenuhi syarat dukungan, yang akan menjadijumlah minimum mungkin waktu untuk proses pelayanan. Proses yang stokastikakan mencakup waktu memecahkan masalah yang sebenamya. Catatan bahwadalam kasus seperti ini, praktisi mungkin ingin memodelkan proses kontak sebagaidua proses terpisah: satu untuk menetapkan kualifikasi dan satuuntuk layanan ini.
Dalam kasus penggantian oli mobil, jumlah waktu deterministik minimumyang diperlukan adalah untuk menaikkan dan menurunkan mobiI. Komponenprobabilitas waktu akan melibatkan pembuangan oli lama, penggantian dengan olibarn, dan waktu untuk mengganti filter oli. Sistem manufaktur tleksibel (FMSs)terdiri dari dua atau lebih komputer dikontrol secara numerik (CNC) dan mesin-mesin otomatis yang umum-sistem penanganan bahan. Waktu pemrosesan untukmesin dari komponen dan pengalihan komponen kemungkinan besar akan menjadideterministik karena mereka dikendalikan oleh komputer. Namun, selurnh siklusmasih memerlukan operator manusia pada awalnya untuk memuat komponen padaawal siklus. Demikian pula pada akhir siklus, operator manusia juga akan dimintauntuk membongkar komponen.
5.8Analisis Data Input
Proses penentuan distribusi teoritis yang mendasari untuk suatu himpunan databiasanya melibatkan apa yang dikenal sebagai uji kebaikan suai (Johnson et aI.,1999; Hildebrand dan Ott, 1991). Uji ini didasarkan pada semacam perbandinganantara distribusi data yang diamati dan distribusi teoritis yang sesuai. Jika perbedaanantara distribusi data yang diamati dan distribusi teoritis yang sesuai kecil, makadapat dinyatakan dengan tingkat kepastian bahwa data input bisa berasal dari satuhimpunan data dengan parameter yang sarna dengan distribusi teoritis. Ada empatmetode yang berbeda untuk melakukan perbandingan ini, yaitu (1) pendekatangrafis, (2) khi-kuadrat, (3) uji Kolmogorov-Smimov, dan (4) kesalahan kuadrat.
Pendekatan yang paling mendasar untuk mencoba agar sesuai input dataadalah pendekatan grafis. Pendekatan ini terdiri dari perbandingan visual kualitatif
101

antara distribusi data aktual dan distribusi teoritis dari data yang teramati. Langkah-langkah untuk memanfaatkan pendekatan gratis meliputi:
. Buat histogram dari data yang diamati
. Buat histogram untuk distribusi teoritis
. Bandingkan secara visual kesamaan kedua histogram
. Membuat keputusan kualitatifuntuk kesamaan duahimpunan data
Dalam teknik ini, praktisi pertama-tama hams memutuskan bagaimana luasjangkauan data setiapbar histogram dan berapa banyak baruntuk gratik. Nilai bawahdan atas di masing-masing rentang data membentuk apa yang dikenal sebagai seldata. Jumlah data pengamatan di masing-masing sel digunakan untuk mewakiliketinggian bar histogram. Ada dua pendekatan umum untuk menentukan bagaimanauntuk menangani masalah sel, yaitu (1) pendekatan interval sarna, dan (2)pendekatan probabilitas sarna.
Dalam pendekatan interval yang sarna, praktisi menetapkan lebar sel datasetiap rentang menjadi nilai yang sarna. Ini berarti bahwa praktisi kemudian hanyahams memutuskan berapa banyak sel untuk dimanfaatkan. Jangkauan lengkap darisemua nilai data kemudian dibagi dengan jumlah sel yang akan digunakan. Nilaiyang dihasilkan adalah lebar data setiap rentang. Perhatikan contoh waktu layananberikut. Data input memiliki nilai minimum 4 menit dan nilai maksimum adalah 24menit. Jangkauan lengkap adalah 20 menit. Jika praktisi memutuskan untukmemiliki lima sel, kisaran untuk masing-masing dari lima sel data adalah 4 menit. Iniberarti bahwa sel pertama mencakup antara 4 dan 9 menit, sel kedua antara 9 dan 13menit, dan seternsnya.
Pendekatan interval yang sarna mensyaratkan bahwa praktisi memutuskanberapa banyak sel untuk dimanfaatkan. Meskipun akan ada kemungkinan untukmemutuskan secara acak pada satu nomor, akan lebih baik untuk menurunkanjumlah ini dalam beberapa macam cara rasional. Salah satu pendekatan yang telahdilakukan di masa lalu adalah untuk mengambil akar kuadrat dari jumlah titik data.Nilai yang dihasilkan adalah jumlah sel yang akan digunakan. Dengan jumlah sel,kisaran sel dapat dihitung seperti ilustrasi sebelumnya.
Metode statistik lebih kuat untuk menentukan jumlah sel adalah pendekatanprobabilitas sarna. Dengan metode ini, jumlah sel ditentukan dengan algoritmaberikut:
102

1. Gunakanjumlah sel maksimum tidak melarnpaui 100.2. Jumlah yang diharapkan pengarnatan dalarn setiap sel harus sekurang-
kurangnya 5.
Untuk memanfaatkan pendekatan ini, praktisi pertama-tama perlu untukmembagijumlah total data poin oleh 5. Ini akan menghasilkanjumlah sel yang akandigunakan. Jika jumlah sel lebih besar dari 100, kemudian 100 digunakan untukjumlah sel. Dengan metode ini, ada kemungkinan bahwajumlah titik data tidak akanditerima secara merata oleh 5. Dalam kasus ini, para praktisi dapat membuang datatambahan atau mengurangi jumlah sel data ke angka yang lebih rendah berikutnya.Jika praktisi memutuskan untuk membuang data tambahan, adalah penting untukmemastikan bahwa jumlah sel tidak terlalu kecil. Di sisi lain, jika praktisimembulatkan jumlah sel ke bawah, jumlah pengamatan yang diharapkan dalarnsetiap sel akan berada pada nomor yang merupakan pecahan antara 5 dan 6.
Beberapa ahli statistik tidak akan setuju membuang data, tapi jika adakumpulan data yang cukup besar, pendekatan yang paling sederhana adalahmembuang beberapa titik data untuk memiliki bahkan jumlah sel. Jadi, misalnya,jika ada 52 titik data, harus ada 52 dibagi dengan 5 data sel. Ini adalah 10 sel datadengan 2 titik data yang tersisa. Pendekatan data yang membuang berarti bahwa titikdata 2 terakhir tidak akan digunakan dalamproses penyesuaian distribusi.
Praktisi dapat selalu membulatkan jumlah sel ke bawah, akan tetapi, hal inimungkin menyebabkan tidak semua pengamatan yang diharapkan masuk.Penggunaan nomor bukan keseluruhan jumlah pengamatan yang diharapkan secarastatistik akan lebih kuat. Namun, bisa cukup membingungkan bagi banyak praktisi.Jika pendekatan ini digunakan, maka 52 titik data akan menghasilkan total dari 52dibagi dengan lima sel. Jumlah sel yang dihasilkan adalah lOA. Jumlah seldibulatkan ke bawah sampai 10. Jumlah pengamatan yang diharapkan dihitungdengan membagi 52 dengan 10, berarti bahwa setiap sel akan diharapkan memiliki5.2 pengamatan. Tentu tidak mungkin untuk mengamati potongan 5.2 data dalarnrentang data apapun karena anda tidakbisa memiliki pecahanjumlah pengamatan.
Pendekatan probabilitas sarnamemiliki salah satu karakteristik lain yang dapatmengganggu bagi praktisi pemula. Karakteristik ini adalah hasil dari fakta bahwasetiap sel mungkin sarna secara alami. Ini berarti bahwa setiap sel diharapkanmemiliki jumlah sarna pengarnatan terlepas dari distribusi yang sedang diperiksa.Akibatnya, lebar interval sel data yang berbeda mungkin berbeda.
103
--

---
Grafik Perbandingan dari Sel. Setelahjumlah sel ditentukan, praktisi dapatmemutuskan batas sel untuk setiap sel jika data berasal dari distribusi teoritistertentu. Kemudian praktisi mengamati macam data dan menghitung frekuensipengamatan yang bersesuaian dengan setiap sel. Frekuensi ini digunakan untukmembuat histogram. Langkah terakhir melibatkan perbandingan visual subjektifantara histogram yang diamati dan apa yang mungkin diharapkan dari distribusiteoretis untuk setiap sel.
Sifat subjektif dari perbandingan antara data yang diamati dan teoritis tidakmenghasilkan perbandingan yang kuat. Untuk alasan ini saja, tidak dianjurkanpenggunaan metode grafis untuk membuat kesimpulan tentang kumpulan datatertentu.
Uji Kebaikan Suai Khi-Kuadrat. Khi-kuadrat secara umum diterimasebagai uji kebaikan suai yang lebih disukai. Seperti uji perbandingan grafik, khi-kuadrat didasarkan pada perbandingan jumlah aktual pengamatan versus jumlahpengamatan yang diharapkan. Ini berarti bahwa uji khi-kuadrat probabilitas sarnajuga menggunakan pendekatan untuk menentukan jumlah sel dan batas sel.Langkah-Iangkah dalam melaksanakan uji khi-kuadrat adalah sebagaiberikut:1. Menetapkan hipotesis nol dan altematif2. Menentukan tingkat signifikansi pengujian3. Menghitung nilai kritis dari distribusikhi-kuadrat4. Menghitung uji khi-kuadrat dari data statistik5. Membandingkan uji statistik dengan nilai kritis6. Menerima atau menolak hipotesis nol
Hipotesis nol pada umumnya adalah pemyataan yang menyatakan bahwa datainput bisa berasal dari distribusi teoritis tertentu. Demikian pula, hipotesis altematifadalah pemyataan bahwa. data input tidak mungkin berasal dari distribusi teoritistertentu. Dalam prakteknya, pemyataan hipotesis nol dan altematif yang diringkasmengikuti format berikut:
Ho: Distribusi (parameter 1,parameter 2, ...)Ha: Tidak distribusi (parameter 1,parameter 2, ...)
Distribusi akan dinamai sesuai dengan nama distribusi teoretis sebenamya,dan parameter akan sesuai dengan parameter tertentu yang terkait dengan distribusiteoritis tertentu. Jika kita sedang menguji data layanan yang terdistribusi normal, kitaakan membutuhkan data parameter nilai rata-rata dan standar deviasi. Sebagai
104

contoh, jika kita berpikir bahwa distribusi teoritis itu nonnal dengan rata-rata 5 danstandar deviasi 2,pemyataan hipotesis akan muncul sebagaiberikut:
Ho: Data berdistribusi nonnal (5, 2)Ha:Data tidak berdistribusi nonnal (5, 2)
Menentukan Tingkat Signifikansi Uji. Hal ini diperlukan untukmembangun tingkat keyakinan uji. Sebagai contoh, jika kita ingin yakin 95% darihasil tes, tingkat signiflkansi adalah 0.05. Tingkat signiflkansi sering disebut sebagaitingkat a. Tingkat a umum lainnya 0.01 dan 0.10. Penelitian sosial biasanya tidakmembutuhkan tingkat a yang sangat kecil. Nilai 0.05 atau 0.10 sudah cukup. Tapipenelitian teknik atau eksakta, khususnya kedokteran, membutuhkan tingkat a yangsangat keci!. Tingkat a 0.10 untuk eksaktalteknik bisa terlalu besar.
Menentukan Nilai Kritis untuk Distribusi Khi-Kuadrat. Proses ini terdiridari penentuan nilai kritis khi-kuadrat. Nilai kritis adalah batas antara bagian tidakbennakna dan signiflkan dari distribusi khi-kuadrat. Dengan kata lain, dengantingkat signiflkansi 0.05 merupakan nilai di mana 95% dari distribusi ada di sebelahkiri nilai kritis, sedangkan 5% dari distribusi ada di kanan nilai kritis.
Perhitungan Statistik Uji Khi-Kuadrat dari Data. Uji statistik dihitungdengan cara menjumlahkan hasil kuadrat perbedaan antara data jumlah poin yangdiamati dan jumlah titik data yang diharapkan dibagi dengan jumlah titik data yangdiharapkan untuk setiap individu sel data. Proses ini lebih mudah dijelaskan denganrumus berikut:
X2~ (Oi-Eii
Di mana X2=ujistatistikyangakandihitungdandibandingkandengannilaikritis;Oi=jumlah titik data pengamatan dalam sel ke-i; Ei =jumlah titik data yang diharapkandalam sel ke-i; dann =jumlah sel data.
Untuk setiap sel dalam rumus di atas, praktisi akan mengambil jumlah nilaiyang diamati dalam rentang sel dan mengurangi jumlah nilai yang diharapkan.Angka ini kemudian dikuadratkan. Nilai positif yang dihasilkan dibagi denganjumlah diharapkan sarna dengan nilai yang digunakan sebelumnya. Perhitungan inidibuat untuk setiap sel dalam uji dan dijumlahkan. Nilai yang dihasilkan mengikutidistribusi chi-kuadrat.
105

Pembandingan Uji Statistik dengan Nilai Kritis. Dalam langkah ini, kitamembandingkan uji statistik yang hanya dihitung dengan nilai kritis yang ditentukansebelumnya. Perbandingan dilakukan untuk melihat apakah uji statistik lebih kecildari nilai kritis atau lebihbesar dari nilai kritis.
Jika temyata statistik uji lebih kecil dari nilai kritis, maka hipotesis nol yangmenyatakan bahwa data bisa berasal dari distribusi teoritis tertentu tidak dapatditolak pada tingkat signifikansi yang ditentukan sebelumnya. Sebaliknya, jika nilaistatistik uji lebih besar dari nilai kritis, maka hipotesis nol ditolak. ltu berarti bahwaada bukti yang menunjukkan data tidak datang daridistribusi teoritis yang sarna.
Jumlah Data Minimum untuk Uji Khi-Kuadrat. Salah satu kelemahan ujikhi-kuadrat adalah bahwa hal itu dapat dilaksanakan hanya jika cukup jumlah datayang ada untuk menerapkan uji. Secara umum, kita perlu untuk memiliki palingsedikit 20 titik data agar uji berfungsi secara matematis. Jika hanya 20 titik data yangtersedia, total 4 sel data yang ak~mdigunakan. Ini berarti bahwa minimum titik datayang lebih realistis setidaknya 30. Dengan setidaknya 30 titik data, praktisi dapatmemiliki keyakinan yang wajar akan hasil uji khi-kuadrat. Dalam peristiwa dimanadata yang ada tidak cukup untuk melakukan uji khi-kuadrat, praktisi dapatmempertimbangkan memanfaatkan Kolmogorov-Smimov.
Perhatikan contoh berikut untuk menunjukkan penggunaan uji kebaikan suaikhi-kuadrat. Data di bawah ini diperoleh dari waktu antar kedatangan pelanggan dipusat pelayanan dalam menit. Kami ingin memastikan bahwa distribusi antarkedatangan mengikuti distribusi eksponensial.
Untuk memulai, kita perlu menghitung ringkasan statistik untuk data.Meskipun kita dapat menghitung nilai rata-rata dan standar deviasi data, distribusieksponensial hanya memiliki satu parameter, nilai rata-rata. Nilai rata-rata = 2.31dan standar deviasi = 2.88. Kita memiliki 30 titik data, dan kita akan menggunakanpendekatan yang disarankan kemungkinan sarna. Ini berarti bahwa kita perlumenggunakan total atau 6 sel dalam pengujian kita.
106
0.87 2.57 3.23 3.94 0.06 0.95 2.48 1.43 1.63
15.80 1.50 1.36 3.43 0.25 1.04 5.53 0.54 1.41
2.68 0.80 3.86 2.23 2.00 1.88 2.73 0.17 0.01
0.55 3.48 0.77

Dengan ringkasan statistik, adalah mungkin untuk membuat hipotesis nol danaltematif, yaitu:Langkah 1.Ho:
Langkah2.Langkah 3.
Langkah4.
data berdistribusi eksponensial (2.31). Ha: data tidak mengikutidistribusi eksponensial (2.31).Tingkat signifikansi dipilih sebesar 0.05.Nilaikritiskhi-kuadratuntukderajatbebas(6-1-1)=4.Adaenamsel, satu parameter untuk nilai rata-rata dan tambahan satu derajatkebebasan untuk uji. Menggunakan tabel khi-kuadrat, diperolehnilai kritis 9.49.Kita menghitung persen batas bawah dan atas untuk setiap sel,nilai batas atas dan bawah x untuk setiap sel, dan jumlah yangdiamati dan diharapkan untuk setiap sel. Nilai-nilai di bawah danatas x kolom dihitung dengan menggunakan rumus:
x = -0.97 x In [l-f(x)]
Di mana F (x) adalah persentase kumulatif persentase bawah dan atas kolom. Ujistatistik adalahjumlah dari kolom terakhir,yaitu 0.2 + 0.0 + 0.2 + 0.0 + 1.8+ 1.8=4.0Langkah5. Uji statistik lebih kedl dari nilai kritis pada alfa 0.05, yaitu 4.0
<9.4.Langkah 6. Kesimpulan: Tidak dapat menolak hipotesis no1,dengan kata lain
data berdistribusi secara eksponensial dengan rata-rata 2.31.
Contoh Khi-Kuadrat Distribusi Normal. Uji kebaikan suai khi-kuadratjuga mudah diterapkan untuk distribusi normal. Misalkan kita ingin menguji datawaktu layanan berikut untuk melihat apakah berasal dari distribusi normal.
6.44 5.92 6.88 6.49 9.14 6.68 9.01 4.80 1.77 0.52
3.59 5.10 1.28 7.75 4.90 7.91 6.33 6.44 3.10 7.09
3.59 6.26 4.88 3.68 5.35 3.82 9.37 4.98 7.50 7.39
Ringkasan statistik untuk kumpulan data ini adalah: nilai rata-rata = 5.61,standar deviasi = 2.25, danjumlah data = 30.
Pengujiannya menggunakan perangkat lunak statistic SPSS dan langkah-langkahnya adalah sebagai berikut:
Langkah 1. Ho : data mengikuti distribusi normal (5.61, 2.25). HI : data tidakmengikuti distribusi normal (5.61,2.25).Langkah 2. Tingkat signifikansi (a) :0.05 (sesuai dengan default SPSS)
107

Langkah 3. Nilai kritis :tingkat signifikansi 0.05. TolakHojikanilai P lebihkecil dari0.05.Langkah 4. Perhitungan.
1. Input data ke lembar keIja SPSS.2. Bukamenu "Analyzeq3. Pilih ''Nonparametric Testq4. Pilih "Chi-S.nare& .q5. Masukkan variabel yang akan diuji distribusinya ke kotak "Test Variable
Listq6. Tekan"Okq7. Hasil: Test Statistics
a. 28 cells (100.0 %) have expected fre..uencies lessthan 5. The minimum expected cell fre..uency is 1.1.
Langkah 5. Baca "Asymp. Sig dari tabel di atas dan bandingkan dengan 0.05. Karena1.000 lebih besar dari 0,05, maka terima Ho, artinya data pengamatan mengikutidistribusi normal
Kolmogorov-Smirnov (KS). Uji KS digunakan hanya ketika jumlah titikdata sangat terbatas dan uji khi-kuadrat tidak dapat diterapkan dengan tepat. Alasanuntuk ini adalah bahwa secara umum diterima bahwa uji KS memiliki sedikitkemampuan sesuai data dibandingkan teknik lainnya seperti khi-kuadrat. Sebuahpembatasan akhir uji KS adalah bahwa beberapa referensi merekomendasikanmenggunakan KS dengan distribusi diskrit.
Sebenamya ada banyak versi dari uji ini dengan berbagai tingkatkompleksitas. Untuk diskusi lengkap tentang uji KS, praktisi dapat merujuk ke bukustatistik atau ke buku simulasi Law-Kelton. Versiuji KS yang disajikan dalam bukuini adalah yang paling sederhana untuk diterapkan. Ahli statistik kadang-kadangmengkritik versi uji statistik lemah. Namun, bagi praktisi, perbedaannya mungkintidak signifikan.
108
Waktu layanan
Chi-S. .uarea
1.733
df 27
Asymp. Sig. 1.000

Konsep di belakang uji KS adalah perbandingan antara distribusi kumulatifteoretis dan kumulatif distribusi diamati. Jika perbedaan maksimum antarakumulatif distribusi teoretis dan teramati melebihi nilai kritis, maka distribusi yangdiamati tidakmungkin berasal dari distribusi teoritis KS. Langkah-Iangkah untuk KSadalah:
1. Menetapkan hipotesis nol dan altematif2. Menentukan tingkat signiflkansi pengujian3. Menentukan nilai kritis KS menggunakan tabel4. Menentukan perbedaan mutlak terbesar antara dua distribusi kumulatif5. Membandingkan dengan nilai KSkritis6. Menerima atau menolak hipotesis nol
Seperti dengan uji khi-kuadrat, uji KS dimulai dengan pembentukan hipotesis noldan altematif. Untuk uji KS, kita juga bisa memadatkan hipotesis nol dan altematifsebagai berikut:Ho: Data berdistribusi (parameter 1,parameter 2, ...)Ha: Data tidak mengikuti distribusi (parameter 1,parameter 2, ...)
Dalam cara yang sarna seperti uji khi-kuadrat, juga diperlukan untukmembangun tingkat keyakinan untuk uji KS. Sebagai contoh, jika kita ingin yakin95% dari hasil uji, tingkat signiflkansi adalah 0.05. Nilai kritis untuk uji KS diperolehdari tabel. Tabelmemiliki duaparameter, ukuran sampel dan tingkat signiflkansi.
Dalam menentukan perbedaan kumulatif dua distribusi, plot sederhana dapatdigunakan untuk membantu. Probabilitas kumulatif diplot pada sumbu vertikal, danrentang nilai data diplot pada sumbu horizontal. Untuk distribusi data yang teramati,probabilitas kumulatif adalah jumlah pengamatan yang kurang dari atau sarnadengan nilai data dibagi dengan jumlah pengamatan. Untuk distribusi teoretis,probabilitas kumulatif dapat dihitung secara matematis.
Setelah plot selesai, tujuannya adalah untuk menentukan perbedaan mutlakmaksimal kumulatif probabilitas antara distribusi teoritis dan mengamati. Hal inihanya dilakukan dengan mengurangi nilai distribusi kumulatif. Perbedaan absolutmaksimum dalam probabilitas kumulatif antara teori dan distribusi diamatikemudian dibandingkan.
Jika perbedaan absolut maksimum kurang dari nilai kritis KS, maka hipotesisnol tidak dapat ditolak. Sebaliknya, jika perbedaan mutlak maksimum lebih besar
109
dari nilai kritis KS, maImhipotesis nol ditolak. Jika hipotesis nol tidak dapat ditolak,maka sampel bisa berasal dari distribusi teoritis dengan parameter tertentu. Kalau
tidak, jika hipotesis nol ditolak, maka sampel tidak berasal dari distribusi teoritisdengan parameter tertentu.
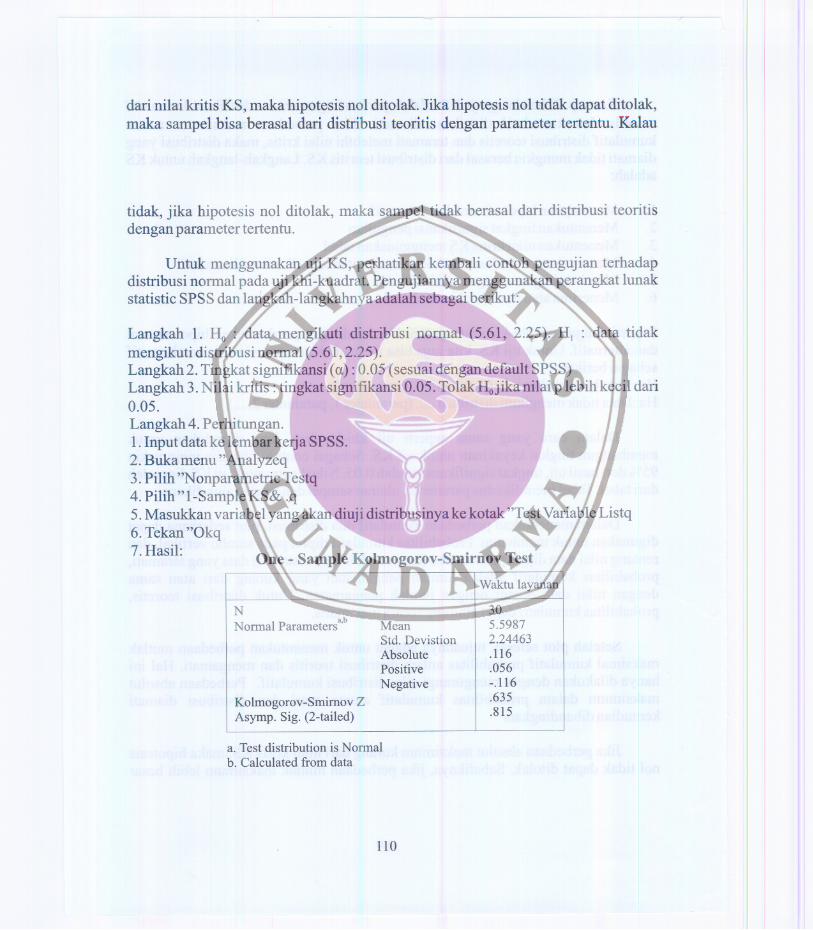
Untuk menggunakan uji KS, perhatikan kembali contoh pengujian terhadapdistribusi normal pada uji khi-kuadrat. Pengujiannya menggunakan perangkat lunakstatistic SPSS dan langkah-Iangkahnyaadalah sebagaiberikut:
Langkah 1. Ho : data mengikuti distribusi normal (5.61, 2.25). HI : data tidakmengikuti distribusi normal (5.61,2.25).Langkah 2. Tingkat signifikansi (a) : 0.05 (sesuai dengan default SPSS)Langkah 3. Nilai kritis :tingkat signifikansi 0.05. TolakHojikanilai p lebih kecil dari0.05.Langkah 4. Perhitungan.1.Input data ke lembar kerja SPSS.2. Bukamenu "Analyzeq3. Pilih "Nonparametric Testq4. Pilih "I-Sample KS& .q5. Masukkan variabel yang akan diuji distribusinya ke kotak "TestVariableListq6. Tekan"Okq7. Hasil:
One - Sample Kolmogorov-Smirnov Test
a. Test distribution is Nonnalb. Calculated from data
110
Waktu layanan
N 30Nonnal Parameters
a,bMean 5.5987Std. Devistion 2.24463Absolute .116Positive .056
Negative -.116
Kolmogorov-Smimov Z.635
Asymp. Sig. (2-tailed).815

Langkah 5. Baca "Asymp. Sig. (2-tailed) dari tabel di atas dan bandingkan dengan0.05. Karena 0.815 lebih besar dari 0,05, maka terima Ho,artinya data pengamatanmengikuti distribusi nonnal.
Kuadrat Kesalahan. Pendekatan kesalahan kuadrat menggunakanpendekatan interval sarna atau pendekatan probabilitas sarna sebelumnya untukmenentukan jumlah sel dan batas-batas sel. Sesuai namanya, pendekatan kesalahankuadrat merupakan total kuadrat dari kesalahan antara yang diamati dan distribusiteoretis. Kesalahan didetinisikan sebagai perbedaan antara dua distribusi untuksetiap individu sel data. Pendekatan kesalahan kuadrat biasanya digunakan sebagaialat untuk menilai kesesuaian relatifberbagai distribusi teoritis yang berbeda untukmewakili distribusi yang diamati. Jadi, distribusi teoretis terbaik akan dianggapsebagai yang memiliki paling kecil penjumlahan kesalahan kuadrat.
5.9 Jumlah Data yang Harus Dikumpulkan
Sebuah pertanyaan yang sangat umum di kalangan praktisi pemulamenyangkut jumlah data yang perlu dikumpulkan. Kemungkinan pertanyaan initampaknya terkait dengan tingkat kesulitan terlibat dengan pengumpulan data.Semakin sulit atau susah mengumpulkan data, semakin besar kemungkinan bahwapertanyaan akan muncul. Ini adalah pertanyaan yang sulit untuk dijawab secaraterpisah, namun pengamatan berikut bisa membantu:
1. Data yang tepat2. Nilai-nilai yang berbeda yang mungkin terjadi3. Kebutuhan untuk memiliki cukup data untuk melakukan uji kebaikan suai
Sebuah prinsip penting pengumpulan data adalah bahwa data tidak boleh biasdengan cara apapun. Sebagai contoh, jika praktisi berupaya mengumpulkan dataantar kedatangan pada suatu restoran selama seminggu, data tidak dapat digunakanuntuk mendorong suatu model yang digunakan untuk memeriksa prosedur staf padaakhir pekan. Jika maksudnya adalah untuk memeriksa kinerja sistem di akhir pekan,maka input datajuga harns dikumpulkan selama waktu yang sarna. Selanjutnya,jikamodel tersebut untuk diperiksa baik untuk hari kerja dan pengaruh akhir minggu,maka keduajenis data harus dikumpulkan.
Isu penting lainnya bahwa praktisi mengumpulkan data yang mungkin cukupberisi lengkap data input yang mungkin ada untuk proses tertentu. Jika nilai ekstrim
111
- - - --

- - - --
tidak diamati tapi benar-benar ada dan merupakan hal penting, maka distribusiteoritis yang dihasilkan mungkin tidak valid. Masalah ini tidak mudah diselesaikanseperti halnya penyelesaian hari kerja atau akhirpekan.
Dalam rangka untuk menyesuaikan distribusi data yang diamati dan teoretis,jumlah minimum data biasanya diperlukan. Meskipun tidak ada angka ajaib,memiliki kurang dari 25-30 titik data dapat mencegah praktisi dari pelaksanakan ujikebaikan suai dengan benar. Ketikajumlah marjinal titik data dikumpulkan, praktisimungkin terpaksa menggunakan analisis yang kurang diminati atau kurang kokoh.Selalu penting bagi praktisi untuk mengambil pendekatan konservatif danmengumpulkan lebih banyak data yang dapat diandalkan. Biasanya jauh lebih sulituntuk kembali dan mengumpulkan data tambahan daripada untuk mengumpulkanjumlah data yang konservatif sejak awal.
5.10Apa Yang Terjadi Jika Data Tidak Dapat Sesuai?
Secara periodik praktisi akan menghadapi situasi di mana data yang diamatitidak sesuai dengan distribusi teoretis. Dengan asumsi bahwa data yangdikumpulkan secara akurat, kemungkinan penyebab kesulitan ini meliputi:1. Tidakcukup data dikumpulkan.2. Data adalah kombinasi dari sejumlah distribusi yang berbeda.
Meskipun praktisi mungkin telah mampu mengumpulkan setidaknya 30 titikdata, tidak ada jaminan bahwa data ini sudah cukup untuk secara akurat sesuaidengan distribusi tertentu. Jadi kecuali terlalu membebani untuk mengumpulkandata tambahan, praktisi harus siap untuk kembali ke sistem dan mengumpulkan lebihbanyak data. Jika tidak mungkin untuk mengumpulkan data tambahan, praktisimungkin mencoba untuk menjalankan simulasi dengan data yang diamati, bukandata distribusi teoritis. Kebanyakan paket simulasi memiliki ketentuan untukkemungkinan ini. Meskipun implementasi distribusi yang diamati ataUdata empirisdapat berbeda-beda, sebuah pendekatan umum dengan menggunakan pendekatandistribusi kumulatif untuk menghasilkan data dapat digunakan.
Kemungkinan lain pada kegagalan menyesuaikan distribusi teoretis adalahbahwa waktu data yang teramati mungkin sebenarnya merupakan kombinasi daribeberapa proses yang berbeda. Proses-proses ini dapat berupa saling eksklusif atauberurutan. Sebuah contoh khas di mana hal ini mungkin terjadi adalah ketika tipeentitas pelanggan membayar barang di meja kasir. Di sini, praktisi mungkin
112

_ __n ___U.._ __ .._ - n -
menggabungkan beberapa waktu pemrosesan berurutan ke satu himpunan data.Proses sebenamya dari sistem kasir terdiri dari:1. Memuat barang pada ban berjalan.2. Memindai barang3. Memasukkan barang ke kantong plastik3. Pembayaran untuk barang
Jika semua proses ini disatukan, kita akan mengabaikan efek bahwa item yanglebih cenderung memakan waktu lebih lama untuk dimuat ke ban berjalan dan untukdipindai. Di sisi lain, pembayaran barang tidak akan diharapkan menjadi fungsi darijumlah barang yang dibeli. Dengan demikian, praktisi mungkin harns memecahproses ini menjadi lebihdari satuhimpunan data untuk memiliki harapan yang masukakal sesuai dengan himpunan data ke dalam distribusi teoretis.
Jenis situasi lain di mana bisa sangat sulit untuk menyesuaikan data yangteramati adalah jika proses eksklusif yang saling berbeda digabungkan. Situasi inimungkin juga akan ditemukan pada contoh kasir yang sarna. Metode pembayaranuntuk barang mernpakan proses saling eksklusif. Artinya, hanya satu jenispembayaran biasanya akan dilakukan, tunai, cek, kredit, atau debit.
Praktisi dapat mengharapkan bahwa transaksi tunai akan mengambil rata-ratawaktu kurang dari transaksi kredit atau debet yang lebih rnmit. Sebuah transaksi cekbahkan mungkin memakan waktu lebih lama daripada transaksi kredit atau debet.
Jika masing-masing jenis pembayaran ini memiliki distribusi teoritis yangberbeda, kemudian praktisi mengabaikannya, maka kemungkinan akan dihasilkandistribusi gabungan yang tidak dapat sesuai dengan salah satu distribusi teoretis.Dalam situasi ini, praktisi harns mengumpulkan data waktu individu untuk masing-masing jenis pembayaran. Perhatikan, bahwa ini secara otomatis dapatmenghasilkan jumlah yang lebih besar secara signiftkan dari pengumpulan data dariawalnya dilakukan. Situasi pengumpulan data sebenamya sedikit lebih buruk.Praktisi juga harns memiliki distribusi tambahan yang menentukan persentase.masing-masing jenis pembayaran yang berbeda. Jika praktisi rajin dalampengumpulan data, adalah mungkin bahwa persentase distribusi jenis juga dapatdikumpulkan pada saatyang sarnasebagai waktu pembayaran.
113

Daftar Pustaka
1. Hoover, Stewart V. Dan Perry, Ronald F. Simulation: A Problem SolvingApproach. Addison-WesleyPublishing-Company, Massachusetts. 1989.
2. Banks, Jerry, Carson II, J. Dan Nelson, B.L. Discrete-Event SystemSimulation. Prentice-Hall International, Inc., London. 1984.
3. Law, Averill M. Dan Kelton, David W. Simulation Modeling and Analysis.McGraw-Hill Inc., Singapore. 1991.
4. Pegden, C. Dennis, Shannon, Robert E. Dan Sadowski, Randall P.Introduction to Simulation Using SIMAN. McGraw-Hill, Inc., Singapore.1995.
5 Ronald E. Walpole. Probability Y Statistics for Engineers Y Scientists.Prentice Hall.
6. Hildebrand, D.K. and Ott, L. Statistical Thinkingfor Managers, PWS-Kent,Boston. 1991.
7. Johnson, R.A., Freund, J.E., and Miller, I. Miller and Freund's Probabilityand Statistics for Engineers, Pearson Education, New' ork. 1999.
8. Bowerman, Bruce and 0 Connell, Richard T. Applied Statistics: ImprovingBusiness Processes. Irwin Professional Publishing, USA. 1997.
9. Walpole, Ronald E. Probability & Statistics for Engineers and Scientist.Prentice Hall. 2002.
114