the anatomy of a large-scale hypertextual web search engine nama ahli kumpulan : chew wan yun a97128...
Post on 19-Dec-2015
227 views
TRANSCRIPT
The Anatomy of a Large-Scale Hypertextual Web Search Engine
Nama Ahli Kumpulan :
Chew Wan Yun A97128
Seng Shwu Shyan A97275
Teaw Poh Suan A97307
Lim Cindy A97231
Ong Mei Huey A97267

GoogleGoogol, 10100
Membina engine gelitar yang berskala besar

Matlamat Rekabentuk
Menaikkan kualiti gelitarMembantu dalam perkembangan dan
pemahaman bagi segi akademikMembina sistem yang boleh digunakan
oleh orang ramaiMembina satu senibina yang boleh
memberi sokongan kepada aktiviti-aktiviti pencarian novel atas web-data yang berskala besar

Google ada dua sifat-sifat yang boleh digunakan untuk menghasilkan keputusan (results) yang tepat.Antaranya ialah
1.Page Rank - menggunakan link structure untuk mengira
ranking bagi setiap webpage secara berkualiti.2.Anchor Text - menggunakan link untuk memperbaiki
keputusan pencarian.

Page Rank : Memberi susunan kepada web
Apa itu Page Rank? sebenarnya page rank adalah salah satu cara
bagi google untuk memutuskan sama ada sesuatu web page adalah berkaitan atau penting.
ia hanya salah satu factor yang memutuskan kedudukan (ranking) satu web page dalam keputusan pencarian ( search results).

Penghuraian bagi pengiraan page rank. Page rank dinyatakan seperti berikut: Kita menganggap bahawa page A mempunyai pages sebanyak
T1……Tn yang menunju kepadanya. Parameter d adalah kebarangkalian link secara rawak ( damping factor) yang boleh disetkan di antara 0 hingga 1. tetapi kita menganggap d sebagai 0.85. C(A) pula adalah bilangan link yang keluar daripada page A. Page rank bagi page A adalah diberikan seperti berikut:
PR(A) = (1-d) + d(PR(T1)/C(T1) + ….+PR(Tn)/C(Tn))
Diberitahu bahawa page rank membentuk satu kebarangkalian bagi pembahagian dalam keseluruhan web pages , maka jumlah page rank adalah satu.

Penentuan secara intuitif ( intuitive justification) Page Rank adalah satu model yang “user behavior”. Kita menganggap bahawa terdapat satu pengguna yang
merupakan “ random suffer” dan sentiasa klik sahaja untuk links ke pages yang lain dan tidak benar “hitting back” sehingga akhirnya berasa boring dan mula dengan satu page rawak yang lain.
Kemungkinan bagi pengguna melawat page secara rawak dipanggil page rank.
D sebagai damping factor ialah kebarangkalian link secara rawak bagi pages yang menyebabkan pengguna itu berasa boring dan meminta ke page rawak yang lain.

satu page boleh ada page rank yang tinggi (high page rank) jika ada banyak pages yang menunju kepadanya.

Anchor text Merupakan link-link yang berkaitan dengan query
walaupun crawler belum melawati web itu. Text yang dilinkkan dianggap sebagai satu perkara yang
unik dalam search engine. Ia menghubungkan page yang dilinkkan olehnya. Dengan menggunakan kaedah anchor text , terdapat
beberapa kebaikkan. Antaranya membekalkan dengan lebih tepat ciri-ciri bagi satu web
page berbanding dengan pages itu sendiri. ia mungkin juga wujud dalam dokumen yang tidak boleh
diindekskan oleh enjin gelintar yang hanya berdasarkan text sahaja. Contohnya adalah seperti images, program dan pangkalan data.
ia mendapat semula web pages yang tidak dapat craw pada mulanya

World wide web worm membina anchor text kepada page yang dirujukan kerana ia banyak membantu dalam pencarian non-text maklumat dan mengembangkan kawasan pencarian dengan memuat turunkan sesetengah dokumen.
Kita menggunakan anchor text kerana ia membolehkan kita mendapat results yang lebih berkualiti.

Related Work
Word Wide Web Worm(wwww) merupakan salah satu perintis dalam sejarah enjin gelintar.
Dengan ini, beberapa enjin gelintar akedemik juga mula diperkenalkan termasuk enjin gelintar jenis syarikat awam(public company).
Contohnya: Lycos, Yahoo

Related Work
Menurut ketua scientis Lycos, Micheal Mauldin “Pelbagai perkhimatan yang disediakan dalam enjin gelintar adalah dibawah kawalan database yang ketat”.
Tetapi usaha-usaha dalam kawalan database ini telah dianggap kurang efektif.
Kini, terdapat pelbagai kerja penyelidikan dalam sistem pengubahsuian informasi(Information retrieval system) terutamanya terhadap koleksi bawah kawalan(well controlled collections) telah dijalankan untuk mencari penyelesaian terbaik.

Information Retrieval
Walaupun pelbagai jenis penyelidikan telah dijalankan, kebanyakan kerja penyelidikan memberi tumpuan kepada koleksi homogeneous.
Seperti kerja-kerja saintifik dan berita-berita dalam topic yang berkaitan sahaja.
Tambahan lagi, benchmark yang digunakan oleh information retrieval system yang dipanggil “Text Retrieval Conference(TREC96)” adalah 20GB; memandangkan kira-kira 24million web-web yang berada di seluruh dunia adalah 47GB.

Information Retrieval
Jadi, ini menjadikan berlakunya pencarian maklumat yang kurang efektif.
Contohnya, kalau kita “key in”kan kata kunci ‘Bill Clinton’ kepada enjin gelintar untuk mencari biodata Bill Clinton, kemungkinan besar kita akan dapat web-web yang tidak berkaitan seperti “Dreamt-man like Bill Clinton”, “Woman behind Bill Clinton” dan sebagainya.
Jadi, kerja-kerja penyelidikan untuk meningkatkan kualiti sistem ini adalah amat diperlukan.

Differences Between the Web and Well Controlled Collections
Web meliputi koleksi-koleksi dokuman yang luas dan tidak dikawal bawah mana-mana agen.
Dokumen-dokumen yang berada di web adalah berlainan mengikut bahasa, perbendaharaan kata, jenis dokumen, format dan kadang-kala dioperasikan oleh agen enjin gelintar.
Manakala ‘Well Controlled Collection’ adalah koleksi di bawah kawalan oleh agen yang dikuatkuasakan.
Kefeksibelan isi-isi dokumen dalam web adalah tidak terhad. Orang ramai mempunyai kebebasan yang besar untuk mengunakan penciptaan teknologi yang canggih ini untuk kemudahan sendiri.

Differences Between the Web and Well Controlled Collections
Namun, kemudahan fleksibel ini kadang-kala menjadi punca kesalahgunaan enjin gelintar ini demi nafsu manusia.
Contohnya, menggunakan web dalam enjin gelintar untuk mendapat keuntungan, menyebarkan ideologi politik tertentu dan sebagainya.
Well controlled collection dikatakan kurang mengalami masalah-masalah tersebut.
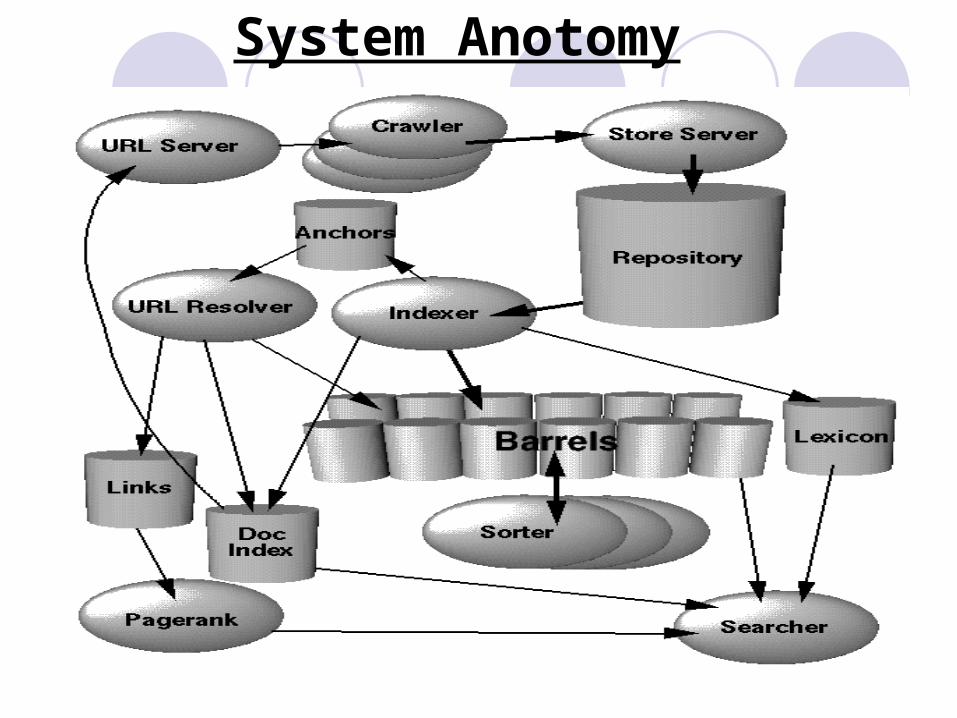
System Anotomy

Major Data StructuresBig Files
virtual files spanning multiple file sistem dan addressable dengan 64 bit integers.
Allocation among multiple file sistem adalan dilakukan secara automatik.
Juga handles allocation dan deallocation of file descriptors.
Juga support basic compression option.

Repository
Mengandungi HTML yang lengkap bagi setiap web page.
Setaip page adalah compressed dengan zlib.
Dokumen disimpan satu demi satu dan disusun mengikut docID,length dan URL.

Dokumen Index
Menyimpan informasi ttg setiap dokumen. Tetap width ISAM(Index Sequential Access Mod
e)index,ordered by docID. Informasi yang disimpan dalam setiap entri term
asuk status dokumen,pointer yg point ke repository,document checksum dan various statistic.
Jika dokumen itu telah crawled sebelum ini,ia juga mengandungi satu pointer yg point ke satu variable width file yg dipanggil docinfo.

Lexicon
Boleh simpan lexicon dalam memory pada satu mesin dengan 256MB drpd memory utama.
Lexicon masa sekarang mengandungi 14 million perkataan
Implementasi dalam 2 bahagian: senarai perkataan a hash table of pointers.

Hit lists Correspond terhadap senarai occurences of a
particular word pada dokumen yg tertentu . Mengira bil space yg digunakan dalam kedua-
dua forward dan inverted indices. Penting untuk mewakili mereka dengan berkes
an. Beberapa alternatives utk encoding, font dan c
apitalization:a) Simple encoding (a triple of integers)b) Compact encoding (a hand optimized allocation of bit
s)c) Huffman coding
2 jenis hit:a) fancy hitb) Plain hit

Forward Index
Sebahagian drpdnya sudah sorted.Simpan dalam number of barrelsSetiap barrel memegang satu jajar wordID’
sJika satu dokumen yg mengandungi perka
taan “fall” dalam barrel yg tertentu,docID akan record ke dlm barrel, diikuti dgn senarai wordID’s bersamaan dgn hit lists yg correspond terhadap perkataan tersebut.

Inverted Index
Mempunyai barrel yg sama seperti forward index,kecuali mereka telah diproses oleh sorter.
Bagi setiap wordID yg sah,lexicon mengandungi satu pointer ke barrel di mana wordID falls into. Ia points kpd satu doclist bg docID bersama dgn corresponding hit list.

Crawling The Web Satu URL server serve senarai URLs kepada nombor c
rawler (Google biasanya lebih kurang 3) Kedua-dua URL server dan crawlers adalah diimpleme
ntasi di Python. Setiap crawler simpan lebih kurang 300 connections op
en at once. Satu major performance stress adalah DNS lookup. Setiap crawler memelihara dia sendiri DNS cache supa
ya ia tidak perlu buat satu DNS lookup sebelum crawling setiap document.
Setiap beratus connection boleh jadi satu nombor yang berlainan keadaan: looking up DNS, connecting to host, sending request dan receiving respone.

Indexing The Web
Parsing Parser yang direka untuk run entire web mesti h
andle satu array besat yang mungkin berlaku errors.
Google gunakan flex untuk generate satu lexical analyzer di mana google menyediakan sendiri punya stack.
Pembangunan parser ini untuk dilarikan (run) pada laju yang sapatutnya dan robust melibatkan kerja yang banyak.

Indexing Documents into Barrels
Encoded ke satu barrels.Setiap perkataan converted ke wordID den
gan menggunakan satu in-memory hash table,iaitu lexicon.
Sebaik saja perkataan itu telah converted ke wordID’s,occurrences pada document yang berkenaan translated ke hit lists dan dituliskan kepada forward barrels.

Sorting
Sorter mengambil setiap forward barrels dan sorts dengan wordID untuk menghasilkan satu inverted barrel untuk tajuk dan anchor hits dan satu full text inverted barrel.
Proses ini dilakukan satu barrel pada satu masa,jadi ia memerlukan satu temporary storage.

Searching
The Rangking System Setiap hit lists termasuk informasi tentang positi
on, font dan capitalization. Faktor dalam hits dari anchor text dan PageRan
k document. Bergabung semua informasi ini ke dalam satu ra
nk adalah sangat susah. Jadi google design satu fungsi rangking supaya
tiada particular factor memberi kesan yang banyak.
Bertimbang pada simplest case—satu single word query. Disamping rank satu document dengan satu single word query, Google melihat pada document hit list untuk perkataan itu.

Feedback Fungsi rangking mempunyai banyak parameter sepert
i type-weight dan type-prox-weight. Adalah susah untuk member nilai yang betul untuk pa
rameter ini. Oleh itu Google menyediakan satu user feedback me
chanism dalam enjin gelintar. Trusted user optional menilaikan keputusan yang diha
silkan. Feedback ini adalah saved. Kemudian modify fungsi rangking an boleh melihat ke
san bagi perubahan pervious searchers yang telah ranked sebelum ini.
Walaupun ini adalah tidak begitu sempurna tetapi ini telah memberikan idea kepada Google bagaimana perubahan pada fungsi rangking memberi kesan kepada search results.

Results and Performance
Penilaian enjin gelintar yang paling penting ialah qualiti keputusan pencarian.
Google menggunakan PageRank, anchor text, and proximity supaya mendapat keputusan yang lebih tepat.

Storage Requirements
Jumlah saiz repository adalah lebih kurang 53GB disebabkan oleh compression, saiz ini cuma 1/3 daripada jumlah data yang distor.
Semua data yang digunakan oleh enjin gelintar memerlukan lebih kurang 55GB.
Tambahan pula, kebanyakan queri boleh dijawab dengan menggunakan short inverted index.
Dengan encoding dan compression dokument index yang baik,sebuah enjin gelintar yang berkualiti tinngi boleh dimuat dalam drive 7GB.

Storage Statistics
Total Size of Fetched Pages
147.8GB
Compressed Repository 53.5GB
Short Inverted Index 4.1GB
Full Inverted Index 37.2GB
Lexicon 293MB
Temporary Anchor Data
(not in total)
6.6GB
Document Index Incl.
Variable Width Data
9.7GB
Links Database 3.9GB
Total Without Repository
55.2GB
Total with Repository 108.7GB
Web Page Statistics
Number of Web Pages Fetched
24 million
Number of Urls Seen 76.5 million
Number of Email Addresses
1.7 million
Number of 404’s 1.6 million

System Performance
Adalah penting untuk enjin gelintar untuk crawl dan index dengan cekap.
Dengan ini, maklumat boleh dikemaskini dan perubahan major sistem boleh dikesan dengan cepat.
Bagi Google, operasi major ialah crawling, indexing, dan sorting. Adalah sukar untuk menentukan berapa masa diambil untuk
crawling atas beberapa sebab seperti disk telah dipenuhi, nama server crashed, atau masalah lain yang memberhentikan sistem.
Ia mengambil 9 hari untuk download 26 million muka surat. Akan tetapi, apabila sistem dilarikan dengan lancar, ia boleh download dengan lebih cepat.

Google melancarkan indexer dan crawler pada masa yang sama, tetapi indexer dilancarkan lebih cepat daripada crawler kerana Google menghabiskan lebih masa untuk optimizing indexer supaya ia tidak menjadi bottleneck.
Optimization ini termasuklah update dokument index dan penempatan struktur data kritikal pada local disk.
Indexer run kira-kira 54 muka surat per saat. Sorters boleh dilancarkan secara selari dengan
menggunakan empat mesin, proses sorting mengambil masa 24 jam.

Search Performance
Versi semasa Google menjawab queri dalam masa 1 hingga 10 saat.
Masa ini banyak dipengaruhi oleh disk IO atas NFS
Google tidak mempunyai sebarang optimization seperti query caching,subindices on common terms dan common optimization yang lain.
Google boleh dicepatkan melalui distribution dan perkakasan, perisian dan peningkatan algorithma.

Initial Query Same Query Repeated (IO mostly cached)
Query CPU
Time (s)
Total
Time (s)
CPU
Time (s)
Total
Time (s)
al gore 0.09 2.13 0.06 0.06
vice president 1.77 3.84 1.66 1.80
hard disks 0.25 4.86 0.20 0.24
search engines 1.31 9.63 1.16 1.16

Conclusion
Google direkabentuk untuk menjadi sebuah enjin gelintar yang scalable.
Tujuan utamanya ialah menjanakan keputusan pencarian yang berkualiti tinngi.
Google menggunakan beberapa teknik untuk meningkatkan kualiti pencarian. Ini termasuklah PageRank, anchor text dan proximity information.
Selain itu, senibina Google adalah lengkap untuk mengumpul web pages, indexing mereka, dan melaksanakan queri atas mereka.