skripsi - sitedi.uho.ac.idsitedi.uho.ac.id/uploads_sitedi/f1a112019_sitedi_skripsi... · risda ummi...
TRANSCRIPT

PEMODELAN KEMISKINAN DI PULAU SULAWESI DENGAN
STRUCTURAL EQUATION MODELING-PARTIAL LEAST SQUARE
SKRIPSI
Untuk memenuhi sebagian persyaratan
mencapai derajat sarjana (S-1)
RISDA UMMI KALSUM
F1A1 12 019
PROGRAM STUDI MATEMATIKA
JURUSAN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS HALU OLEO
KENDARI
2016


iii
KATA PENGANTAR
Puji syukur kehadirat Allah Subhanahu Wa Ta’la yang telah
melimpahkan segala rahmat dan hidayah-Nya, sehingga skripsi yang berjudul
“Pemodelan Kemiskinan di Pulau Sulawesi dengan Structural Equation
Modeling-Partial Least Square” dapat terselesaikan sebagaimana mestinya.
Tugas akhir ini merupakan persyaratan dalam penyelesaian tahap pendidikan
sarjana S-1 pada Jurusan Matematika Fakultas Matematika dan Ilmu Pengetahuan
Alam Universitas Halu Oleo.
Penulis menyadari jika seluruh rangkaian kegiatan, dimulai dari awal
penyusunan hingga penyelesaian tugas akhir ini, senantiasa mendapat bantuan,
bimbingan, dan arahan dari berbagai pihak. Oleh karena itu, penulis mengucapkan
terima kasih yang sedalam-dalamnya kepada Bapak Dr. Ruslan, M.Si. Selaku
pembimbing I dan kepada Ibu Agusrawati, S.Si., M.Si selaku pembimbing II,
yang telah meluangkan waktu, pikiran, dan perhatian dalam penulisan skripsi ini.
Karya ini secara khusus penulis persembahkan untuk keluarga tercinta,
Ayahanda Rusli dan Ibu Nur Aiyda yang tak pernah berhenti memberikan
untaian do’a dan kasih sayang yang tulus serta dukungan moral maupun moril
kepada penulis. Kakakku (Muh. Hairul Ramadhan) dan adik-adikku (Irvina
Nurnaningsih, Muh. Shafril Rusli, Muh. Syahrir Rusli, Muh. Satria Rusli,
dan Muh. Setiawan Rusli) yang selalu mengalirkan semangat buat penulis.

iv
Rasa terima kasih juga penulis ucapkan kepada :
1. Rektor Universitas Halu Oleo.
2. Dekan Fakultas MIPA Universitas Halu Oleo.
3. Ketua Jurusan Matematika Fakultas MIPA Universitas Halu Oleo.
4. Sekretaris Jurusan Matematika Fakultas MIPA Universitas Halu Oleo.
5. Kepala Laboratorium Komputasi Matematika Fakultas MIPA.
6. Bapak La Gubu, S.Si., M.Si., Bapak Dr.rer.nat. Wayan Somayasa,
M.Si., serta Ibu Lilis Laome, S.Si., M.Si., sebagai penguji yang telah
memberikan masukan dalam seminar tugas akhir.
7. Seluruh staff pengajar FMIPA Program Studi Matematika Universitas
Halu Oleo yang telah memberikan bekal ilmu kepada penulis.
8. Seluruh staff tata usaha FMIPA Universitas Halu Oleo.
9. Seluruh staff perpustakaan FMIPA Universitas Halu Oleo.
10. Bapak dan Ibu guru di SDN 03 Kendari Barat, SMP 2 Kendari & SMA
Kartika VII-2 Kendari.
11. Seluruh Keluarga Besarku yang telah memberikan Support.
12. My Best Friends “The Gank (TG)” : Mergar, Rusianti, Nisrina
Nasrun, S.Mat, Nella Aprilya Nurkaidah, S.Mat, Vivi Olivia Oktavia,
Yeni Marinda, S.Mat, Evi Musfira, Agustima, Rianto, S.Mat, Rahim
Indra Sadiq, S.Mat, Syech Muh. Syam A., S.Mat, A. Rivaldy Laurens
SL, Yacobus, Rahmadin La Oga, S.Mat, Iham Yunus, Iksan Jaya.
Terima kasih sudah menjadi sahabat yang merangkul, memberi semangat
dan mau menerima segala kekurangan Penulis selama 4 tahun ini.

v
13. Teman-teman sekolahku: Novianti, S.KM, Fitriani Foly, Retno, Wiwien
Afriani, Dila Wahyuni, Nur Atiyah Hafid, Wulandari Aswan, Salmia
Taudi, Teni Irawati, Siti Yuyun Andriani, Meriyani Yunus, Nikita
Emmanuella, dan yang tak dapat saya sebutkan satu per satu.
14. Teman-teman KKN Desa Sanggi-Sanggi Kec. Palangga Kab. Konawe
Selatan “Kue Kamvret” : Iken Fharida, Ilmaya, Hawaida, Wa Ode
Nurmin, Asa Hari Wibowo, Suardi, La Ode Ijo, Sumarlin, Harun,
Fadli Wiranata.
15. Senior-Senior Math 09, 010, 011 : Suparno S.Si, Gusti Arviana Rahman
S.Si, Ismail Jafar S.Si, Hardiansyah Husein S.Si, Abdul Rajab S.Mat,
Kasliono S.Mat, Kalfin S.Mat, Edicun Baharudin S.Mat, Wayan Eka
S.Mat, Muh. Syafar Kasim S.Mat dan senior yang tak dapat saya
sebutkan satu per satu.
16. Teman-teman math 012 : Jakrin, Andarwan, Nansi, Saru, Fia, Rosni,
Cika, Mimink, Novi, Dian, Egi, Pebi, Sulas, Riski, Rida, Wasno, Evi,
Akwal, Ana, Musdalifa, Merni, Galih, Windi, Igo, Jendri, Fuad,
Sandi, Dani, Bertin, Obil, Ela, Astri, Yani, Kadek, Wiwin, Eka dan
yang tak dapat saya sebutkan satu per satu.
17. Adik-adik math 013, 014, 015 : Adrun, Rima, Indah, Fitri, Rahma,
Mail, Thesa, Noni, Guslan, Iki, Midun, Yoram, Fitriani, Farida dan
yang tak dapat saya sebutkan satu-persatu.

vi
Penulis menyadari bahwa tugas akhir ini masih jauh dari kesempurnaan
karena hanya Allah SWT yang Maha Sempurna. Oleh karena itu dengan Segala
kerendahan hati penulis mengharapkan kritik dan saran yang membangun untuk
perbaikan tulisan ini. Penulis berharap tugas akhir ini dapat bermanfaat bagi diri
penulis dan pembaca serta berguna dalam pengembangan ilmu pengetahuan.
Kendari, September 2016
Penulis

vii
DAFTAR ISI
HALAMAN JUDUL ......................................................................................... i
HALAMAN PENGESAHAN .......................................................................... ii
KATA PENGANTAR ..................................................................................... iii
DAFTAR ISI ................................................................................................ ... vii
DAFTAR GAMBAR ........................................................................................ x
DAFTAR TABEL ........................................................................................... ix
DAFTAR LAMPIRAN .................................................................................... x
ABSTRAK ....................................................................................................... xi
ABSTRACT ................................................................................................... xiv
BAB I PENDAHULUAN
1.1 Latar Belakang ................................................................................... 1
1.2 Rumusan Masalah ............................................................................. 2
1.3 Tujuan Penelitian ............................................................................... 3
1.4 Manfaat Penelitian ............................................................................. 3
BAB II TINJAUAN PUSTAKA
2.1 Matriks ............................................................................................... 4
2.1.1 Penjumlahan dan Pengurangan Matriks ................................ 4
2.1.2 Perkalian Matriks ................................................................... 5
2.1.3 Matriks Data Multivariat ....................................................... 6
2.1.4 Vektor Mean, Matriks Kovariansi dan Matriks Korelasi Data
Sampel ................................................................................... 7
2.1.5 Vektor Mean, Matriks Kovariansi dan Matriks Korelasi Data
Populasi .................................................................................. 8
2.2 Regresi Linier Ganda ....................................................................... 10
2.3 Structural Equation Modeling (SEM) ............................................. 11
2.3.1 Variabel Laten dan Variabel Terukur .................................. 12
2.4 Partial Least Square ....................................................................... 13
2.5 Structural Equation Modeling-Partial Least Square (SEM-PLS) .. 16
2.5.1 Notasi SEM-PLS ................................................................. 17
halaman

viii
2.5.2 Langkah-langkah Analisis PLS ........................................... 18
2.5.3 Estimasi Parameter SEM-PLS ............................................. 26
2.6 Metode Bootstrap ............................................................................ 33
2.7 Kemiskinan ...................................................................................... 35
2.7.1 Persentase Penduduk Miskin ............................................... 39
2.7.2 Indeks Kedalaman Kemiskinan ........................................... 39
2.7.3 Indeks Keparahan Kemiskinan ............................................ 40
BAB III METODE PENELITIAN
3.1 Waktu dan Tempat........................................................................... 41
3.2 Sumber Data .................................................................................... 41
3.3 Identifikasi Variabel ........................................................................ 42
3.4 Prosedur Peneitian ........................................................................... 43
BAB IV HASIL DAN PEMBAHASAN
4.1 Penyajian Diagram Jalur .................................................................. 45
4.2 Evaluasi Model Pengukuran (Outer Model) .................................... 49
4.3 Uji Validitas dan Reliabilitas pada Outer Model............................. 50
4.3.1 Validitas Konvergen ............................................................ 51
4.3.2 Validitas Diskriminan .......................................................... 52
4.3.3 Validitas Reliability ............................................................. 54
4.4 Persamaan Struktural/Inner Model .................................................. 55
BAB V PENUTUP
5.1 Kesimpulan ...................................................................................... 58
5.2 Saran ................................................................................................ 59
DAFTAR PUSTAKA
LAMPIRAN

ix
DAFTAR GAMBAR
Gambar 2.1 Model Indikator Refleksif & Model Indikator Formatif ........ 15
Gambar 2.2 Model PLS SEM ..................................................................... 16
Gambar 2.3 Hubungan antar Variabel dan Indikator dalam Model PLS .... 17
Gambar 2.4 Diagram Alur Algoritma PLS ................................................. 18
Gambar 2.5 Skema Algoritma Standar Error Bootstrap ............................ 35
Gambar 3.1 Diagram Jalur (Path Diagram) ............................................... 43
Gambar 4.1 Model Persamaan Struktural dengan SEM-PLS ..................... 44
Gambar 4.2 Outer Model (a) ....................................................................... 48
Gambar 4.3 Outer Model (b) ....................................................................... 49
Gambar 4.4 Inner Model ............................................................................. 54
halaman

x
DAFTAR TABEL
Tabel 3.1 Variabel Laten dan Indikator ...................................................... 42
Tabel 4.1 Nilai Faktor Loading ................................................................... 50
Tabel 4.2 Nilai AVE ................................................................................... 51
Tabel 4.3 Nilai Cross Loading .................................................................... 53
Tabel 4.4 Uji Signifikansi t-statistik Bootstrap 500 .................................... 53
Tabel 4.5 Composite Reability dan Cronbach Alpha .................................. 54
Tabel 4.6 Nilai Koefisien Analisis Jalur ..................................................... 55
Tabel 4.7 R-square ...................................................................................... 57
halaman

xi
DAFTAR LAMPIRAN
Lampiran 1 Data ............................................................................................62
Lampiran 2 Skrip Program ............................................................................65
halaman

xii
PEMODELAN KEMISKINAN DI PULAU SULAWESI DENGAN
STRUCTURAL EQUATION MODELING-PARTIAL LEAST SQUARE
Oleh:
RISDA UMMI KALSUM
F1A112019
ABSTRAK
Structural Equation Modeling (SEM) merupakan teknik statistika yang kuat
dalam menetapkan model pengukuran dan model struktural. Salah satu aspek atau
kajian yang dapat diselesaikan dengan SEM adalah Kemiskinan. Kemiskinan
selain dapat dilihat dari dimensi ekonomi juga dapat dilihat dari dimensi sosial,
dimensi pendidikan dan dimensi kesehatan. Penelitian ini menggunakan model
SEM dengan pendekatan partial least square (PLS) pada data kemiskinan dengan
variabel laten kemiskinan, ekonomi, SDM dan kesehatan. Setelah dilakukan
analisis didapatkan hasil bahwa seluruh indikator signifikan terhadap konstruk.
Nilai R-square untuk kemiskinan di Pulau Sulawesi adalah 51,30%, maksudnya
ekonomi, SDM, dan kesehatan mampu menjelaskan kemiskinan sebesar 51,30%
berarti ada faktor lain sebesar 48,70% yang tidak masuk dalam model yang
dijelaskan oleh error.
Kata Kunci: Kemiskinan, Partial Least Square, Structural Equation Modeling,
SEM-PLS

xiii
MODELING POVERTY IN CELEBES ISLAND WITH
STRUCTURAL EQUATION MODELING-PARTIAL LEAST SQUARE
By:
RISDA UMMI KALSUM
F1A112019
ABSTRACT
Structural Equation Modeling (SEM) is a robust statistical technique in
determining measurement model and structural model. One aspect that can be
solved by using SEM is poverty. Poverty aside can be seen from social, education,
and healt dimension. This research use SEM with Partial Least Square (PLS)
approach on data of poverty with latent variable poverty, economy, human
resources and health. After conducting analysis it is obtained that all indicator is
significant to manifest. R-square value for poverty in Celebes island is 51,30%,
means economy, human resources, and health are capable to explain poverty value
which is 51,30%. From here it is known there are other factors that is 48,70%
which is not included in the model and explained by error.
Keywords: Poverty, Partial Least Square, Structural Equation Modeling, SEM-
PLS

BAB I
PENDAHULUAN
1.1 Latar Belakang
Salah satu permasalahan yang harus dihadapi dan diselesaikan oleh
pemerintah Indonesia saat ini adalah kemiskinan. Permasalahan tersebut timbul
akibat semakin meningkatnya keadaan ekonomi yang tidak disesuaikan dengan
kondisi masyarakat. Khususnya masyarakat menengah kebawah. Ini juga
merupakan salah satu permasalahan yang ada di Pulau Sulawesi. Secara nasional
Gorontalo dan Sulawesi Tengah termasuk ke dalam 10 Provinsi dengan angka
kemiskinan tertinggi di Indonesia. Persentase penduduk miskin di Sulawesi
Tengah sekitar 13,61%, sedangkan Gorontalo sekitar 17,41%. Persentase
kemiskinan di Sulawesi Selatan sekitar 10,32%, Sulawesi Utara 8,26%, Sulawesi
Tenggara mencapai 11,37%. Dengan beberapa faktor penyebab masyarakat dapat
dikatan ke dalam kategori miskin.
Structural Equation Modeling (SEM) merupakan suatu teknik statistik yang
memiliki pola hubungan antara variabel laten dan indikatornya. SEM mempunyai
kemampuan lebih dalam menyelesaikan permasalahan yang melibatkan banyak
permasalahan linear pada variabel laten. SEM juga dapat menggambarkan
hubungan kausalitas antar variabel yang tidak bisa dijelaskan pada analisis regresi
biasa, sehingga dapat diketahui seberapa baik suatu variabel indikator menentukan
variabel laten. Namun penggunaan SEM memiliki asumsi yang mendasari yaitu
multivariat normal dan jumlah sampel yang besar. Penggunaan sampel yang kecil
dapat menghasilkan taksiran parameter yang tidak baik bahkan tidak konvergen

2
Sehingga salah satu pendekatan yang dapat digunakan adalah partial least square
(PLS).
Partial Least Square (PLS) merupakan metode analisis yang powerful
karena dapat diterapkan pada semua skala data, tidak membutuhkan banyak
asumsi dan ukuran sampel tidak harus besar. Model dalam PLS meliputi tiga
tahap, yaitu outer model atau model pengukuran, inner model atau model
struktural dan weight relation. PLS juga dapat digunakan untuk pemodelan
struktural dengan indikator bersifat reflektif ataupun formatif.
Berdasarkan uraian di atas, maka dilakukan penelitian dengan menggunakan
Structural Equation Modeling (SEM) dengan pendekatan Partial Least Square
(PLS) dalam membentuk model struktural yang diterapkan pada kasus kemiskinan
di Kabupaten/Kota Pulau Sulawesi. Sehingga penelitian ini diberi judul
“PEMODELAN KEMISKINAN DI PULAU SULAWESI DENGAN
STRUCTURAL EQUATION MODELING-PARTIAL LEAST SQUARE”
1.2 Rumusan Masalah
Berdasarkan latar belakang di atas, maka dapat dirumuskan permasalahan
sebagai berikut:
1. Bagaimanakah pemodelan untuk data kemiskinan di Pulau Sulawesi
dengan metode SEM-PLS?
2. Bagaimanakah pengaruh variabel Ekonomi, SDM, dan Kesehatan
terhadap kemiskinan di Pulau Sulawesi?

3
1.3 Tujuan Penelitian
Berdasarkan rumusan masalah di atas maka penelitian ini bertujuan untuk:
1. Menyusun model untuk data kemiskinan di Pulau Sulawesi dengan
metode SEM-PLS
2. Mengetahui pengaruh variabel Ekonomi, SDM, Kesehatan terhadap
kemiskinan di Pulau Sulawesi
1.4 Manfaat Penelitian
Hasil penelitian ini diharapkan mempunyai beberapa manfaat, antara lain:
1. Memberikan sumbangan pemikiran bagi dunia ilmu pengetahuan
khususnya dalam menyusun model kemiskinan dengan metode SEM-
PLS
2. Memberikan kontribusi ilmiah di dunia pendidikan khususnya
matematika.

BAB II
TINJAUAN PUSTAKA
2.1. Matriks
Matriks adalah susunan segi empat siku-siku dari bilangan-bilangan (Howard
Anton, 1987). Bilangan-bilangan dalam susunan tersebut dinamakan entri dalam
matriks. Matriks A dengan baris dan kolom disebut matriks dengan ukuran,
ditulis
[
] (2.1)
Atau dalam notasi matriks dengan
adalah unsur pada baris ke- dan kolom ke- .
Suatu matriks yang terdiri dari satu baris disebut vector baris sedangkan
matriks yang terdiri dari satu kolom disebut vector kolom.
2.1.1. Penjumlahan dan Pengurangan Matriks
Jika A dan B adalah sebarang dua matriks yang ukuran sama, maka jumlah
dua matriks A+B adalah matriks yang diperoleh dengan menambahkan setiap
entri yang bersesuaian pada kedua matriks tersebut (Howard anton, 1987 : 23).
Misalkan [
] dan [
]
maka [
] (2.2)

5
dengan notasi matriks, . Pengukuran dua matriks juga
hanya didefinisikan jika kedua matriks berukuran sama. Pengurangan dua matriks,
yang dinyatakan dengan adalah matriks yang ditentukan dengan aturan
, sehingga
[
] (2.3)
2.1.2. Perkalian Matriks
Jika adalah matriks dan adalah matriks , maka hasil kali
adalah matriks yang entri-entrinya ditentukan sebagai berikut. Untuk
mencari entri dalam baris ke- dan kolom ke- dari , pilih baris dari matriks
dan kolom dari matriks . Kalikanlah entri-entri yang bersesuaian dari baris dan
kolom tersebut bersama-sama dan kemudian tambahkanlah hasil kali yang
dihasilan (Howard anton, 1987).
Jika dan dengan dan
. Perkalian matriks A dan B yang dinyatakan oleh, yang
memenuhi syarat: banyaknya kolom A sama dengan banyak baris B. Jika syarat
ini tidak terpenuhi, hasil kalinya tidak terdefinisi.
Dalam notasi matriks,
[
]
[
]
(2.4)

6
Aturan: ∑ (jumlah dari semua perkalian antara elemen A pada
baris ke-i dengan elemen B pada kolom ke-k).
Dengan aturan tersebut, dikaitkan dengan vector kolom dan vector baris, jika
vektor baris ke- dari matriks A dan vektor kolom ke- dari matriks B, maka
elemen-elemen matriks C adalah: .
2.1.3. Matriks Data Multivariat
Dalam analisis multivariat sering kali dihadapkan pada masalah
pengamatan yang dilakukan pada suatu periode waktu untuk p>1 variabel atau
karakter. Akan dinotasikan yang mendefinisikan objek ke- pada variabel ke- .
menurut Johnson dan Wichern (2007:5), secara umum sampel data multivariat
dapat disajikan dalam bentuk sebagai berikut:
Var-1 Var-2 … Var-j … Var-p
Objek-1 … …
Objek-2 … …
… … Objek-i … …
… …
Objek-n … …
Atau dapat ditulis dalam bentuk matriks sebagai berikut:
[
]
(2.5)
Dengan
adalah objek ke- pada variabel ke-
adalah banyaknya item atau objek

7
adalah banyaknya variabel
Dapat juga dinotasikan dengan dan .
2.1.4. Vektor Mean, Matriks Kovariansi dan Matriks Korelasi Data Sampel
Misalkann adalah pengukuran pada variabel pertama.
Rata-rata pengukuran disebut juga rata-rata (mean) sampel ditulis dengan
adalah
∑
(2.6)
Secara umum mean sampel untuk variabel ke- bila ada variabel dan
banyaknya data adalah:
∑
(2.7)
Sehingga vector mean sampel
[
]
(2.8)
Variansi sampel untuk variabel ke-i adalah
( )
∑ ( )
(2.9)
Sedangkan kovariansi sampel untuk variabel ke- dan ke- adalah
( )
∑ ( )( )
(2.10)
Dan matriks varians dan kovarians sampel
[
] (2.11)

8
Koefisien korelasi sampel merupakan ukuran hubungan linear antara 2
variabel. Koefisien korelasi sampel untuk variabel ke- dan ke- adalah:
√ √
∑ ( )( )
√∑ ( )
√∑ ( )
(2.12)
Untuk untuk setiap dan
Sehingga diperoleh matriks korelasi sampel
[
] (2.13)
2.1.5. Vektor Mean, Matriks Kovariansi dan Matriks Korelasi Data
Populasi
Misalkan matriks random berorde untuk setiap
merupakan sebuah vector random. Mean dari vector random untuk populasi
adalah:
( ) [
] [
( ) ( )
( )
] [
] (2.14)
Kovariansi dari vector random adalah
( )( ) ([
] [ ])
[
( ) ( )( )
( )( ) ( )
( )( )
( )( )
( )( ) ( )( )
( ) ]

9
[
( ) ( )( )
( )( ) ( )
( )( )
( )( )
( )( ) ( )( )
( )
]
( ) [
] (2.15)
Oleh karena , untuk setiap dan dengan
maka berlaku:
( )
[
]
(2.16)
Merupakan matriks simetris denga dan berturut-turut adalah mean
populasi dan varians-kovarians populasi.
Ukuran hubungan linear antara variabel random dan disebut koefisien
korelasi. Koefisien korelasi populasi didefinisikan sebagai rasio kovariansi dan
sehingga
√ √ (2.17)
Matriks koefisien korelasi populasi merupakan matriks simetris , berorde ,
dimana:
[
√ √
√ √
√ √
√ √
√ √
√ √
√ √
√ √
√ √ ]

10
[
] (2.18)
2.2. Regresi Linier Ganda
Regresi linier ganda adalah hubungan antara suatu variabel tak bebas dengan
dua atau lebih variabel bebas (Sudjana, 2001).
Model regresi linier ganda, dinyatakan sebagai berikut:
(2.19)
Jika:
adalah variabel tak bebas/dependen pada pengamatan ke-i
adalah parameter regresi
adalah variabel bebas/independen pada pengamatan ke-i
adalah peubah gangguan ata error yang bersifat acak dengan rataan
dan ragam dan tidak berkolerasi sehingga
peragam/kovariansi { } untuk semua dengan
Dapat ditulis dalam bentuk matriks:
[
]
[
]
[
] *
+ (2.20)
Sehingga model umum regresi linear ganda dalam bentuk matriks dapat
dinotasikan sebagai berikut:
( ) ( ) (2.21)

11
2.3.Structural Equation Modeling (SEM)
Penelitian pada bidang ilmu sosial umumnya menggunakan konsep-konsep
teoritis atau konstruk-konstruk yang tidak dapat diukur untuk dapat diamati secara
langsung. Namun masih bisa ditemukan beberapa indikator untuk mempelajari
konsep-konsep teoritis tersebut. Kondisi seperti di atas menimbulkan dua
permasalahan besar untuk membuat kesimpulan ilmiah dalam ilmu sosial dan
perilaku, yaitu:
1. Masalah pengukuran
2. Masalah hubungan kausal antar variabel
Structural Equation Modelling (SEM) merupakan salah satu analisis statistik
yang dapat menjawab permasalahan di atas (Mattijik & Sumetajaya, 2011).
Structural Equation Modeling (SEM) pertama kali dikenalkan oleh seorang
ilmuwan bernama Joreskog pada tahun 1970. SEM merupakan teknik statistika
yang kuat dalam menetapkan model pengukuran dan model struktural. SEM juga
didasarkan pada hubungan kausalitas, yakni terjadinya perubahan pada satu
variabel berdampak pada perubahan variabel lainnya. Sebagai contoh dalam
bidang pemasaran, kwalitas barang akan mempengaruhi harga barang kepuasan
konsumen dan sebagainya. Metode SEM memiliki kemampuan analisis dan
prediksi yang lebih baik dibandingkan analisis jalur dan regresi berganda karena
SEM mampu menganalisis sampai pada level terdalam terhadap variabel atau
model yang diteliti. Metode SEM lebih korpehensif dalam menjelaskan fenomena
penelitian. Sementara analisis jalur dan regresi berganda hanya mampu
menjangkau level variabel laten sehingga mengalami kesulitan dalam mengurai

12
atau menganalisis fenomena empiris yang terjadi pada level-level butir atau
indikator-indikator variabel laten (Ulum , 2014).
Terdapat dua alasan penting yang mendasari digunakannya SEM. Pertama,
SEM memiliki kemampuan untuk mengestimasi hubungan antar variabel yang
bersifat multiple relationship. Hubungan ini dibentuk dalam model struktural yang
digambarkan melalui hubungan antara variabel laten endogen (dependen) dan
variabel laten eksogen (independen). Kedua SEM memiliki kemampuan untuk
menggambarkan pola hubungan antara variabel laten dan variabel indikator
(manifest). Penggunaan SEM memiliki yang mendasari yaitu multivariat normal
dan jumlah sampel yang besar (Anuraga & Otok, 2013).
2.3.1. Variabel Laten dan Variabel Teramati
Di dalam perilaku, pendidikan, kesehatan, dan sains sosial, teori substantif
biasanya melibatkan dua jenis variabel dengan nama variabel teramati dan
variabel laten. Variabel teramati adalah variabel yang dapat diamati secara
langsung seperti nilai ujian, penghasilan, tekanan darah sistolik/diastolic dan berat
badan seseorang. Variabel laten adalah variabel yang tidak dapat diamati secara
langsung seperti kecerdasan, kepribadian, kondisi kesehatan, kemampuan.
Variabel laten merupakan variabel yang tidak dapat diukur secara
langsung melalui variabel observasi, variabel ini memerlukan beberapa indikator
untuk mengukurnya (Ghozali & Fuad, 2005).
Variabel laten merupakan konsep abstrak sebagai contoh : perilaku orang,
sikap, perasaan dan motivasi. Variabel laten ini hanya dapat diamati secara tidak

13
langsung dan tidak sempurna melalui efeknya pada variabel teramati. SEM
mempunyai 2 jenis variabel laten, yaitu:
Variabel Eksogen sebagai variabel bebas dan dinotasikan dengan Ksi (ξ).
Variabel Endogen merupakan variabel terikat pada model dan dinotasikan
dengan Eta (η).
Variabel laten ini digambarkan dalam bentuk diagram lingkar atau oval atau
elips,
Variabel teramati adalah variabel yang dapat diamati atau dapat diukur secara
empiris dan sering disebut sebagai indicator atau variabel manifest. Variabel
teramati merupakan efek atau ukuran variabel laten. Variabel terukur adalah
variabel yang datanya harus dicari melalui penelitian lapangan dan digambarkan
dalam bentuk diagram bujur sangkar seperti (Mattijik & Sumetajaya,
2011).
2.4. Partial Least Square
Partial Least Square (PLS) pertama kali dikembangkan oleh Herman Wold
tahun 1975. Model ini dikembangkan sebagai alternatif apabila teori yang
mendasari perancangan model lemah. Partial Least Square (PLS) menurut Wold
merupakan metode analisis yang powerful oleh karena tidak didasarkan banyak
asumsi. Metode PLS mempunyai keunggulan tersendiri diantaranya: data tidak
harus berdistribusi normal multivariat (indikator dengan skala kategori, ordinal,
interval sampai rasio dapat digunakan pada model yang sama) dan ukuran sampel
tidak harus besar. Walaupun PLS digunakan untuk menkonfirmasi teori, tetapi
dapat juga digunakan untuk menjelaskan ada atau tidaknya hubungan antara

14
variabel laten. PLS mempunyai dua model indikator dalam penggambarannya,
yaitu:
a. Model Indikator Refleksif
Model indikator refleksif sering disebut juga principal factor model dimana
kovarians pengukuran indikator dipengaruhi oleh konstruk laten atau
mencerminkan variansi dari konstruk laten. Pada model refleksif konstruk
unidimensional digambarkan dengan bentuk elips dengan beberapa anak panah
dari konstruk ke indikator, model ini menghipotesiskan bahwa perubahan pada
konstruk laten akan mempengaruhi perubahan pada indikator. Model indikator
reflektif harus memiliki internal konsistensi oleh karena semua ukuran indikator
diasumsikan semuanya valid indikator yang mengukur suatu konstruk, sehingga
dua ukuran indikator yang sama reliabilitasnya dapat saling dipertukarkan.
Walaupun realibilitas (Cronbach alpha) suatu konstruk akan rendah jika hanya
ada sedikit indikator, tetapi validitas konstruk tidak akan berubah jika satu
indikator dihilangkan.
b. Model Indikator Formatif
Model Formatif tidak mengansumsikan bahwa indikator dipengaruhi oleh
konstruk tetapi mengasumsikan semua indikator ke konstruk laten dan indikator
sebagai grup secara bersama-sama menentukan konsep atau makna empiris dari
konstruk laten. Oleh karena diasumsikan bahwa indikator mempengaruhi konstruk
laten maka ada kemungkinan antar indikator saling berkolerasi, tetapi model
formatif tidak mengasumsikan perlunya korelasi antar indikator atau secara
konsisten bahwa model formatif berasumsi tidak adanya hubungan korelasi antar

15
indikator, karenanya ukuran internal konsistensi reliabilitas (cronbach alpha)
tidak diperlukan untuk menguji reliabilitas konstruk formatif. Kausalitas
hubungan antar indikator tidak menjadi rendah nilai validitasnya hanya karena
memiliki internal konsistensi yang rendah (cronbach alpha), untuk menilai
validitas konstruk perlu dilihat variabel lain yang mempengaruhi konstruk laten.
Jadi untuk menguji validitas dari konstruk laten, peneliti harus menekankan pada
nomological dan atau criterion-related validity. Implikasi lain dari model formatif
adalah dengan menghilangkan satu indicator dapat menghilangkan bagian yang
unik dari konstruk laten dan merubah makna dari konstruk. (Aisyah, 2015)
Gambar 2.1. Model indikator refleksif & Model indikator formatif

16
2.5. Structural Equation Modeling-Partial Least Square (SEM-PLS)
Pada tahun 1975, Wold menyelesaikan sebuah soft modeling untuk analisis
hubungan antara beberapa blok dari variabel teramati pada unit statistik yang
sama. Metode ini dikenal sebagai pendekatan PLS ke SEM (SEM-PLS) atau PLS
Path Modeling (PLS-PM) yang merupakan metode SEM berbasis varian. (Ulum
& Tirta, 2014).
Beberapa hal penting yang melandasi SEM menggunakan PLS menurut
Monecke & Leisch (2012) diantaranya:
SEM menggunakan PLS terdiri dari 3 komponen yaitu model struktural,
model pengukuran dan skema pembobotan. Bagian ketiga ini merupakan
ciri khusus SEM dengan PLS dan tidak ada pada SEM yang berbasis
kovarian. Jika digambarkan model akan seperti dibawah ini
Gambar 2.2 Model PLS SEM
Pada model struktural, yang disebut juga sebagai model bagian dalam,
semua variabel laten dihubungkan satu dengan yang lain dengan
didasarkan pada teori substansi. Variabel laten dibagi menjadi dua, yaitu

17
eksogenous dan endogenous. Variabel laten eksogenous adalah variabel
penyebab atau variabel tanpa didahului oleh variabel lainnya dengan tanda
anak panah menuju ke variabel lainnya (variabel laten endogenous).
(Sarwono, 2014)
2.5.1. Notasi SEM-PLS
Ilustrasi pemodelan persamaan struktural dan notasi PLS dapat dilihat
pada gambar dibawah ini
Gambar 2.3 Hubungan antar variabel dan indikator dalam model PLS
dimana notasi-notasi yang digunakan adalah:
= Ksi, variabel laten eksogen
= Eta, variabel laten endogen
= Lamda (kecil), loading factor variabel laten eksogen
= Lamda (kecil), loading factor variabel laten endogen
= Lamda (besar), matriks loading factor variabel laten eksogen
= Lamda (besar), matriks loading factor variabel laten endogen

18
= beta (kecil), koefisien pengaruh variabel endogen terhadap variabel endogen
= Gamma (kecil), koefisien pengaruh variabel eksogen terhadap variabel
endogen
= zeta (kecil), galat model
= Delta (kecil), galat pengukuran pada variabel manifest untuk veriabel laten
eksogen
= Epsilon (kecil), galat pengukuran pada variabel manifest untuk variabel laten
ekogen
2.5.2. Langkah-langkah Analisis PLS
Langkah-langkah pemodelan persamaan struktural berbasis PLS dengan
software adalah sebagai berikut:
Gambar 2.4 diagram alur algoritma PLS

19
1. Langkah pertama: merancang model struktural (inner model)
Perancangan model struktural hubungan antar variabel laten pada PLS
didasarkan pada rumusan masalah atau hipotesis penelitian.
2. Langkah kedua: merancang model pengukuran (outer model)
Perancangan model pengukuran (outer model) dalam PLS sangat penting
karena terkait dengan apakah indikator bersifat refleksif atau formatif.
3. Langkah ketiga: mengkonstruksi diagram jalur
Bilamana langkah satu dan dua sudah dilakukan, maka agar hasilnya lebih
mudah dipahami, hasil perancangan inner model dan outer model tersebut,
selanjutnya dinyatakan dalam bentuk diagram jalur.
4. Langkah keempat: konversi diagram jalur ke dalam sistem persamaan
a. Outer model
Outer model, yaitu spesifikasi hubungan antara variabel laten dengan
indikatornya, disebut juga dengan outer relation atau measurement model,
mendefinisikan karakteristik konstruk dengan variabel manifestnya. Model
indikator refleksif dapat ditulis persamaannya sebagai berikut:
(2.22)
(2.23)
dimana x dan y adalah indicator untuk variabel laten eksogen (ξ) dan
endogen (𝝶). Sedangkan dan merupakan matriks loading yang
menggambarkan seperti koefisien regresi sederhana yang menghubungkan
variabel laten dengan indikatornya. Residual yang diukur dengan 𝛅 dan 𝝴
dapat diinterpretasikan sebagai kesalahan pengukuran atau noise.

20
Model indikator formatif persamaannya dapat ditulis sebagai berikut:
(2.24)
(2.25)
dimana , , , dan sama dengan persamaan sebelumnya. Dengan
dan adalah seperti koefisien regresi berganda dari variabel laten terhadap
indikator, sedangkan dan adalah residual dari regresi.
Pada model PLS gambar 2.3 terdapat outer model sebagai berikut:
Untuk variabel laten eksogen 1 (reflektif)
Untuk variabel laten eksogen 2 (formatif)
Untuk variabel laten endogen 1 (reflektif)
Untuk variabel laten endogen 2 (reflektif)
b. Inner model
Inner model, yaitu spesifikasi hubungan antar variabel laten (structural
model), disebut juga dengan inner relation, menggambarkan hubungan antar
variabel laten berdasarkan teori substansif penelitian. Tanpa kehilangan sifat

21
umumnya, diasumsikan bahwa variabel laten dan indikator atau variabel
manifest diskala zero means dan unit varian sama dengan satu, sehingga
parameter lokasi (parameter konstanta) dapat dihilangkan dari model.
Model persamaannya dapat ditulis seperti dibawah ini:
(2.26)
dimana (eta) adalah vector variabel random dependen endogen (latent
endogenous) dengan ukuran , (xi) adalah vector variabel random
independen eksogen (latent exogenous) dengan ukuran , 𝚩 adalah matrik
koefisien yang menunjukkan pengaruh variabel laten endogen terhadap
variabel lainnya dengan ukuran dan koefisien matrik yang
menunjukkan hubungan dari terhadap dengan ukuran mxn, sedangkan
(zeta) adalah vector random error dengan ukuran , dengan nilai harapan
sama dengan nol . Oleh karena PLS didesain untuk model rekursif, maka
hubungan antar variabel laten, berlaku bahwa setiap variabel laten dependen,
atau sering disebut causal chain system dari variabel laten dapat
dispesifikasikan sebagai berikut:
(2.27)
Dimana (dalam bentuk matriks dilambangkan dengan ) adalah koefisien
jalur yang menghubungkan variabel laten endogen ke- ( ) dengan variabel
laten eksogen ke- ( ). Sedangkan (dalam bentuk matriks dilambangkan
dengan ) adalah koefisien jalur yang menghubungkan variabel laten endogen
ke- ( ) dengan variabel laten endogen ke- ( ); untuk range indeks dan ,

22
adalah jumlah variabel laten endogen, parameter adalah variabel inner
residual.
Pada model PLS gambar 2.3 inner model dinyatakan dalam sistem persamaan
sebagai berikut:
(2.28)
(2.29)
c. Weight relation
Weight relation, estimasi nilai kasus variabel latent. Inner dan outer model
memberikan spesifikasi yang diikuti dengan estimasi weight relation dalam
algoritma PLS:
(2.30)
(2.31)
Dimana dan adalah weight yang digunakan untuk membentuk
estimasi variabel laten dan . estimasi variabel laten adalah linear agregat
dari indikator yang nilai weight nya didapat dengan prosedur PLS.
5. Langkah kelima: Estimasi
Metode pengukuran parameter (estimasi) di dalam PLS adalah metode
kuadrat terkecil (least square methods). Proses perhitungan dilakukan dengan cara
iterasi, dimana iterasi akan berhenti jika telah tercapai kondisi konvergen
Pendugaan parameter di dalam PLS meliputi 3 hal, yaitu:
1) Weight estimate digunakan untuk menciptakan skor variabel laten
2) Estimate jalur (path estimate) yang menghubungkan antar variabel laten dan
estimasi loading antara variabel laten dengan indikatornya.

23
3) Means dan lokasi parameter (nilai konstanta regresi, intersep) untuk
indikator dan variabel laten.
6. Langkah keenam: goodness of fit
a) Outer model
Convergent validity
Korelasi antara skor indikator refleksif dengan skor variabel latennya.
Untuk hal ini loading 0.5 sampai 0.6 dianggap cukup, pada jumlah indikator
per konstruk tidak besar, berkisar antara 3 sampai 7 indikator.
Discriminant validity
Membandingkan nilai square root of average variance extractes (AVE)
setiap konstruk dengan korelasi antar konstruk lainnya dalam model, jika
AVE konstruk lebih besar dari korelasi dengan seluruh konstruk lainnya maka
dikatakan memiliki discriminant validity yang baik. Direkomendasikan nilai
pengukuran harus lebih besar dari 0.50.
( )
(2.32)
Composite reliability (ρc)
Kelompok indikator yang mengukur sebuah variabel memiliki reliabilitas
komposit yang baik jika memiliki composite reliability 0.7, walaupun
bukan merupakan standar absolute.
( )
( ) ( )
(2.33)

24
b) Inner model
Goodness of Fit model diukur menggunakan R-square variabel laten
dependen dengan interpretasi yang sama dengan regresi; Q-square predictive
relevance untuk model struktural, mengukur seberapa baik nilai observasi
dihasilkan oleh model dan juga estimasi parameternya. Nilai Q-square 0
menunjukkan model memiliki predictive relevance; sebaiknya jika nilai Q-
square 0 menunjukkan model kurang memiliki predictive relevance.
Perhitungan Q-square dilakukan dengan rumus:
( )(
) ( ) (2.34)
dimana
adalah R-square variabel endogen dalam model
persamaan. Besaran memiliki nilai dengan rentang , dimana
semakin mendekati 1 berarti model semakin baik. Besaran Q2 ini setara dengan
koefisien determinasi total pada analisis jalur (path analysis).
7. Langkah ketujuh: pengujian hipotesis
Pengujian hipotesis ( , , dan ) dilakukan dengan metode resampling
bootstrap yang dikembangkan oleh Geisser & Stone. Statistik uji yang digunakan
adalah statistik t atau uji t, dengan hipotesis statistik sebagai berikut:
Hipotesis statistik untuk outer model adalah:
(indikator ke- tidak signifikan)
(indikator signifikan)
Sedangkan hipotesis statistik untuk inner model: pengaruh variabel laten eksogen
terhadap endogen adalah
(variabel eksogen ke- tidak signifikan)

25
(variabel eksogen ke- signifikan)
Sedangkan hipotesis statistik untuk inner model: pengaruh variabel laten endogen
terhadap endogen adalah
(variabel endogen ke- tidak signifikan)
(variabel endogen ke- signifikan)
Penerapan metode resampling, memungkinkan berlakunya data berdistribusi
bebas (distribution free), tidak memerlukan asumsi distribusi normal, tidak
memerlukan sampel yang besar. Pengujian dilakukan dengan t-test, bilamana
diperolehnya p-value (alpha 5%), maka disimpulkan signifikan, dan
sebaliknya. Bilamana hasil pengujian hipotesis pada outer model signifikan, hal
ini menunjukkan bahwa indikator dipandang dapat digunakan sebagai instrument
pengukur variabel laten. Sedangkan bilamana hasil pengujian pada inner model
adalah signifikan, maka dapat diartikan bahwa terdapat pengaruh yang bermakna
variabel laten terhadap variabel laten lainnya.(Jaya & Sumertajaya, 2008)
Pengujian dengan statistik uji t sebagai berikut
Statistik uji t untuk outer model
( ) (2.35)
Statistik uji t untuk inner model: pengaruh variabel laten eksogen terhadap
endogen
( ) (2.36)
Statistik uji t untuk inner model: pengaruh variabel laten endogen terhadap
endogen
( ) (2.37)

26
Jika diperoleh statistik t lebih besar dari nilai t-tabel antara lain 1.65 (pada
taraf signifikansi 10%), 1.96 (pada taraf signifikansi 5%), dan 2.58 (pada taraf
signifikansi 1%) maka dapat disimpulkan bahwa koefisien jalur signifikan dan
sebaliknya.
2.5.3. Estimasi Parameter SEM-PLS
a. Weight estimate digunakan untuk menciptakan skor variabel laten
Tahap pertama menghasilkan estimasi bobot (weight estimate) .
Estimasi bobot-bobot diperoleh melalui dua jalan, yaitu mode A dan mode
B. Mode A dirancang untuk memperoleh estimasi bobot dengan tipe indikator
refleksif, sedangkan mode B dirancang untuk memperoleh estimasi bobot
dengan tipe indikator formatif.
Mode A
Pada mode A bobot adalah koefisien regresi dari dalam regresi
sederhana pada estimasi inner model , dengan adalah variabel yang
distandarisasi:
(2.38)
Estimasi untuk mode A diperoleh melalui metode OLS dengan cara
meminimumkan jumlah kuadrat , sebagai berikut:
(2.39)
∑
∑ ( )
(2.40)
dimana (2.41)

27
Meminimumkan ∑( ) ∑( )
dengan menurunkan
terhadap dan :
∑( )
∑( )
∑( )
∑ ∑ ∑
∑ ∑
∑ ∑
∑
∑
(2.42)
∑( )
∑ ( )
∑ ( )
∑ ∑ ∑
∑ ∑ ∑ (2.43)
Substitusikan persamaan (2.42) ke dalam persamaan (2.43)
∑ (∑
∑
) ∑ ∑
∑ ∑ ∑ (∑ ) ∑
∑ ∑ ∑ ( ∑ (∑ )
)
∑ ∑ ∑
∑ (∑ )
(2.44)
Persamaan (2.44) dimanipulasi dengan membagi pembilang dan penyebut
dengan , sehingga diperoleh:
∑
∑ ( )

28
∑( )( )
∑( )
( )
( )
(2.45)
Mode B
Pada mode B vektor dari pembobot adalah vektor koefisien regresi
berganda dari pada variabel manifest ( ) yang dihubungkan ke
sesama variabel laten :
(2.46)
(2.47)
Hitung :
( )
( ) (2.48)
(
)( )
Kemudian diturunkan terhadap
(
)
Kita kalikan kedua ruas dengan ( )
sehingga diperoleh bobot untuk
mode B
( )
(2.49)
Dimana adalah matriks dengan kolom yang didefinisikan oleh variabel
manifest ( ) yang menghubungkan variabel laten ke-j. vektor bobot
inner model adalah ( ( ))
( ) dengan (
)
adalah matriks kovarians dari dan ( ) adalah vektor kolom dari
kovarians antara variabel dan .

29
b. Estimate jalur (path estimate) yang menghubungkan antar variabel laten
dan estimasi loading antara variabel laten dengan indikatornya.
Estimasi Inner Model
Dengan mengikuti algoritma PLS dari Wold (1985) dan yang telah
diperbaiki oleh Lohmoller’s (1989), maka estimasi inner model dari
standarized variabel laten ( ) didefinisikan dengan:
∑
Dimana bobot inner model dapat dipilih melalui tiga skema yaitu :
1. Skema jalur (path scheme)
Variabel laten dihubungkan pada yang dibagi kedalam dua grup yaitu :
variabel-variabel laten yang menjelaskan dan diikuti dengan variabel-
variabel yang dijelaskan oleh . Jika dijelaskan oleh maka
adalah koefisien regresi berganda dari . Jika dijelaskan oleh
maka adalah korelasi antara dengan .
{
( )
2. Skema centroid (centroid scheme)
Bobot inner model merupakan korelasi tanda (sign correlation) antara
dari , dan dapat ditulis sebagai berikut :
[ ( )]
3. Skema faktor (factor scheme)
Bobot inner model merupakan korelasi antara dari , dan dapat
ditulis sebagai berikut :

30
( )
Estimasi Outer Model
Estimasi outer model dari standarisasi variabel laten ( ) dengan
rata-rata = 0 dan standart deviasi = 1, diestimasi dengan kombinasi linear dari
pusat variabel manifest (indikator) melalui persamaan berikut :
[∑ ( ) ]
Simbol bermakna bahwa variabel sebelah kiri mewakili variabel sebelah
kanan yang distandarisasi. Standarisasi variabel laten dapat ditulis dengan
persamaan sebagai berikut :
(2.50)
Dengan dan (2.51)
Sehingga ∑ ( ) (2.52)
Dimana koefisien dan keduanya dinamakan sebagai pembobot outer
model.
c. Means dan lokasi parameter (nilai konstanta regresi, intersep) untuk
indikator dan variabel laten.
Tahap ketiga menghasilkan estimasi rata-rata (mean) dan lokasi parameter
(konstanta). Pada tahap ini, estimasi didasarkan pada matriks data asli dan
hasil estimasi bobot pada tahap pertama dan koefisien jalur pada tahap kedua,
tujuannya untuk menghitung rata-rata dan lokasi parameter untuk indikator dan
variabel laten.

31
Estimasi Rata-rata (Mean)
Estimasi rata-rata (mean) diperoleh melalui persamaan sebagai berikut :
(2.53)
(2.54)
Dengan
∑ ( )
maka
∑ ( )
∑ (2.55)
Sehingga diperoleh:
∑ (2.56)
Dimana didefinisikan sebagai pembobot dari outer model, dengan
semua variabel manifest yaitu pengamatan pada skala pengukuran yang sama.
Estimasi Lokasi Parameter
Secara umum koefisien jalur adalah koefisien regresi berganda dari
variabel laten endogen yang distandarisasi pada variabel laten penjelas
(eksogen) .
∑ (2.57)
Pada saat variabel laten tidak memusat (non centered) adalah sama
dengan . persamaan regresi pada saat variabel laten tidak memusat
adalah :
∑ (2.58)

32
( ( ∑
))
∑
(
∑ ∑
)
∑
Dengan
∑ (2.59)
Jadi lokasi parameternya adalah konstanta untuk variabel laten endogen dan
rata-rata untuk variabel laten eksogen.
Tahap 2: pendugaan koefisien jalur
Setelah diperoleh data variabel, tahapan selanjutnya adalah
mengestimasi koefisien jalur menggunakan ordinary least square (OLS)
antara variabel laten yang saling terkait:
∑
∑
Hitung :∑
( ∑ )
( ∑ ) (2.60)
( ∑
)( ∑ )
∑ ∑
∑
∑
Kemudian diturunkan terhadap
(
∑ ∑
∑
∑ )
∑ ∑
∑
Kita kalikan kedua ruas dengan ( )
sehingga diperoleh:
( )
(2.61)

33
adalah koefisien jalur yang menghubungkan antara variabel laten
ke-j dan ke-i , adalah matriks data variabel laten ke-i dan adalah vector
data variabel laten ke-j. Kemudian mengestimasi loading yang didapatkan dari
korelasi antara indikator dengan skor laten:
( ) (2.62)
2.6. Metode Bootstrap
Bootstrap diperkenalkan oleh Bradley Efron pada tahun 1979. Istilah
bootstrap berasal dari “pull oneself up by one’s bootstrap”, yang berarti berpijak
diatas kaki sendiri, berusaha dengan sumber daya minimal. Dalam sudut pandang
statistika, sumber daya minimal adalah data yang sedikit, data yang menyimpang
dari asumsi tertentu, atau data yang tidak mempunyai asumsi apapun tentang
distribusi populasinya. Teknik ini mampu menciptakan ukuran-ukuran dari
ketidakpastian dan bias, khususnya estimasi parameter dari variabel-variabel yang
independen dan berdistribusi identik. Bootstrap adalah teknik resampling yang
bertujuan untuk menaksir galat baku, dan selang kepercayaan parameter populasi,
seperti mean, median, proporsi, koefisien korelasi, dan regresi dengan tidak selalu
memperhatikan asumsi distribusi.
Metode bootstrap bergantung atas dugaan sebuah sampel bootstrap. Misal
distribusi empiric, mengatakan probabilitas ⁄ atas masing-masing nilai
dengan ( ) yang diamati. Sebuah sampel bootstrap didefinisikan
menjadi sebuah sampel random berukuran diambil dari , misal (
) , dinotasikan sebagai berikut
(
) (2.63)

34
Notasi bintang menunjukkan bahwa tidaklah himpunan data yang
sesungguhnya , tetapi sebuah proses random, atau resample dari himpunan data
asli . Bersesuaian untuk sebuah himpunan data bootstrap adalah sebuah
replikasi bootstrap ,
( ) (2.64)
Kuantitas ( ) adalah hasil mempergunakan fungsi yang sama () untuk
diaplikasikan pada . Sebagai contoh adalah sampel mean maka ( )
adalah mean himpunan data bootstrap, ∑
⁄ . Estimasi bootstrap
( ) , standar error sebuah statistik , adalah sebuah estimasi plugin yang
menggunakan fungsi distribusi empirik . Khusus estimasi bootstrap ( )
didefinisikan dengan:
( ) (2.65)
Dengan kata lain, estimasi bootstrap ( ) adalah stadar error untuk
himpunan-himpunan data berukuran yang disampel secara random dari .
Rumus ( ) disebut estimasi standar error ideal .
Algoritma bootstrap bekerja dengan pengambilan banyaknya sampel
bootstrap bebas, perhitungan berhubungan dengan replikasi bootstrap, dan
pengestimasian standar error oleh simpangan baku empiric replikasi. Hasilnya
disebut estimasi bootstrap standar error, dinyatakan dengan , dimana B adalah
banyaknya sampel bootstrap digunakan. Algoritma berikut adalah sebuah
deskripsi lebih jelas prosedur bootstrap untuk pengestimasian standar error
( ) dari data yang diamati.

35
(1) Seleksi B sampel-sampel bootstrap bebas , masing-masing
berisikan nilai data diambil dengan pengembalian dari .
(2) Hitung replikasi bootstrap berkaitan untuk setiap sampel bootstrap,
( ) ( ) (2.66)
(3) Estimasi standar error ( ) oleh simpangan baku replikasi
√∑ ( ) ( )
( ) (2.67)
Dalam hal ini ( ) ∑ ( )
⁄
Gambar 2.5. Skema Algoritma Standar Error Bootstrap
2.7.Kemiskinan
Menurut BPS (2012) kemiskinan secara konseptual dibedakan menurut
kemiskinan relatif dan kemiskinan absolut, dimana perbedaannya terletak pada
standar penilaiannya. Standar penilaian kemiskinan relatif merupakan standar
kehidupan yang ditetapkan secara subyektif oleh masyarakat setempat dan bersifat
lokal serta mereka yang berada dibawah standar penilaian tersebut dikategorikan

36
sebagai miskin secara relatif. Sedangkan standar penilaian kemiskinan secara
absolut merupakan standar kehidupan minimum yang dibutuhkan untuk
memenuhi kebutuhan dasar yang diperlukan, baik makanan maupun non
makanan. Standar kehidupan minimum untuk memenuhi kebutuhan dasar ini
disebut garis kemiskinan. BPS mendefinisikan garis kemiskinan sebagai nilai
rupiah yang harus dikeluarkan seseorang dalam sebulan agar dapat memenuhi
asupan kalori sebesar 2011 kkal/hari per kapita (garis kemiskinan makanan)
ditambah kebutuhan dasar seseorang, yaitu papan, sandang, sekolah, dan
transportasi serta kebutuhan individu dan rumah tangga dasar lainnya (garis
kemiskinan non makanan).
Badan Pusat Statistik (BPS) menggunakan konsep kemampuan
pemenuhan kebutuhan dasar (basic need approach) untuk mengukur kemiskinan.
Dengan pendekatan ini, kemiskinan dipandang sebagai ketidakmampuan dari sisi
ekonomi untuk memenuhi kebutuhan makanan maupun non makanan yang
bersifat mendasar.
Metode yang digunakan oleh BPS dalam melakukan perhitungan jumlah
dan presentase penduduk miskin adalah dengan menghitung garis kemiskinan
(GK). Penduduk dikatakan miskin apabila penduduk tersebut memiliki rata-rata
pengeluaran perkapita perbulan dibawah garis kemiskinan. Perhitungan garis
kemiskinan dilakukan secara terpisah untuk daerah perkotaan dan pedesaan. Garis
kemiskinan terdiri dari dua komponen, Garis kemiskinan Makanan (GKM) dan
Garis Kemiskinan Non-Makanan (GKNM).

37
Garis Kemiskinan makanan merupakan nilai pengeluaran kebutuhan
minimum makanan yang disertakan dengan 2.100 kilokalori perkapita per hari.
Patokan ini mengacu pada hasil widyakarya pangan dan gizi 1978. Sementara,
Garis Kemiskinan Non Makanan adalah kebutuhan minimum untuk perumahan,
sandang, pendidikan, dan kesehatan. Menurut standar BPS, kriteria kemiskinan
memenuhi 14 indikator yaitu Luas lantai bangunan tempat tinggal kurang dari 8
m2 per orang, jenis lantai tempat tinggal terbuat dari tanah/bambu/kayu murahan,
jenis lantai tempat tinggal, jenis dinding tempat tinggal dari bamboo/rumbia/kayu
berkualitas rendah/tembok tanpa diplester, tidak memiliki fasilitas buang air
besar/bersama-sama dengan rumah tangga lain, sumber penerangan rumah tangga
tidak menggunakan listrik, sumber air minum berasal dari sumur/mata air tidak
terlindungi/sungai/air hujan, bahan bakar untuk memasak sehari-hari adalah kayu
bakar/arang/minyak tanah, hanya mengkonsumsi daging/susu/ayam dalam satu
kali seminggu, hanya membeli satu stel pakaian baru dalam setahun, hanya
sanggup makan sebanyak satu/dua kali dalam sehari, tidak sanggup membayar
biaya pengobatan di puskesmas/polikinik, sumber penghasilan kepala rumah
tangga adalah: petani dengan luas tanah 500 m2, buruh tani, nelayan, buruh
bangunan, buruh perkebunan dan atau pekerja lainnya dengan pendapatan
dibawah Rp. 600.000,- per bulan, pendidikan tertinggi kepala rumah tangga: tidak
sekolah/tidak tamat SD/tamat SD, tidak memiliki tabungan/barang yang mudah
dijual dengan minimal Rp. 500.000,- seperti sepeda motor kredit/non kredit, emas,
ternak, emas, kapal motor atau barang modal lainnya (BAPPENAS, 2010).

38
Formula dasar dalam menghitung Garis Kemiskinan Makanan (GKM)
adalah:
∑ ∑
(2.68)
Dimana:
= garis kemiskinan makanan daerah j (sebelum disertakan
menjadi 2100 kilokalori)
= harga komoditi k di daerah j
= rata-rata kuantitas komoditi k yang dikonsumsi di daerah j
= nilai pengeluaran untuk konsumsi komoditi k di daerah j
j = daerah (perkotaan atau pedesaan)
Selanjutnya tersebut disetarakan dengan 2100 kilokalori dengan
mengalikan 2100 terhadap harga implisit rata-rata kalori menurut daerah j dari
penduduk referensi, sehingga :
∑
∑
(2.69)
Dimana:
= kalori dari komoditi k di daerah j
= harga rata-rata kalori di daerah j
(2.70)
Dimana:
= kebutuhan minimum makanan di daerah j, yaitu menghasilkan
energi setara dengan 2100 kilokalori/kapita/hari

39
Nilai kebutuhan non makanan secara matematis dapat diformulasikan
sebagai berikut:
∑ (2.71)
Dimana:
= pengeluaran minimum non-makanan atau garis kemiskinan
non makanan daerah p ( )
= nilai pengeluaran per komoditi/sub-kelompok non-makanan
daerah p
= rasio pengeluaran komoditi/sub-kelompok non-makanan
menurut daerah
i = jenis komoditi non-makanan terpilih di daerah p
p = daerah (perkotaan atau pedesaan)
2.7.1. Persentase Penduduk Miskin
Rumus penghitungan:
∑ *
+
(2.72)
Dimana:
= 0
= garis kemiskinan
= rata-rata pengeluaran per kapita sebulan penduduk yang
berada dibawah garis kemiskinan (i=1,2,3,…,q),
q = banyaknya penduduk yang berada di bawah garis kemiskinan
n = jumlah penduduk
2.7.2. Indeks Kedalaman Kemiskinan
Indeks kedalaman kemiskinan merupakan ukuran rata-rata kesenjangan
pengeluaran masing-masing penduduk miskin terhadap garis kemiskinan.

40
Semakin tinggi nilai indeks, semakin jauh rata-rata pengeluaran penduduk dari
garis kemiskinan.
Rumus perhitungan:
∑ *
+
(2.73)
Dimana:
= 1
= garis kemiskinan
= rata-rata pengeluaran per kapita sebulan penduduk yang
berada dibawah garis kemiskinan (i=1,2,3,…,q),
q = banyaknya penduduk yang berada di bawah garis kemiskinan
n = jumlah penduduk
2.7.3. Indeks Keparahan Kemiskinan
Indeks keparahan kemiskinan memberikan gambaran mengenai
penyebaran pengeluaran diantara penduduk miskin. Semakin tinggi nilai indeks,
semakin tinggi ketimpangan pengeluaran diantara penduduk miskin.
Rumus perhitungan:
∑ *
+
(2.74)
= 2
= garis kemiskinan
= rata-rata pengeluaran per kapita sebulan penduduk yang
berada dibawah garis kemiskinan (i=1,2,3,…,q),
q = banyaknya penduduk yang berada di bawah garis kemiskinan
n = jumlah penduduk
(BPS, 2009)

BAB III
METODE PENELITIAN
3.1 Waktu dan Tempat
Penelitian ini berlangsung dari bulan Maret 2016 sampai dengan hasil
penelitiannya selesai. Penelitian ini bertempat di Laboratorium Penelitian
Mahasiswa Jurusan Matematika Fakultas Matematika dan Ilmu Pengetahuan
Alam Universitas Halu Oleo.
3.2 Sumber Data
Data penelitian ini merupakan data sekunder yang diperoleh dari website
Badan Pusat Statistik setiap Provinsi di Sulawesi. Sulawesi Tenggara
(sultra.bps.go.id) yakni publikasi “Statistik Kesejahteraan Rakyat Provinsi
Sulawesi Tenggara 2013”, Sulawesi Selatan (sulsel.bps.go.id) yakni publikasi
“Statistik Sosial dan Ekonomi Rumah Tangga Sulawesi Selatan 2013”, Sulawesi
Tengah (sulteng.bps.go.id) yakni publikasi “Statistik Kesejahteraan Rakyat
Provinsi Sulawesi Tengah 2013”, Sulawesi Barat (sulbar.bps.go.id) yakni
publikasi “Statistik Kesejahteraan Rakyat Provinsi Sulawesi Barat 2013”,
Sulawesi Utara (sulut.go.id) yakni publikasi “Statistik Kesejahteraan Rakyat
Provinsi Sulawesi Utara 2013”, Gorontalo (gorontalo.bps.go.id) yakni publikasi
“Indikator Kesejahteraan Rakyat Provinsi Gorontalo 2013”. Informasi yang
didapatkan antara lain persentase penduduk miskin, indeks kedalaman kemiskinan,
indeks keparahan kemiskinan, kesehatan, pendidikan, perumahan dan pemukiman,
konsumsi dan pengeluaran.

42
3.3 Identifikasi Variabel
Variabel yang digunakan dalam penelitian ini terdiri atas variabel eksogen
(independen) dan variabel endogen (dependen) serta beberapa indikator (variabel
manifest). Variabel eksogen dalam penelitian ini adalah Ekonomi, SDM, &
Kesehatan. Kemiskinan adalah variabel endogen. Dan beberapa indikator dari
masing-masing variabel eksogen maupun variabel endogen. Semua variabel yang
digunakan dalam penelitian ini dapat dilihat pada Tabel 3.1
Tabel 3.1 Variabel laten dan indikator
Indikator untuk Kemiskinan (η)
Persentase penduduk miskin
Indeks kedalaman kemiskinan
Indeks keparahan kemiskinan
Indikator untuk Ekonomi ( )
Persentase penduduk menurut golongan pengeluaran per kapita sebulan
(150.000-199.999)
Persentase rumah tangga dengan luas lantai perkapita
Persentase rumah tangga menurut sumber penerangan (pelita/sentir/obor)
Persentase rumah tangga menurut jenis dinding (kayu)
Indikator untuk SDM ( )
Angka buta huruf penduduk usia 10 tahun ke atas
Angka partisipasi sekolah penduduk usia 13-15 tahun
Angka melek huruf penduduk usia 10 tahun ke atas
Persentase penduduk berumur 10 tahun ke atas menurut pendidikan yang
ditamatkan (tidak tamat SD)
Indikator untuk Kesehatan ( )
Persentase balita yang diberi ASI
Persentase rumah tangga menurut sumber air minum (sumur tak
terlindungi)
Persentase rumah tangga menurut fasilitas tempat buang air (umum)
Persentase penduduk yang mengalami keluhan kesehatan

43
Jika digambarkan dalam bentuk diagram maka diperoleh gambar sebagai berikut:
Gambar 3.1 diagram jalur (path diagram)
3.4 Prosedur Penelitian
Adapun metode dan analisis yang digunakan dalam mencapai tujuan
penelitian adalah melakukan analisis pemodelan SEM-PLS. dan langkah-
langkahnya dapat diuraikan sebagai berikut:
a. Menyusun model konseptual berbasis konsep dan teori untuk
merancang model struktural (hubungan antar variabel laten) dan model
pengukurannya, yaitu hubungan antara indikator-indikator dengan
variabel laten.

44
b. Membuat diagram jalur (path diagram) yang menjelaskan pola
hubungan antara variabel laten dengan indikatornya.
c. Mengkonversi diagram jalur ke dalam persamaan.
d. Estimasi koefisien weight, jalur, dan mean dan lokasi parameter
e. Evaluasi outer dan inner model.
f. Pengujian hipotesis (resampling bootstrap)
g. Menginterpretasikan dan menyimpulkan hasil.

BAB IV
HASIL DAN PEMBAHASAN
4.1. Penyajian Diagram Jalur
Berdasarkan tabel 3.1. mempunyai 3 variabel laten eksogen (variabel
bebas), yaitu ekonomi ( ), SDM ( ), dan Kesehatan ( ) dengan satu variabel
laten endogen (variabel tergantung), yaitu kemiskinan (η). Variabel laten endogen
dan eksogen pada penelitian ini diukur oleh indikator secara refleksif. Dimana X1,
X2, X3, X4 merupakan indikator dari Ekonomi, X5, X6, X7, X8 merupakan indikator
dari SDM, X9, X10, X11, X12 merupakan indikator dari Kesehatan, Y1, Y2, Y3
merupakan indikator dari Kemiskinan. Berikut adalah diagram jalur yang akan
dimodelkan pada penelitian ini.
Gambar 4.1. model persamaan struktural dengan SEM-PLS
Selanjutnya, diagram jalur pada gambar 4.1. di konversikan ke dalam sistem
persamaan yang terdiri dari model pengukuran (outer model) dan model struktural
(Inner model). Model pengukuran, yaitu spesifikasi antara variabel laten dengan

46
indikatornya. Sedangkan model struktural, yaitu spesifikasi hubungan antara
variabel laten.
1) Model pengukuran:
Model indikator refleksif dapat ditulis persamaannya sebagai berikut:
Dimana x dan y adalah indikator untuk variabel laten eksogen (ξ) dan
endogen (𝝶). Sedangkan dan merupakan matriks loading yang
menggambarkan seperti koefisien regresi sederhana yang menghubungkan
variabel laten dengan indikatornya. Residual yang diukur dengan 𝛅 dan 𝝴
dapat diinterpretasikan sebagai kesalahan pengukuran atau noise.
Pada model gambar 4.1. terdapat outer model sebagai berikut:
(
)
(
)
(
) (
) (4.1)
(
) (
) (
) (4.2)

47
Model pengukuran diatas dapat juga ditulis sebagaimana berikut:
1. Untuk variabel laten eksogen 1 (refleksif)
(4.3)
(4.4)
(4.5)
(4.6)
2. Untuk variabel laten eksogen 2 (refleksif)
(4.7)
(4.8)
(4.9)
(4.10)
3. Untuk variabel laten eksogen 3 (refleksif)
(4.11)
(4.12)
(4.13)
(4.14)
4. Untuk variabel laten endogen (refleksif)
(4.15)
(4.16)
(4.17)
2) Model struktural
Model persamaan struktural dapat ditulis seperti dibawah ini:

48
Karena, PLS didesain untuk model rekursif, maka hubungan antar variabel
laten, berlaku bahwa setiap variabel laten dependen, atau sering disebut
causal chain system dari variabel laten dapat dispesifikasikan sebagai berikut:
Dimana (dalam bentuk matriks dilambangkan dengan ) adalah
koefisien jalur yang menghubungkan variabel laten endogen (𝝶) dengan
eksogen ( ). Sedangkan (dalam bentuk matriks dilambangkan dengan )
adalah koefisien jalur yang menghubungkan variabel laten endogen (𝝶)
dengan endogen (𝝶).
Pada model PLS gambar 4.1. inner model dinyatakan dalam sistem
persamaan sebagaimana berikut:
( ) (
) (4.18)
Dimana adalah koefisien jalur yang menghubungkan antara variabel
laten eksogen 1 ( ) dengan variabel endogen ( ), adalah koefisien jalur
yang menghubungkan antara variabel laten eksogen 2 ( ) dengan variabel
endogen ( ), adalah koefisien jalur yang menghubungkan antara variabel
laten eksogen 3 ( ) dengan variabel endogen ( ), adalah galat model.
Model struktural tersebut dapat juga ditulis :
(4.19)
Kemiskinan = Ekonomi + SDM + Kesehatan +

49
4.2. Evaluasi Model Pengukuran (Outer Model)
Sebelum melakukan pengujian hipotesis untuk memprediksi hubungan antar
variabel laten dalam model struktural, terlebih dahulu dilakukan evaluasi model
pengukuran untuk verifikasi indikator dan variabel laten yang dapat diuji
selanjutnya.
Jika terdapat loading factor yang bernilai dibawah 0,50 maka dihilangkan
agar didapatkan model yang spesifik bahwa standar loading factor lebih besar
sama dengan 0,50. Sedangkan dalam melakukan spesifikasi model ulang dapat
dilakukan dengan mengeleminasi indikator-indikator dari model. Jika indikator
dihapus untuk beberapa alasan, maka indikator lainnya harus diperbaiki. (Ulum &
Tirta, 2014)
Untuk memperoleh nilai faktor loading dari Ekonomi, SDM, Kesehatan, dan
Kemiskinan. Maka dilakukan analisis SEM-PLS dengan bantuan package plspm
pada program R i386 3.2.3. Berikut adalah hasil analisis SEM-PLS dengan
menggunakan Package plspm pada program R i386 3.2.3
Gambar 4.2. Outer Model (a)

50
Hasil uji validitas diagram jalur dengan menggunakan Package plspm pada R
i386 3.2.3 menunjukkan ada 4 indikator yang nilai loading di bawah 0.5 dan harus
di hilangkan yaitu untuk indikator dari variabel Ekonomi, untuk indikator
dari variabel SDM dan untuk indikator dari variabel Kesehatan.
Setelah indikator-indikator yang tidak valid dihilangkan kemudian
dilakukan pengujian ulang, maka didapatkan output Package plspm pada program
R i386 3.2.3 sebagaimana gambar berikut
Gambar 4.3. Outer Model (b)
4.3. Uji Validitas dan Reliabilitas pada Outer Model
Model pengukuran yang baik harus memenuhi tiga kriteria, yaitu (a)
reliabilitas (reliability), (b) validitas konvergen (convergent validity) dan (c)
validitas diskriminant (discriminant validity). Dalam pendekatan SEM/PLS,

51
sebuah pengukuran telah memenuhi validitas konvergen jika memenuhi beberapa
syarat:
a) Memiliki reliabilitas indikator/aitem minimal 0.5
b) Memiliki reliabilitas komposit lebih tinggi dari 0.7
c) Rerata varians terekstrasi (AVE) minimal 0.5.
4.3.1. Validitas Konvergen
Validitas konvergen berhubungan dengan prinsip bahwa pengukur-
pengukur dari suatu konstruk seharusnya berkolerasi tinggi. Parameter untuk
melihat validitas konvergen adalah loading factor dengan rule of thumb > 0.7,
average variance extracted (AVE) > 0.5. Namun untuk penelitian tahap awal dari
pengembangan skala pengukuran, nilai loading factor 0.5-0.6 masih dianggap
cukup.
Hasil output software R i386 3.2.3 dengan package plspm didapat nilai faktor
loading masing-masing indikator dan nilai AVE masing-masing konstruk sebagai
berikut:
Tabel 4.1. Nilai Faktor Loading
Variabel Kemiskinan Ekonomi SDM Kesehatan
0.667
0.762
0.765
0.703
0.703
0.882
0.845
0.762
0.721
0.908
0.981
0.958

52
Berdasarkan Tabel 4.1. dapat diketahui bahwa lebih dari 60% dari varian
masing-masing pada tiga indikator, yaitu X1, X3 dan X4 dapat dijelaskan oleh
variabel laten Ekonomi. Variabel laten SDM dapat menjelaskan varian dari
indikator X5, X7, X8 masing-masing lebih dari 70%. Varian dari X10, X11 dan X12
masing-masing dapat dijelaskan oleh variabel laten kesehatan lebih dari 70%.
Sedangkan variabel laten kemiskinan sebagai variabel laten endogen mampu
menjelaskan ketiga indikatornya, yakni Y1, Y2, dan Y3 masing-masing di atas
90%. Sehingga, secara keseluruhan masing-masing variabel laten mampu
menjelaskan varian dari setiap indikator-indikator yang mengukurnya di atas 60%.
Tabel 4.2. Nilai AVE
AVE Keterangan
Kemiskinan 0.902 Valid
Ekonomi 0.537 Valid
SDM 0.589 Valid
Kesehatan 0.605 Valid
AVE semua variabel laten > 0.5 , hal ini menunjukkan bahwa semua indikator
mampu menjelaskan masing-masing konstruknya dengan baik.
4.3.2. Validitas Diskriminan
Validitas diskriminan berhubungan dengan prinsip bahwa pengukur-
pengukur konstruk yang berbeda seharusnya tidak berkolerasi dengan tinggi.
Hasil output software R i386 3.2.3 dengan package plspm didapat cross
loading masing-masing indikator sebagai berikut:
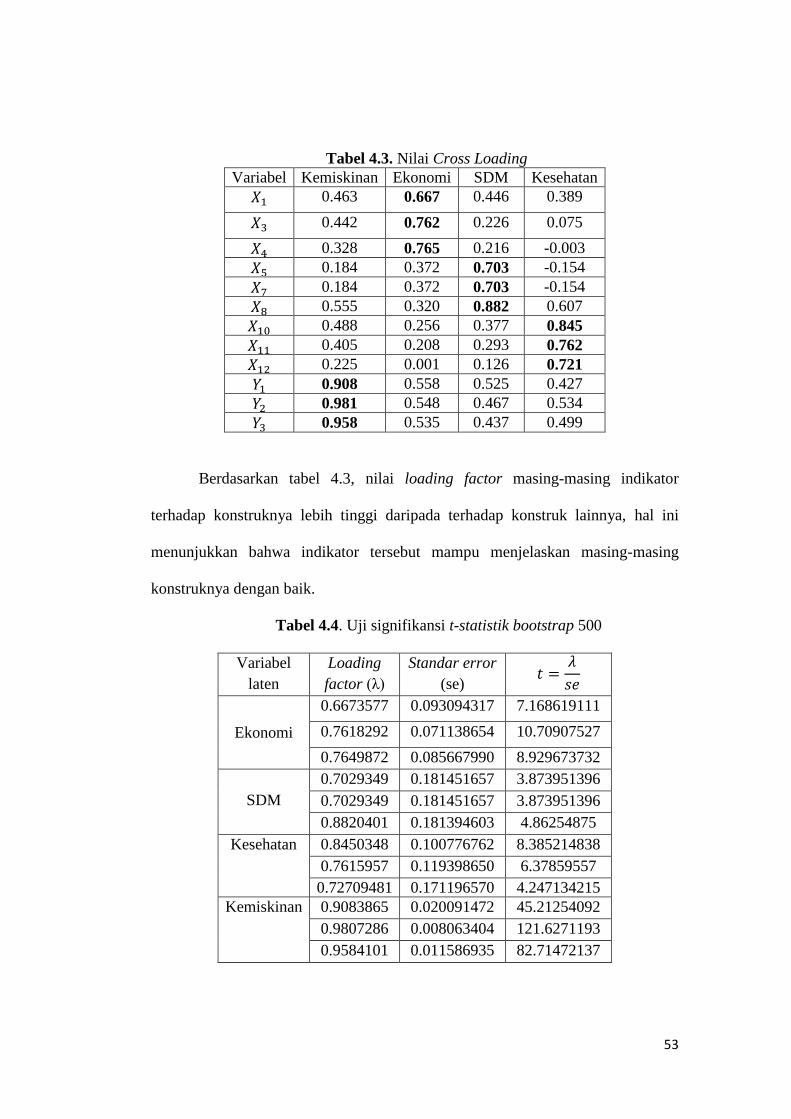
53
Tabel 4.3. Nilai Cross Loading
Variabel Kemiskinan Ekonomi SDM Kesehatan
0.463 0.667 0.446 0.389
0.442 0.762 0.226 0.075
0.328 0.765 0.216 -0.003
0.184 0.372 0.703 -0.154
0.184 0.372 0.703 -0.154
0.555 0.320 0.882 0.607
0.488 0.256 0.377 0.845
0.405 0.208 0.293 0.762
0.225 0.001 0.126 0.721
0.908 0.558 0.525 0.427
0.981 0.548 0.467 0.534
0.958 0.535 0.437 0.499
Berdasarkan tabel 4.3, nilai loading factor masing-masing indikator
terhadap konstruknya lebih tinggi daripada terhadap konstruk lainnya, hal ini
menunjukkan bahwa indikator tersebut mampu menjelaskan masing-masing
konstruknya dengan baik.
Tabel 4.4. Uji signifikansi t-statistik bootstrap 500
Variabel
laten
Loading
factor (λ)
Standar error
(se)
Ekonomi
0.6673577 0.093094317 7.168619111
0.7618292 0.071138654 10.70907527
0.7649872 0.085667990 8.929673732
SDM
0.7029349 0.181451657 3.873951396
0.7029349 0.181451657 3.873951396
0.8820401 0.181394603 4.86254875
Kesehatan 0.8450348 0.100776762 8.385214838
0.7615957 0.119398650 6.37859557
0.72709481 0.171196570 4.247134215
Kemiskinan 0.9083865 0.020091472 45.21254092
0.9807286 0.008063404 121.6271193
0.9584101 0.011586935 82.71472137

54
Berdasarkan tabel 4.4, menunjukkan bahwa estimasi nilai loading pada
masing-masing variabel laten adalah signifikan, hal ini ditunjukkan dengan nilai t-
statistik yang lebih besar dari t-tabel 1.960 pada tingkat signifikansi alpha 0.05.
4.3.3. Validitas Reliability
Uji reliabilitas dilakukan dengan dua cara yaitu dengan Cronbach Alpha
dan Composite Reliability sering disebut Dillon-Goldstein’s. Rule of thumb yang
biasa digunakan untuk menilai reliabilitas suatu konstruk yaitu nilai Composite
Reliability > 0.7.
Hasil output software R i386 3.2.3 dengan package plspm didapatkan nilai
Composite Reability dan Cronbach alpha masing-masing variabel konstruk
sebagai berikut:
Tabel 4.5. Composite Reability dan Cronbach Alpha
Composite Reability Cronbach Alpha
Kemiskinan 0.965 0.945
Ekonomi 0.778 0.572
SDM 0.874 0.767
Kesehatan 0.828 0.688
Berdasarkan tabel 4.5, nilai Cronbach Alpha > 0.5 dan Composite reliability
> 0.7, hal ini menunjukkan bahwa setiap indikator memiliki realibilitas yang baik
terhadap masing-masing konstruknya.

55
4.4. Persamaan struktural/inner model
Pengujian inner model atau model struktural dilakukan untuk melihat
hubungan antara konstruk, nilai signifikansi dan R-square dari model penelitian.
Model struktural dievaluasi dengan menggunakan R-square untuk konstruk
dependen uji t serta signifikansi dari koefisien parameter jalur struktural.
Hasil output software R i386 3.2.3 dengan package plspm
Gambar 4.4. Inner Model
Hasil dari koefisien jalur dan nilai t-statistik yang didapatkan melalui proses
bootstrapping dengan jumlah sampel untuk resampling sebesar 73 dan
pengulangan sebanyak 500 kali ditunjukkan pada tabel 4.6 sebagai berikut
Tabel 4.6. Nilai Koefisien Analisis Jalur
Original
sample (O)
Standard Error
(STERR)
T statistics
(|O/STERR|)
Ekonomi-> Kemiskinan 0.4111788 0.08812237 4.665997975
SDM-> Kemiskinan 0.2016142 0.09591775 2.101948805
Kesehatan-> Kemiskinan 0.3399782 0.09921523 3.426673506

56
Berdasarkan tabel 4.6, nilai koefisien analisis jalur, dapat di tuliskan
persamaan kemiskinan di Pulau Sulawesi sebagai berikut:
Kemiskinan = 0.4112 Ekonomi + 0.2016 SDM + 0.34 Kesehatan
Dari model kemiskinan di atas koefisien parameter jalur yang diperoleh
dari hubungan antara variabel ekonomi dengan kemiskinan sebesar 0.4112 dengan
nilai T-statistik 4,666>1,96 pada taraf signifikansi (5%) yang
menyatakan bahwa terdapat pengaruh positif dan signifikan antara ekonomi
dengan kemiskinan.
Koefisien parameter jalur yang diperoleh dari hubungan antara variabel
ekonomi dengan kemiskinan sebesar 0.2016 dengan nilai T-statistik 2,012>1,96
pada taraf signifikansi (5%) yang menyatakan bahwa terdapat pengaruh
positif dan signifikan antara SDM dengan kemiskinan.
Koefisien parameter jalur yang diperoleh dari hubungan antara variabel
Kesehatan dengan kemiskinan sebesar 0.34 dengan nilai T-statistik 3,427>1,96
pada taraf signifikansi (5%) yang menyatakan bahwa terdapat pengaruh
positif dan signifikan antara kesehatan dengan kemiskinan.
Dari evaluasi terhadap model persamaan struktural pada SEM PLS dapat
diketahui dari nilai goodness of fit atau R2. Hasil pengolahan data penelitian ini
dengan menggunakan R i386 3.2.3 dengan package plspm memberikan nilai R-
square (R2) sebagaimana pada tabel berikut:

57
Tabel 4.7. R-square
Variabel Laten R-square Keterangan
Ekonomi
SDM
Kesehatan
Kemiskinan 0.513 Baik
Nilai R-square (R2) untuk kemiskinan sebesar 0.513 yang artinya model
mampu menjelaskan variasi dari kemiskinan di Pulau Sulawesi sebesar 51,30%,
bahwa ekonomi, SDM, dan Kesehatan mampu menjelaskan kemiskinan sebesar
51,30% berarti ada faktor lain sebesar 48,70% yang tidak masuk dalam model
yang dijelaskan oleh error.

BAB V
KESIMPULAN DAN SARAN
5.1. Kesimpulan
1. Didapatkan model struktural untuk kasus kemiskinan di Pulau Sulawesi
adalah sebagai berikut:
Kemiskinan = 0.4112 Ekonomi + 0.2016 SDM + 0.34 Kesehatan
Terdapat pengaruh antara ekonomi (dengan indikator yang berpengaruh
yaitu persentase penduduk menurut golongan pengeluaran per kapita
sebulan (150.000-199.999), persentase rumah tangga menurut sumber
penerangan (pelita/sentir/obor), dan persentase rumah tangga menurut
jenis dinding (kayu)) terhadap kemiskinan sebesar 0.4112 yang artinya
semakin tinggi ekonomi maka kemiskinan (dengan indikator yang
berpengaruh yaitu persentase penduduk miskin, indeks kedalaman
kemiskinan, dan indeks keparahan kemiskinan) akan meningkat sebesar
0.4112 atau 41,12% dan sebaliknya.
Terdapat pengaruh antara SDM (dengan indikator yang berpengaruh yaitu
angka buta huruf penduduk usia 10 tahun ke atas, angka melek huruf
penduduk usia 10 tahun ke atas, dan persentase penduduk berumur 10
tahun ke atas menurut pendidikan yang ditamatkan (tidak tamat SD))
terhadap kemiskinan sebesar 0.2016 yang artinya semakin tinggi SDM
maka kemiskinan (dengan indikator yang berpengaruh yaitu persentase
penduduk miskin, indeks kedalaman kemiskinan, dan indeks keparahan
kemiskinan) akan meningkat sebesar 0.2016 atau 20,16% dan sebaliknya.

59
Terdapat pengaruh antara kesehatan (dengan indikator yang berpengaruh
yaitu persentase rumah tangga menurut sumber air minum (sumur tak
terlindungi), persentase rumah tangga menurut fasilitas tempat buang air
(umum), persentase penduduk yang mengalami keluhan kesehatan)
terhadap kemiskinan sebesar 0.34 yang artinya semakin tinggi kesehatan
maka kemiskinan (dengan indikator yang berpengaruh yaitu persentase
penduduk miskin, indeks kedalaman kemiskinan, dan indeks keparahan
kemiskinan) akan meningkat sebesar 0.34 atau 34% dan sebaliknya.
2. Ekonomi, SDM dan Kesehatan memiliki pengaruh yang positif dan
signifikan terhadap variabel laten kemiskinan. Nilai R-square (R2) untuk
kemiskinan sebesar 0.513 yang artinya model mampu menjelaskan variasi
dari kemiskinan di Pulau Sulawesi sebesar 51,30%, bahwa ekonomi,
SDM, dan Kesehatan mampu menjelaskan kemiskinan sebesar 51,30%
berarti ada faktor lain sebesar 48,70% yang tidak masuk dalam model
yang dijelaskan oleh error.
5.2. Saran
Saran yang dapat diberikan untuk penelitian selanjutnya adalah variabel
laten pemodelan kemiskinan dengan pendekatan SEM-PLS dapat dikembangkan.

DAFTAR PUSTAKA
Anuraga, G. dan Otok, B. W. 2013. Pemodelan Kemiskinan Di Jawa Timur
dengan Structural Equation Modeling-Partial Least Square; Institut
Teknologi Sepuluh November; Surabaya
Aisyah, S. N., Supriyono, H. dan Rifqi, R. R. 2015. Analisis SEM-PLS.
Universitas Brawijaya
Anton, H. 1987. Aljabar Linear Elementer. Jakarta: Erlangga.
BAPPENAS. 2010. Laporan Akhir: Evaluasi Pelayanan Keluarga Berencana
Bagi Masyarakat Miskin (Keluarga Prasejahtera/KPS dan Keluarga
Sejahtera-I/KS-I).
Effendi, M. B., dan Ulum, A. S. 2015. Pengaruh Ekonomi dan SDM terhadap
Kemiskinan di Jawa Timur dengan SMART-PLS 2.0. Media Mahardhika,
13(3), 223-231
Ghozali I dan Fuad. 2005. Structural Equation Modeling: Teori, Konsep dan
Aplikasi Lisrel. Penerbit Universitas Diponegoro.
Jaya, I. G. N. dan Sumertajaya, I. M. 2008. Pemodelan Persamaan Struktural
dengan PARTIAL LEAST SQUARE.
Mansyur, A., Efendi, S., Firmansyah dan Togi. 2011. Estimator Parameter Model
Regresi dengan Metode Bootstrap. Bulletin of Mathematics, 03(02),
189-202.
Mattjiik, A. A. dan Sumertajaya.I. M. 2011. Sidik Peubah Ganda dengan
menggunakan SAS. Departemen Statistika, Institut Pertanian Bogor.
Monecke, A. dan Leisch, F. 2012. SemPLS: Structural Equation Modeling Using
Partial Least Squares. Journal Of Statistics Software.
Sanchez, G. 2013. PLS Path Modeling with R. Barkeley, California.
Ulum, M., Tirta, I. M., dan Anggraeni, D.2014. Analisis Structural Equation
Modelling (SEM) untuk Sampel Kecil dengan Pendekatan Partial Least
Square (PLS); Universitas Jember; Jember
Widhiarso, W. 2011. Reliabilitas dan Validitas dalam Pemodelan Persamaan
Struktural SEM. Fakultas Psikologi Universitas Gadjah Mada


62
Lampiran 1 Kab/Kota X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 Y1 Y2 Y3
Buton 13.41 3.9 8.34 55 11.91 87.54 88.09 36.39 6.17 7.44 10.64 11.12 15.25 2.77 0.73
Muna 8.82 3.38 9.64 70.47 9.83 90.74 90.17 35.16 6.57 3.98 6.67 8.69 15.32 2.82 0.74
Konawe 2.78 0.93 4.81 61.77 6.05 91.61 93.95 19.97 7.21 18.7 1.45 12.1 16.58 2.15 0.43
Kolaka 0.56 3.73 9.93 69.27 6.6 84.17 93.4 24.41 3.01 7.18 2.87 9.04 16.2 3.8 1.16
Konawe Selatan 10.22 0.88 6.54 68.34 5.83 89.96 94.17 24.04 5.43 15.32 2.94 10.15 12.45 1.53 0.31
Bombana 5.47 2.89 18.95 67.8 5.79 85.5 94.21 29.31 3.95 10.7 6 5.86 14.28 2.15 0.59
Wakatobi 1.49 1.5 3.42 30.87 6.22 96.25 93.78 25.45 30.8 3.48 0.85 10.6 17.4 2.11 0.37
Kolaka Utara 4.35 1.48 17.19 78.23 5.21 79.34 94.79 25.14 5.38 0.72 0.71 8.62 17.41 3.47 0.95
Buton Utara 6.88 1.64 32.18 62.41 6.92 92.62 93.08 24.24 3.71 9.67 6.77 4.61 17.53 3.58 1.34
Konawe Utara 2.6 0 9.01 69.38 5.53 89.17 94.47 20.59 5.39 18.91 0.14 7.32 10.62 0.78 0.13
Kendari 0.75 21.14 1.23 32.37 1.83 89.03 98.17 10.65 10.47 0.95 1.49 11.57 6.07 0.77 0.13
Bau-Bau 3.79 14.67 0.33 38.42 4.46 96.87 95.54 19.78 9.62 0.19 6.36 9.59 10.11 1.8 0.5
Selayar 4.62 3.59 7.75 64.59 7.26 93.79 92.74 29.41 5.12 0.56 16.64 4.68 14.23 2.32 0.54
Bulukumba 11.63 0.9 3.1 52.73 9.34 95.64 90.66 25.72 6.39 12.07 2.29 8.4 9.04 1.01 0.17
Bantaeng 8.79 0.48 7.13 51.55 16.41 84.21 83.59 35.67 18.22 3.62 7.01 15.08 10.45 1.68 0.49
Jeneponto 8.02 0.92 0.2 15.88 17.5 86.07 82.5 27.63 6.79 3.22 4.8 15.19 16.52 2.42 0.61
Takalar 6.86 1.6 0.41 13.3 11.02 85.1 88.98 31.18 5.18 8.5 3.41 8.93 10.42 1.48 0.35
Gowa 8 2.17 3.51 18.58 13.44 88.27 86.56 23.78 12.14 2.39 1.53 9.11 8.73 1.19 0.25
Sinjai 11.77 0.34 11.45 45.81 9.84 88.31 90.16 26.73 6.86 6.92 1.85 6.7 10.32 1.41 0.33
Maros 4.41 2.37 2.21 25.21 10.65 85.14 89.35 23.83 9.69 3.05 3.15 13.21 12.94 2.24 0.63
Pangkep 5.98 2.83 2.86 26.35 8.54 89.47 91.46 22.02 2.48 11.47 3.72 12.62 17.75 3.15 0.85
Barru 9.22 1.65 8.92 46.97 10.12 93.11 89.88 22.22 0 3.61 1.56 9.64 10.32 1.33 0.26
Bone 18.27 0.2 8.94 66.15 9.62 82.92 90.38 28.06 3.1 4.91 1.94 6.98 11.92 1.75 0.47
63
Soppeng 8.94 1.38 4.12 49.92 8.85 88.72 91.51 24.87 2.3 0.65 0.81 7.86 9.43 0.93 0.15
Wajo 1.4 1.07 5.07 77.64 11.24 84.56 88.76 19.38 11.13 7.81 0.76 9.27 8.17 1.27 0.35
Sidrap 3.65 1.75 1.36 48 8.66 85.74 91.34 20.27 7.06 0.9 1.82 8.1 6.3 1 0.23
Pinrang 4.57 2.98 1.44 43.36 6.93 89.91 93.07 22.19 9.32 7.01 0.59 12.98 8.86 1.16 0.22
Enrekang 8.87 3.54 4.1 70.78 8.04 95.8 91.96 22.87 5.17 0.24 0.49 9.43 15.11 2.02 0.44
Luwu 12.94 0.72 7.72 65.94 8.61 93.61 91.39 20.41 9.24 9.26 1.64 11.68 15.1 2.25 0.52
Tana Toraja 16.78 4.36 10.91 75.01 7.81 93.1 92.19 20.12 0 6.95 0.37 9.2 13.81 1.81 0.38
Luwu Utara 12.87 0.62 7.48 56.92 6.14 88.43 93.86 21.4 4.39 17.82 0.4 10.44 15.52 2.06 0.43
Luwu Timur 5.36 2.1 7.28 62.07 5.27 95.69 94.73 23.36 14.65 11.18 0.22 13.93 8.38 1.37 0.32
Toraja Utara 15.22 4.3 9.57 75.53 10.74 96.84 89.26 27.54 5.28 7.55 1.52 6.06 16.53 3.03 0.86
Makassar 1.39 12.87 0 14.02 2.02 96.65 97.98 11.44 5.44 0.6 1.59 4.44 4.7 0.84 0.24
Pare-Pare 2.54 2.56 0.38 27.37 4.48 91.69 95.52 16.21 6.04 1.06 5.06 7.9 6.38 0.83 0.18
Palopo 0.36 9.16 2.59 48.97 2.86 90.69 97.14 15.37 17.81 4.49 3.61 9.45 9.57 1.42 0.3
Majene 6.9 2.12 24.84 58.35 5.06 92.92 94.81 17.02 24.7 1.71 10.3 20.76 16.3 2.18 0.65
Polewali Mandar 3.82 3.02 8.28 54.81 4.58 86.99 95.15 23.56 32.38 7.09 5.19 10.59 9.81 1.7 0.43
Mamasa 0.33 2.41 13.72 64.38 4.03 89.28 95.91 21.58 24.35 15.24 1.61 11.16 15.92 1.41 0.32
Mamuju 1.59 2.09 10.07 58.37 2.74 91.89 97.15 18.06 22.14 5.34 1.73 11.32 18.22 2.09 0.52
Mamuju Utara 10.15 6.19 21.19 55.37 6.44 80.25 93 23.39 27.08 5.07 6.29 7.19 17.18 2.76 0.74
Banggai Kepulauan 4.64 3.43 13.79 59.86 6.15 83.15 93.71 25.44 40.51 7.15 4.02 14.39 13.86 2.69 0.69
Banggai 4.22 2.58 20.46 54.67 2.51 92 97.49 23.46 34.8 12.65 1.43 8.24 15.06 2.11 0.55
Morowali 1.31 3.1 10.97 52.22 6.94 78.8 92.64 29.55 36.57 7.86 3.01 13.38 17.03 2.52 0.66
Poso 2.27 2.34 20.69 59.99 3.91 80.2 96.09 31.19 18.93 2.96 6.44 15.67 20.61 2.37 0.6
Donggala 2.78 7.8 20.79 37.79 5.54 78.83 93.94 19.22 33.03 3.11 5.01 13.8 12.27 1.9 0.46
Tolitoli 0 3.78 0.26 24.46 0.65 95.68 99.2 10.01 9.68 0.77 5.11 8.6 7.24 2.63 0.71
Buol 51.93 2.18 3.02 47.74 5.02 6.34 92.72 26.13 32.81 2.04 7.22 8.84 17.06 3.64 0.93

64
Parigi Moutong 35.8 2.11 7.72 48.96 10.69 5 86.62 25.58 34.03 4.16 3.31 7.9 19.66 2.59 0.57
Tojo Una-Una 18.72 11.85 19.12 76.71 9.38 6.65 89.14 19.52 15.13 0 13.36 7.21 15.04 2.47 0.66
Sigi 22.56 3.14 21.55 57.55 7.7 6.19 91.18 21.6 9.57 7.21 1.13 16.51 7.59 1.55 0.6
Kota Palu 3.3 3.11 19.7 72.37 4.97 5.02 94.49 14.73 5.39 0 3.97 11.84 5.77 2.32 0.35
Bolaang Mongondow 3.67 4.11 2.19 37.52 1.25 87.42 98.35 29.02 8.65 24.14 2.7 19.89 8.91 1.06 0.22
Minahasa 1.99 5.09 0.85 34.94 0.15 93.98 99.85 17.39 4.55 5.56 3.94 11.57 8.81 1.2 0.26
Kepulauan Sangihe 7.05 2.97 8.35 15.85 1.46 80.9 97.5 35.56 2.85 0.38 11.64 15.76 12.19 1.56 0.32
Kepulauan Talaud 2.57 1.77 1.94 31.68 0.34 94.73 99.06 18.28 19.72 4.22 10.78 9.1 10.27 1.5 0.35
Minahasa Selatan 4.92 2.94 0.35 48.18 0.18 86.65 99.62 21.51 7.52 4.18 3.3 18.76 10.08 1.8 0.46
Minahasa Utara 1.76 2.37 0.24 24.32 0.15 90.64 99.75 20.57 10 6.23 3.27 18.91 8.02 0.72 0.13
Bolaang Mongondow Utara 8.08 1.32 2.34 25.31 0.57 88.91 99.1 34.82 9.33 17.29 9.99 19.55 9.61 1.47 0.42
Kepulauan Sitaro 0.23 2.3 0.45 14.86 0.63 91.49 99.09 23.88 19.57 0.16 3.31 8.69 11.36 1.35 0.24
Minahasa Tenggara 2.26 1.19 0.1 38.19 0 90.52 99.97 19.1 9.3 0.65 1.53 15.62 16.1 3.14 0.98
Bolaang Mongondow Selatan 10.95 4.29 1.14 28.79 0.16 86.93 99.84 24.62 5.78 10.19 17.31 16.11 15.28 1.74 0.3
Bolaang Mongondow Timur 0.42 4.34 0.1 43.54 0.46 92.72 99.1 25.98 16.79 10.91 6.85 6.75 6.92 0.63 0.1
Kota Manado 0.82 7.38 0.15 9.41 0.09 92.81 99.85 13.84 25.62 1.08 2.1 10.12 4.88 0.67 0.17
Bitung 1.37 2.89 0.93 12.56 0.31 89.93 99.53 19.33 6.31 0.47 2.86 17 6.45 0.94 0.2
Kota Tomohon 0.62 8.78 0 23.14 0.08 93.3 99.77 17.75 27.76 3.67 0.5 9.33 6.57 1.27 0.42
Kota Kotamobagu 0.53 4.61 0.24 11.11 0.33 92.69 99.5 19.78 21.62 2.98 4.36 11.93 5.98 0.4 0.05
Boalemo 12.85 21.32 13.31 26.82 4.68 96.29 95.32 44.72 11.41 46.81 12.97 21.39 21.79 4.73 1.61
Gorontalo 21.41 18.18 7.91 57.28 1.97 78.76 98.03 36.74 12.68 42.03 8.84 15.58 21.57 4.26 1.18
Pohuwato 26.11 15.87 6.26 66.14 1.04 78.58 98.96 35.7 14.26 28.14 16.85 28.31 21.47 4.66 1.45
Bone Bolango 26.16 22.39 8.67 46.48 0 83.02 0 32.63 15.45 51.54 10 19.65 17.2 2.64 1.68
Gorontalo Utara 21.89 12.59 8.29 38.4 1.05 73.86 98.95 37.74 13.94 42.6 15.15 20.54 19.16 1.26 0.77
Kota Gorontalo 18.49 14.4 0.55 61.49 0.37 96.57 99.63 19.19 15.21 19.19 10.4 23.88 5.99 0.65 0.1
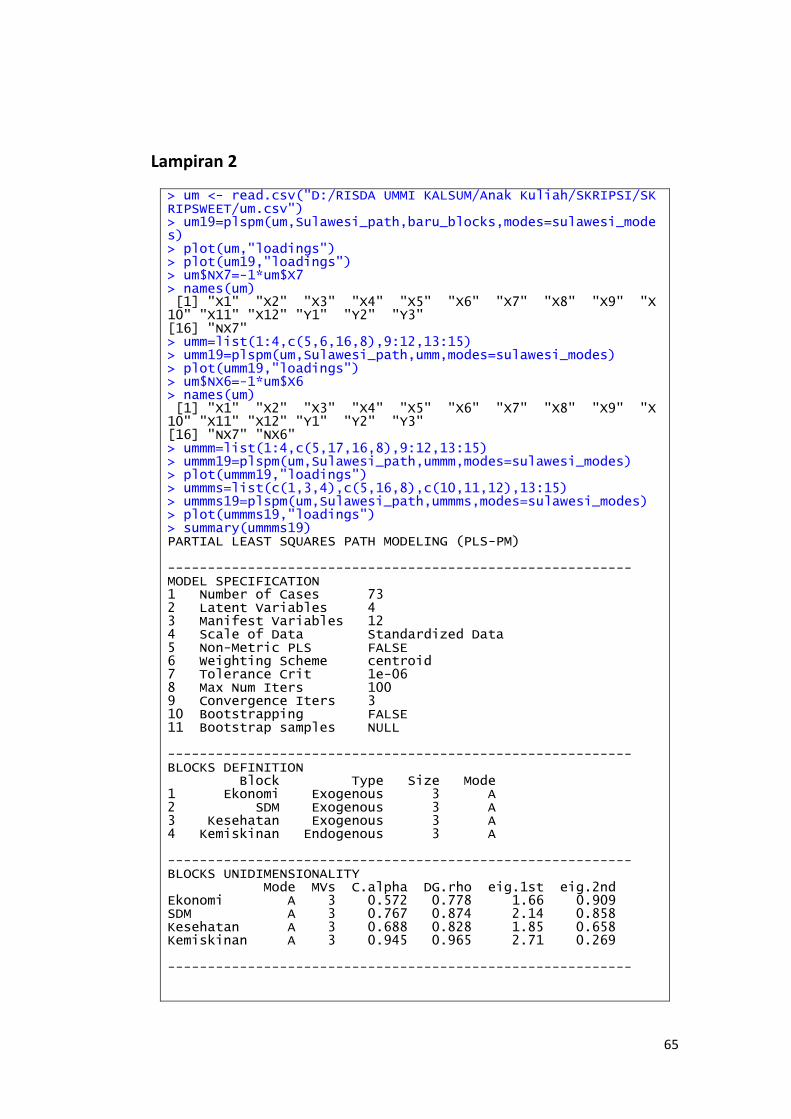
65
Lampiran 2
> um <- read.csv("D:/RISDA UMMI KALSUM/Anak Kuliah/SKRIPSI/SKRIPSWEET/um.csv") > um19=plspm(um,Sulawesi_path,baru_blocks,modes=sulawesi_modes) > plot(um,"loadings") > plot(um19,"loadings") > um$NX7=-1*um$X7 > names(um) [1] "X1" "X2" "X3" "X4" "X5" "X6" "X7" "X8" "X9" "X10" "X11" "X12" "Y1" "Y2" "Y3" [16] "NX7" > umm=list(1:4,c(5,6,16,8),9:12,13:15) > umm19=plspm(um,Sulawesi_path,umm,modes=sulawesi_modes) > plot(umm19,"loadings") > um$NX6=-1*um$X6 > names(um) [1] "X1" "X2" "X3" "X4" "X5" "X6" "X7" "X8" "X9" "X10" "X11" "X12" "Y1" "Y2" "Y3" [16] "NX7" "NX6" > ummm=list(1:4,c(5,17,16,8),9:12,13:15) > ummm19=plspm(um,Sulawesi_path,ummm,modes=sulawesi_modes) > plot(ummm19,"loadings") > ummms=list(c(1,3,4),c(5,16,8),c(10,11,12),13:15) > ummms19=plspm(um,Sulawesi_path,ummms,modes=sulawesi_modes) > plot(ummms19,"loadings") > summary(ummms19) PARTIAL LEAST SQUARES PATH MODELING (PLS-PM) ---------------------------------------------------------- MODEL SPECIFICATION 1 Number of Cases 73 2 Latent Variables 4 3 Manifest Variables 12 4 Scale of Data Standardized Data 5 Non-Metric PLS FALSE 6 Weighting Scheme centroid 7 Tolerance Crit 1e-06 8 Max Num Iters 100 9 Convergence Iters 3 10 Bootstrapping FALSE 11 Bootstrap samples NULL ---------------------------------------------------------- BLOCKS DEFINITION Block Type Size Mode 1 Ekonomi Exogenous 3 A 2 SDM Exogenous 3 A 3 Kesehatan Exogenous 3 A 4 Kemiskinan Endogenous 3 A ---------------------------------------------------------- BLOCKS UNIDIMENSIONALITY Mode MVs C.alpha DG.rho eig.1st eig.2nd Ekonomi A 3 0.572 0.778 1.66 0.909 SDM A 3 0.767 0.874 2.14 0.858 Kesehatan A 3 0.688 0.828 1.85 0.658 Kemiskinan A 3 0.945 0.965 2.71 0.269 ----------------------------------------------------------

66
OUTER MODEL weight loading communality redundancy Ekonomi 1 X1 0.516 0.667 0.445 0.000 1 X3 0.493 0.762 0.580 0.000 1 X4 0.366 0.765 0.585 0.000 SDM 2 X5 0.246 0.703 0.494 0.000 2 NX7 0.246 0.703 0.494 0.000 2 X8 0.742 0.882 0.778 0.000 Kesehatan 3 X10 0.553 0.845 0.714 0.000 3 X11 0.459 0.762 0.580 0.000 3 X12 0.255 0.721 0.520 0.000 Kemiskinan 4 Y1 0.351 0.908 0.825 0.423 4 Y2 0.360 0.981 0.962 0.493 4 Y3 0.342 0.958 0.919 0.471 ---------------------------------------------------------- CROSSLOADINGS Ekonomi SDM Kesehatan Kemiskinan Ekonomi 1 X1 0.667358 0.446 0.38940 0.463 1 X3 0.761829 0.226 0.07462 0.442 1 X4 0.764987 0.216 -0.00275 0.328 SDM 2 X5 0.372366 0.703 -0.15409 0.184 2 NX7 0.372366 0.703 -0.15409 0.184 2 X8 0.320186 0.882 0.60744 0.555 Kesehatan 3 X10 0.255910 0.377 0.84503 0.488 3 X11 0.207604 0.293 0.76160 0.405 3 X12 0.000629 0.126 0.72095 0.225 Kemiskinan 4 Y1 0.558080 0.525 0.42670 0.908 4 Y2 0.548132 0.467 0.53431 0.981 4 Y3 0.535427 0.437 0.49904 0.958 ---------------------------------------------------------- INNER MODEL $Kemiskinan Estimate Std. Error t value Pr(>|t|) Intercept -6.70e-17 0.0840 -7.97e-16 1.00e+00 Ekonomi 4.11e-01 0.0930 4.42e+00 3.59e-05 SDM 2.02e-01 0.0975 2.07e+00 4.24e-02 Kesehatan 3.40e-01 0.0911 3.73e+00 3.84e-04 ---------------------------------------------------------- CORRELATIONS BETWEEN LVs Ekonomi SDM Kesehatan Kemiskinan Ekonomi 1.000 0.421 0.237 0.577 SDM 0.421 1.000 0.375 0.502 Kesehatan 0.237 0.375 1.000 0.513 Kemiskinan 0.577 0.502 0.513 1.000 ---------------------------------------------------------- SUMMARY INNER MODEL Type R2 Block_Communality Mean_Redundancy AVE Ekonomi Exogenous 0.000 0.537 0.000 0.537 SDM Exogenous 0.000 0.589 0.000 0.589
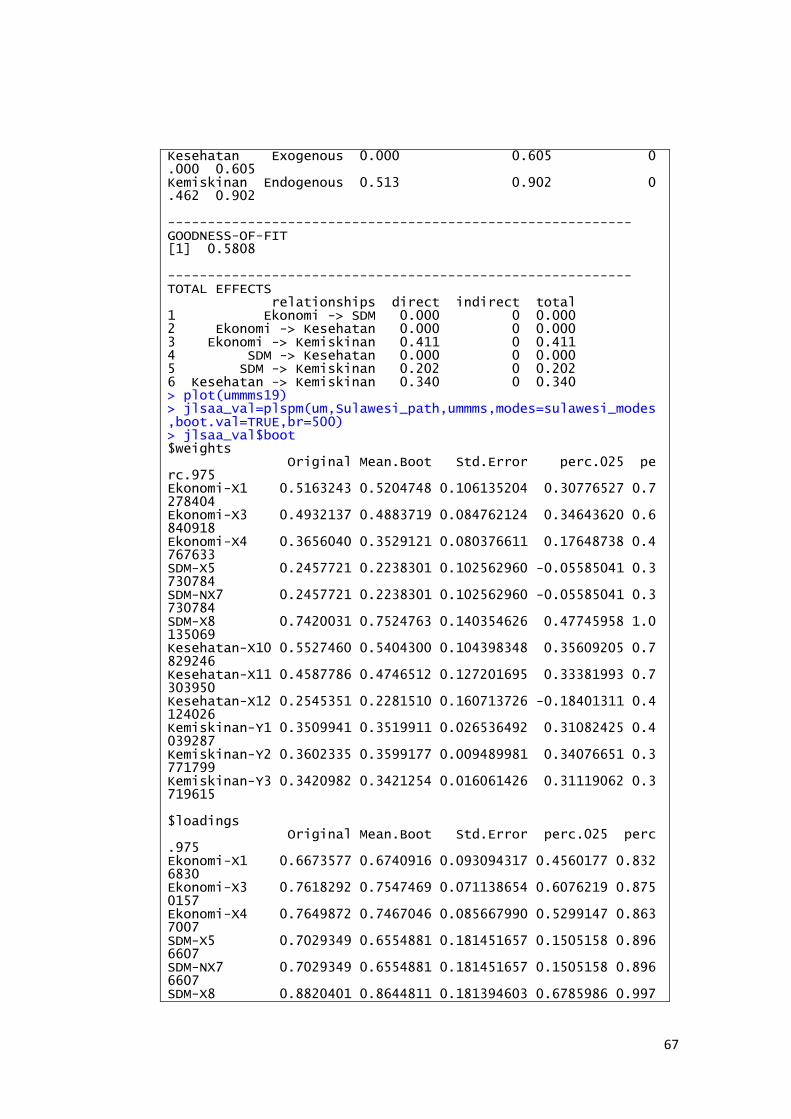
67
Kesehatan Exogenous 0.000 0.605 0.000 0.605 Kemiskinan Endogenous 0.513 0.902 0.462 0.902 ---------------------------------------------------------- GOODNESS-OF-FIT [1] 0.5808 ---------------------------------------------------------- TOTAL EFFECTS relationships direct indirect total 1 Ekonomi -> SDM 0.000 0 0.000 2 Ekonomi -> Kesehatan 0.000 0 0.000 3 Ekonomi -> Kemiskinan 0.411 0 0.411 4 SDM -> Kesehatan 0.000 0 0.000 5 SDM -> Kemiskinan 0.202 0 0.202 6 Kesehatan -> Kemiskinan 0.340 0 0.340 > plot(ummms19) > jlsaa_val=plspm(um,Sulawesi_path,ummms,modes=sulawesi_modes,boot.val=TRUE,br=500) > jlsaa_val$boot $weights Original Mean.Boot Std.Error perc.025 perc.975 Ekonomi-X1 0.5163243 0.5204748 0.106135204 0.30776527 0.7278404 Ekonomi-X3 0.4932137 0.4883719 0.084762124 0.34643620 0.6840918 Ekonomi-X4 0.3656040 0.3529121 0.080376611 0.17648738 0.4767633 SDM-X5 0.2457721 0.2238301 0.102562960 -0.05585041 0.3730784 SDM-NX7 0.2457721 0.2238301 0.102562960 -0.05585041 0.3730784 SDM-X8 0.7420031 0.7524763 0.140354626 0.47745958 1.0135069 Kesehatan-X10 0.5527460 0.5404300 0.104398348 0.35609205 0.7829246 Kesehatan-X11 0.4587786 0.4746512 0.127201695 0.33381993 0.7303950 Kesehatan-X12 0.2545351 0.2281510 0.160713726 -0.18401311 0.4124026 Kemiskinan-Y1 0.3509941 0.3519911 0.026536492 0.31082425 0.4039287 Kemiskinan-Y2 0.3602335 0.3599177 0.009489981 0.34076651 0.3771799 Kemiskinan-Y3 0.3420982 0.3421254 0.016061426 0.31119062 0.3719615 $loadings Original Mean.Boot Std.Error perc.025 perc.975 Ekonomi-X1 0.6673577 0.6740916 0.093094317 0.4560177 0.8326830 Ekonomi-X3 0.7618292 0.7547469 0.071138654 0.6076219 0.8750157 Ekonomi-X4 0.7649872 0.7467046 0.085667990 0.5299147 0.8637007 SDM-X5 0.7029349 0.6554881 0.181451657 0.1505158 0.8966607 SDM-NX7 0.7029349 0.6554881 0.181451657 0.1505158 0.8966607 SDM-X8 0.8820401 0.8644811 0.181394603 0.6785986 0.997
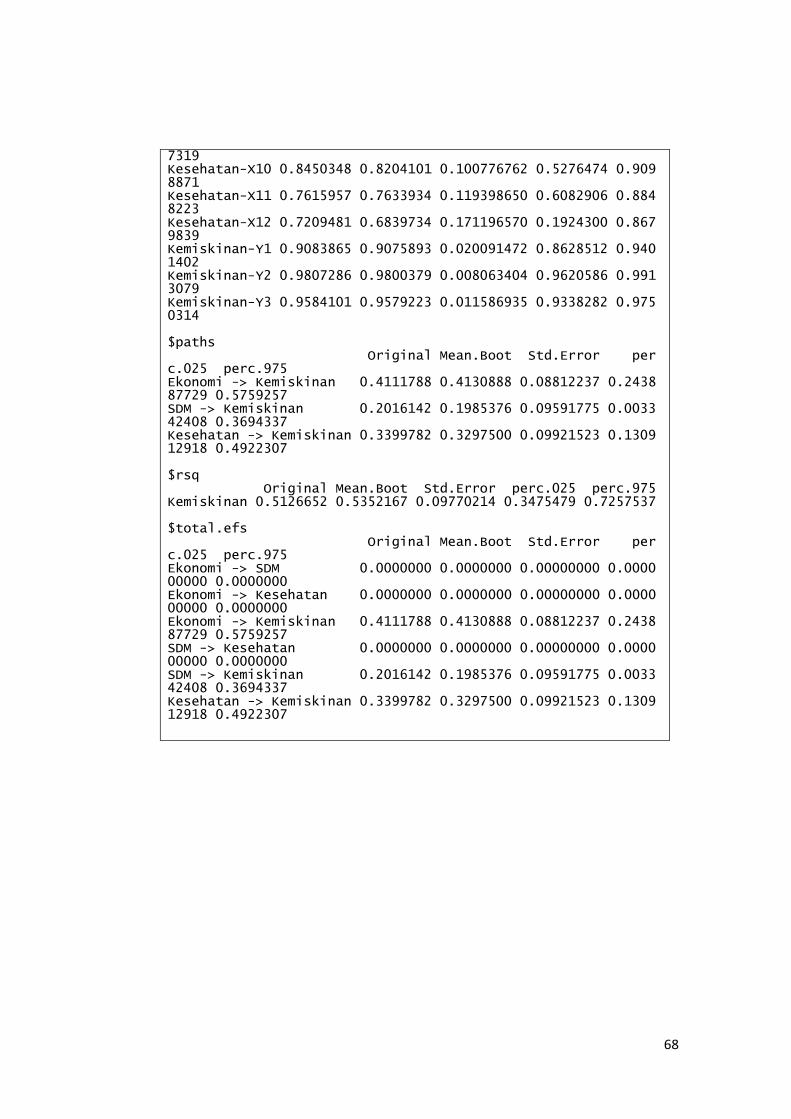
68
7319 Kesehatan-X10 0.8450348 0.8204101 0.100776762 0.5276474 0.9098871 Kesehatan-X11 0.7615957 0.7633934 0.119398650 0.6082906 0.8848223 Kesehatan-X12 0.7209481 0.6839734 0.171196570 0.1924300 0.8679839 Kemiskinan-Y1 0.9083865 0.9075893 0.020091472 0.8628512 0.9401402 Kemiskinan-Y2 0.9807286 0.9800379 0.008063404 0.9620586 0.9913079 Kemiskinan-Y3 0.9584101 0.9579223 0.011586935 0.9338282 0.9750314 $paths Original Mean.Boot Std.Error perc.025 perc.975 Ekonomi -> Kemiskinan 0.4111788 0.4130888 0.08812237 0.243887729 0.5759257 SDM -> Kemiskinan 0.2016142 0.1985376 0.09591775 0.003342408 0.3694337 Kesehatan -> Kemiskinan 0.3399782 0.3297500 0.09921523 0.130912918 0.4922307 $rsq Original Mean.Boot Std.Error perc.025 perc.975 Kemiskinan 0.5126652 0.5352167 0.09770214 0.3475479 0.7257537 $total.efs Original Mean.Boot Std.Error perc.025 perc.975 Ekonomi -> SDM 0.0000000 0.0000000 0.00000000 0.000000000 0.0000000 Ekonomi -> Kesehatan 0.0000000 0.0000000 0.00000000 0.000000000 0.0000000 Ekonomi -> Kemiskinan 0.4111788 0.4130888 0.08812237 0.243887729 0.5759257 SDM -> Kesehatan 0.0000000 0.0000000 0.00000000 0.000000000 0.0000000 SDM -> Kemiskinan 0.2016142 0.1985376 0.09591775 0.003342408 0.3694337 Kesehatan -> Kemiskinan 0.3399782 0.3297500 0.09921523 0.130912918 0.4922307