penyusunan traffic analysis zone dengan...
TRANSCRIPT

Habibi Lubis Penyusunan Traffic AnalysisZone Dengan Metoda Aggregasi Unit Kelurahan Berdasarkan Prinsip Homogenitas Kawasan Jurnal Perencanaan Wilayah dan Kota, Vol. 20 No. 3, Desember 2009, hlm 167 – 182
167
PENYUSUNAN TRAFFIC ANALYSIS ZONE DENGAN METODA AGGREGASI UNIT KELURAHAN
BERDASARKAN PRINSIP HOMOGENITAS KAWASAN
Habibi Lubis
Kelompok Keahlian Sistem Infrastruktur Wilayah dan Kota Sekolah Arsitektur, Perencanaan, dan Pengembangan Kebijakan
Institut Teknologi Bandung Labtek IX A, Jl. Ganesha 10, Bandung 40132
Abstrak
Pergerakan orang atau barang lazim digambarkan dengan matriks asal-tujuan (MAT).Lokasi asal dan tujuan pergerakan adalah lokasi berbasis zona yang dikenal dengan istilah Traffic Analysis Zone (TAZ). Untuk menghasilkan data MAT yang baik, TAZ yang optimal mutlak diperlukan. Untuk itu, penelitian ini bertujuan untuk menyusun TAZ yang optimal dengan metoda aggregasi unit kelurahan dengan mempertimbangkan aspek homogenitas a-spatial dan spatial telah diusulkan dan dibahas dalam tugas akhir ini untuk wilayah studi Kota Bandung. Kerangka homogenitas a-spatial kawasan yang disusun dalam studi ini membagi unit kelurahan Kota Bandung kedalam empat cluster. Masing-masing cluster diasumsikan sudah memiliki tingkat homogenitas yang tinggi dalam satu cluster dan memiliki tingkat heterogenitas yang tinggi antar cluster. Hal ini telah dibuktikan dengan nilai varian dalam cluster yang rendah dan varian intercluster yang tinggi. Dengan metoda aggregasi spatial dari 139 zona awal diperoleh 40 zona berdasarkan kerangka homogenitas a-spatial yang sudah disusun sebelumya. TAZ yang mencirikan homogenitas di dalamnya (optimal) sudah dihasilkan , sehingga antara satu zona cukup berbeda dengan zona lain di sekitarnya. Ini dibuktikan dengan Moran’s I yang menunjukkan zona yang terbentuk semakin berbeda dengan zona di sekelilingnya (random). Kata kunci: Traffic Analysis Zone (TAZ), Cluster, Agregasi
Abstract
Movements of people or goods are commonly described by origin-destination matrix (MAT). Location of origin and destination is the location-based movement of the zone known as Traffic Analysis Zone (TAZ). To produce good MAT data, optimal TAZ is absolutely necessary. Therefore, this study aims to develop an optimal TAZ with administrative unit aggregation method by considering aspects of homogeneity of a-spatial and spatial that has been proposed and discussed in this study for study region of city of Bandung. Homogeneity of a-spatial framework area compiled in this study divides the city of Bandung administrative unit into four clusters. Each cluster is assumed to already have a high degree of homogeneity within a cluster and have a high level inter-cluster heterogeneity. It has been proved by the low variance in the cluster and high intercluster variance. With the spatial aggregation method of the 139 starting zone obtained 40 zones based on the homogeneity of a-spatial framework that has been prepared previously. TAZ that characterize the homogeneity in (optimal) is produced, thus quite different from one zone to another zone in the vicinity. This is evidenced by the Moran's I, which shows the different zones formed by the surrounding zone (random). Keywords: Traffic Analysis Zone (TAZ), Cluster, Aggregation

Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
168
1. Pendahuluan
Pengetahuan tentang pergerakan orang atau
barang antar suatu kawasan yang lazim
dikenal dengan interaksi antar kawasan
merupakan informasi penting perencanaan
transportasi (Meyer & Miller, 2001; 181).
Adanya informasi yang baik tentang
pergerakan orang dan atau barang akan sangat
membantu dalam menyelesaikan permasalahan
transportasi perkotaan. Informasi yang
menggambarkan pergerakan orang dan atau
barang umumnya digambarkan dalam bentuk
matrik asal-tujuan pergerakan (MAT). Data
MAT mencerminkan besaran pergerakan dari
lokasi asal menuju lokasi tujuan dari sebuah
pergerakan. Pada perencanaan transportasi,
lokasi asal dan tujuan pergerakan merupakan
lokasi berbasis zona yang lazim dikenal
dengan Traffic Analysis Zone (TAZ). MAT
yang baik sangat dipengaruhi oleh penentuan
zona yang baik pula. Oleh karena itu zona
yang akurat mutlak diperlukan untuk
menghasilkan MAT yang benar-benar
menggambarkan data pergerakan.
Penentuan TAZ memang merupakan persoalan
yang pelik dalam sebuah analisis transportasi.
TAZ yang terlalu luas bisa mengurangi
keakuratan MAT karena akan menigkatkan
pergerakan internal zona yang seharusnya
menggambarkan pergerakan antar zona.
Sebaliknya TAZ yang terlalu kecil, juga dapat
mengurangi keakuratan MAT, karena dari
zona yang kecil seringkali terjadi zero traffic.
Zero traffic akan menyebabkan adanya sel
pada MAT yang kosong sehingga hal ini
kurang baik untuk peramalan pergerakan untuk
masa depan (lihat Meyer & Miller, 2001; 181).
Menurut Meyer & Miller (2001) TAZ yang
baik adalah TAZ yang di bangun berdasarkan
kesamaan karakteristik dari rumah tangga atau
sering disebut dengan istilah household base
zone. Namun, untuk mendapatkan informasi
berbasis rumah tangga membutuhkan dana dan
tenaga yang cukup mahal. Sehingga penentuan
TAZ umumnya dilakukan berdasarkan ciri
batasan fisik atau yang paling mudah adalah
batasan adminstrasi. Permasalahan zona yang
terlalu luas dan terlalu kecil merupakan
permasalahan yang muncul dari proses
penentuan TAZ yang dilakukan berdasarkan
batasan administrasi. Bandung sebagai daerah
studi memiliki TAZ yang terdiri dari 146 zona
yang ditentukan berdasarkan batas administrasi
kelurahan. Matriks asal tujuan yang dihasilkan
dari TAZ tersebut masih terlihat kejanggalan.
(1) adanya sel yang kosong, (2) jumlah rumah
tangga, jumlah populasi, jumlah trip bangkitan
dan tarikan yang belum sepadan antara satu
zona dengan zona lainnya. Dengan demikian
TAZ yang sudah ada belum optimal. Oleh
karena itu, sangat perlu adanya sebuah kajian
penentuan alternatif TAZ yang lebih optimal di
kota bandung sehingga mampu menghasilkan
MAT yang lebih baik.
2. Teori Dasar Penyusunan Traffic
Analysis Zone (TAZ) Berdasarkan
Prinsip Homogenitas Kawasan
Pergerakan lalu lintas di jalan raya pada
dasarnya bukan merupakan tujuan utama dari
para pelakunya.Tetapi merupakan kegiatan
yang diperlukan agar tujuan utama para pelaku
perjalanan tercapai. Tujuan utama dari para
pelaku perjalanan ditimbulkan oleh adanya
interaksi dari berbagai jenis aktivitas yang
letaknya tersebar dalam suatu wilayah. Bentuk
dari tujuan utama tersebut dapat bermacam-
macam, seperti bekerja, sekolah belanja,
rekreasi yang kesemuanya itu dapat dikatakan
sebagai aktivitas sosial dan ekonomi dalam
suatu sistem di suatu wilayah.

Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
169
Model Bangkitan-Tarikan Pergerakan (Trip
Generation Model)
Trip generation model adalah tahapan
pemodelan yang memperkirakan jumlah
pergerakan yang bersal dan menuju suatu zona
atau tata guna lahan tertentu. Dari pengertian
di atas maka dapat dikatakan bahwa
pergerakan lalu lintas merupakan fungsi tata
guna lahan yang menghasilkan pergerakan lalu
lintas. Penentuan trip generation model
merupakan tahap awal dalam pelaksanaan
sequential model.
Pada dasarnya dalam beberapa literatur,
bangkitan pergerakan dapat di analisis melalui
tiga tipe model yaitu analisis model faktor
pertumbuhan (growth factor), analisis regresi
dan cross-classification.
Model Growth Factor, model ini
digunakan untuk memproyeksikan
bangkitan pergerakan di masa mendatang
dengan mengalikan bangkitan pergerakan
dengan faktor pertumbuhan. Faktor
pengali pertumbuhan yang biasa
digunakan adalah seperti populasi
penduduk, pendapatan, kepemilikan
kendaraan, dll.
Model Regresi, analisis regresi
merupakan metode statistik yang
mempelajari bagaimana suatu variabel
tidak bebas berkaitan dengan beberapa
variabel bebas. Dalam hal ini variabel
tidak bebas yang digunakan adalah
bangkitan pergerakan.
Analisis cross classification atau analisis
kategori adalah metode untuk
menggrupkan rumah tangga kedalam satu
atau beberapa ciri sosial ekonomi tertentu.
Matriks Asal-Tujuan (Origin-Destination
Matrix)
Matriks O-D adalah matriks berdimensi dua
yang menggambarkan besarnya pergerakan
pergerakan antarlokasi (asal dan tujuan) dalam
daerah tertentu. Baris dari matriks menyatakan
asal pergerakan dan kolom menyatakan tujuan
pergerakan sedangkan isi sel dari matriks
menyatakan besarnya arus pergerakan antar
asal dan tujuan pergerakan terkait. dalam hal
ini, notasi Tij digunakan untuk menyatakan
besarnya arus pergerakan kendaraan, orang
atau barang dari tempat asal i ke tempat tujuan
j selama selang waktu tertentu. Melalui matriks
O-D dapat dipelajari pola pergerakan orang
atau barang yang terjadi dalam daerah tertentu.
Dengan mengetahui pola pergerakan yang
terjadi maka akan membantu dalam memahami
permasalahan transportasi yang timbul
sehingga diharapkan beberapa solusi bisa
dihasilkan.
Secara umum ada dua metode untuk
mendapatkan matriks O-D yaitu metode
konvensional dan metode non-konvensinal
(Tamin, 2003).Metode konvensional dibagi
lagi kedalam dua jenis yaitu metoda langsung
dan tidak langsung. Metoda langsung adalah
metoda untuk mendapatkan data secara
langsung terjun ke lapangan seperti wawancara
di tepi jalan, wawancara di rumah,
menggunakan bendera, metode foto udara, dan
lain-lain.Metoda tidak langsung dilakukan
dengan mengolah data-data sekunder melalui
pendekatan rumus-rumus matematis.Metoda
yg umum digunakan adalah metode analogi
dan metode sintetis.Metode non-konvensional
adalah metode yang menggunakan informasi
data arus lalu lintas untuk mendapatkan nilai
matriks O-D.
Traffic Analysis Zone
Seharusnya sebuah zona memiliki alasan yang
kuat untuk mengatakan bahwa sebuah wilayah

Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
170
dikatakan sebuah zona pergerakan.alasan ini
penting untuk mebedakan suatu zona dengan
zona yang lain. Menurut Bass (1981) dalam
Meyer & Miller (2001;181) ada enam kriteria
untuk menentukan traffic analysis zone antara
lain:
1. Mendapatkan karakteristik sosial ekonomi
yang homogen dalam satu zona.
2. Meminimalisasi jumlah pergerakan
internal zona.
3. Mempertimbangkan batasan fisik, politis,
kekuasaan, dan sejarah.
4. Menghindari zona yang sepenuhnya
berada dalam lingkup zona lainnya.
5. Mempertimbangkan agar sistem zona
memiliki jumlah rumah tangga, populasi,
bangkitan datarikan pergerakan yang
seimbang antara satu zona dengan zona
lainnya.
6. Basis batasan zona didasarkan pada sensus
block.
Kriteria yang terakhir sangat penting karena
beberapa negara biasanya menyediakan data
sosial ekonomi penduduk berdasarkan sensus
block. Adanya data sekunder akan
mempermudah untuk penyusunan traffic
analysis zone karena pada kenyataanya cara
survey langsung terhadap rumah tangga cukup
rumit, dan membutuhkan banyak tenaga dan
biaya. Oleh karena itu, pada umumnya traffic
analysis zone yang digunakan adalah zona
berbasis satuan wilayah administratif yang
lebih luas seperti kecamatan atau
kabupaten/kota.
Metoda identifikasi Homogenitas dengan
Analisis Cluster
Analisis Cluster (cluster Analysis) merupakan
metode untuk mengelompokkan objek-objek
yang lebih banyak ke dalam objek yang lebih
sedikit (Dillon, 1984; Kachigan 1986).
Analisis cluster disebut juga analisis
segmentasi atau analisis taksonomi.Dalam
ilmu perencanaan kota, analsis cluster juga
sudah sering digunakan, misalnya untuk
menetukan hirarki dari kota-kota, menentukan
struktur pola kota, distribusi kelas sosial
ekonomi masyarakat dalam kota, dan lain-lain
(John, 1988). Prinsip dalam analisis cluster
adalah mengupayakan agar cluster yang
terbentuk memiliki kesamaan yang tinggi antar
anggotanya (homogenitas) dan memiliki
perbedaan atau jarak yang jauh dengan cluster
yang lain (heterogenitas). Untuk melihat nilai
homogenitas dan heterogenitas antar objek
dalam analisis cluster, metode yang sering
digunakan adalah adalah dengan mengukur
similarity (derajat kesamaan) dari masing-
masing objek. Ada dua metode untuk
mengukur similarity yang biasa digunakan
yaitu mengukur nilai koefisien korelasi (rij)
dan jarak euclidean (dij). Analisis cluster
adalah sebuah proses memilah objek
berdasarkan ciri kesamaan variabel dalam
masing-masing objek. Proses pemilahan objek
umumnya dilakukan melalui dua cara yaitu
non-hierarchical atau Partitioning method dan
hierarchical method.
Jika pada sebuah koleksi data terdapat n objek,
maka metode partisioning akan mebentuk k
patisi data, setiap partisi merepresentasikan
sebuah cluster dan k ≤ n. Dengan kata lain,
metode partisioning menklasifikasikan data
menjadi beberapa kelompok dengan ketentuan
bahwa setiap kelompok harus berisi paling
tidak satu data item, dan setiap data item harus
menjadi anggota dari sebuah kelompok.
Setelah mengetahui k, yaitu jumlah partisi
yang harus dibangun, sebuha metode
partisioning akan membentuk partisi awal.
Kemudian, metode tersebut akan secara
uteratif berusaha menigkatkan akurasi partisi
yang terbentuk dengan cara memindahkan

Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
171
objek dari satu kelompok ke kelompok yang
lain.
Metode hierarchical akan membangun sebuah
dekomposisi hierarkis dari satu himpunan data
tertentu. Metode hierarchical dapat
diklasifikasikan lebih lanjut menjadi bersifat
divisive atau bersifat agglomerative,
berdasarkan bagaimana dekomposisi hierarkis
yang akan dibangun. Pendekatan
agglomerative, yang juga disebut sebagai
pendekatan bottom-up, dimulai dengan
masing-masing objek membentuk sebuah
kelompok terpisah. Pendekatan tersebut
kemudian akan menyatukan objek-objek yang
saling berdekatan, sehingga semua kelompok
pada akhirnya menjadi satu, atau sehingga
sebuah kondisi berhenti tertentu.Sedangkan
pendekatan divisive, atau yang disebut juga
sebagai pendekatan top-down, dimulai dengan
seluruh objek berada pada sebuah cluster yang
sama. Kemudian, pada setiap iterasi, cluster
akan dipecah menjadi cluster-cluster yang
lebih kecil sehingga suatu kondisi berhenti
tertentu.
Spatial Autocorrelation
Tujuan utama analisis data spasial dalam studi
ini adalah untuk meningkatkan homogenitas
dalam satu cluster zona dan meningkatkan
heterogenitas antar cluster zona yang telah
dibuat. Seharusnya zona yang terbentuk adalah
random karena tujuan utama agregasi zona
transportasi adalah untuk menghilangkan zona-
zona pergerakan bertetangga yang memiliki
ciri kesamaan data sosial ekonomi dan guna
lahan. Asumsi awal adalah jika ada dua zona
yang memiliki ciri karakteristik zona yang
sama seharusnya tergabung menjadi dalam
satu zona. Dengan demikian maka zona-zona
yang terbentuk seharusnya memiliki ciri
karakteristik sosial ekonomi yang independen
sehingga masing-masing zona merupakan zona
yang benar-benar menjadi asal dan tujuan
pergerakan.Untuk melihat tingkat
independensi dari zona-zona yang terbentuk
maka bisa dilihat dari nilai spatial
autocorrelasi-nya. Melalui spatial
autocorrelation dapat dilihat apakah cluster
zona yang terbentuk random, berkorelasi
negatif, atau berkorelasi positif. Secara logis
dapat dipahami bahwa TAZ yang random atau
tanpa ada spatial autocorrelation adalah lebih
baik dari pada TAZ yang berkorelasi positif
maupun negatif. Untuk menghitung spatial
autocorrelation umumnya ada dua cara yang
sering dipakai yaitu Geary’s c dan Moran’s I.
jika GC = 1 spatial autocorrelation tidak
terjadi;
jika GC < 1, positive spatial autocorrelation
terjadi; dan
jika GC > 1, negative spatial autocorrelation
terjadi.
Jika n adalah jumlah unit spatial yang di
observasi maka nilai Moran’s I akan berada
diantara -1 sampai dengan 1. Nilai indeks
Moran semakin mendekati -1 menyatakan
bahwa negative spatial autocorrelation
(dispers) terjadi atau pola dispers yang mudah
dipahami adalah pola papan catur dimana unit
yang bernilai tinggi dikelilingi oleh tetangga
yang bernilai rendah dan sebaliknya. Indeks
Moran mendekati nilai harapan (expected
value) yang biasanya sangat dekat dengan nila
0 (nol) menyatakan tidak terjadi spatial
autocorrelation atau pola ini disebut juga
dengan random. Indeks Moran mendekati 1
menyatakan positive autocorrelation terjadi
(cluster). Pola cluster terjadi ketika unit yang
bernilai tinggi dikelilingi oleh tetangga yang
benilai tinggi dan sebalikya tetangga yang
bernilai rendah dikelilingi tetangga yang
bernilai rendah.

Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
172
GIS dan Teknik yang Digunakan dalam
Studi
Cowen dalam You (1996) mendefenisikan --
GIS is a planning support system which is
“involving the intergation of spatially
referenced data in a problem solving
environment.” Sebenarnya banyak perencana
ragu dengan defenisi ini. Jika agak sulit
menerima defenisi tersebut, maka defenisi dari
Burrough (dalam You, 1996) akan sangat
membantu; GIS are a powerful set of tolls for
colecting, storing, retrieving at will,
transforming, and displaying spatial data from
the real world for particular set of purposes.
Studi ini memanfaatkan sistem GIS dalam
beberapa tahapan analisis yang digunakan.
Lebih rinci, beberapa pemanfaatan tools GIS
dalam studi diperlihatkan dalam Tabel I
berikut ini.
Tabel I Penggunaan Aplikasi GIS Dalam Studi
View Fungsi Operasi yang Digunakan
Geodatabase
Pembangunan basis data dengan penggabungan data spasial dan data atribut
Start editing | add field Calculate Geeometri Summarize, sel
statistic Table | Join
Geoprocessing
Penggunaan operasi Dissolving, Clipping, intersecting/ Overlaying, dan Singgle to multy part
Analysis Tools | Extract |Clip
Analysis Tools | Overlay |intersec/union
Data Management Tolls | Generalization | Disolving
Data Management Tolls | Features | Multi part to single part
Spatial Analysis Spatial Index Moran’s
Spatial Statistical Tools | Analyzing pattern | spatial autocorrelation
Geovisualization Menampilkan peta-peta hasil analisis
View | Layout view
Sumber: Hasil analisis, 2008
Prinsip utama dalam penyusunan TAZ ini
adalah kesamaan ciri atau karakteristik dari
kawasan berdasarkan variabel-variabel sosial,
ekonomi, dan demografi. Kesamaan ini sering
juga disebut sebagai homogenitas.Pada
akhirnya Traffic Analysis Zone yang
dihasilkan, diharapkan memiliki kesamaan ciri
pada masing-masing zona. Tahapan
penyusunan TAZ yang dilakukan dalam studi
ini adalah seperti diperlihatkan pada gambar 1
berikut ini.
3. Penyusunan Traffic Analysis Zone
Dengan Metode Aggregasi Unit
Kelurahan Berdasarkan Prinsip
Homogenitas Kawasan
Berdasarkan Gambar 1, penyusunan TAZ pada
studi ini terdiri dari empat tahapan utama.
Keempat tahapan utama tersebut antara lain:
penentuan variabel penyusun TAZ,
membangun data berbasis GIS, penentuan
TAZ, dan visualisasi hasil (pemetaan TAZ).
Keempat tahapan tersebut akan dibahas
berikut.
Gambar 1 Langkah Penyusunan Traffic Analysis Zone
(TAZ) Berdasarkan Prinsip Homogenitas Kawasan
Sumber: Hasil Analisis, 2008
Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
173
Identifikasi Variabel-Variabel Untuk
Penyusunan TAZ
Untuk membangun sebuah TAZ maka
variabel-variabel harus memiliki hubungan dan
mampu menggambarkan aktivitas pergerakan
dari masing-masing zona.Untuk melihat
hubungan antara variabel-variabel dengan
bangkitan dan tarikan pergerakan, digunakan
79 unit zona yang masih memiliki ukuran sama
dengan batas kelurahan pada masa sekarang.
Sedangkan variabel-variabel yang digunakan
antara lain adalah ukuran keluarga, jumlah
penduduk, luas kawasan terbangun, luas
kawasan permukiman, panjang jalan, panjang
rute angkutan kota, dan jumlah fasilitas.
Dengan asumsi hubungan hubungan antara
variabel-variabel dengan bangkitan tarikan
bersifat linier maka hubungan antara masing-
masing variabel dengan bangkitan dan tarikan
pergerakan dilihat dengan regresi linier. Dari
hasil uji model terhadap bangkitan, dari
ketujuh variabel yang digunakan
memperlihatkan hubungan yang cukup kuat
yaitu dengan rata-rata R square antara 0,621 –
0,637. Hal ini menyatakan bahwa lebih dari
60% data memiliki hubungan linier dengan
bangkitan pergerakan.
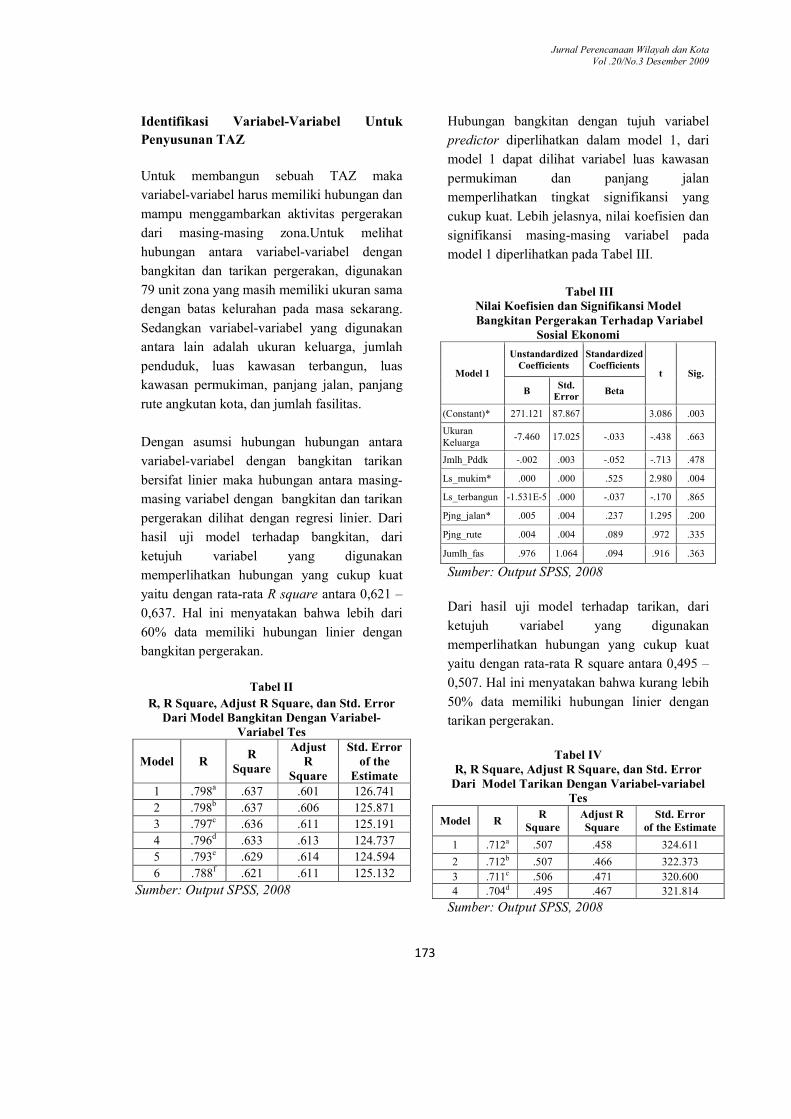
Tabel II
R, R Square, Adjust R Square, dan Std. Error Dari Model Bangkitan Dengan Variabel-
Variabel Tes
Model R R
Square
Adjust R
Square
Std. Error of the
Estimate 1 .798a .637 .601 126.741
2 .798b .637 .606 125.871
3 .797c .636 .611 125.191
4 .796d .633 .613 124.737
5 .793e .629 .614 124.594
6 .788f .621 .611 125.132
Sumber: Output SPSS, 2008
Hubungan bangkitan dengan tujuh variabel
predictor diperlihatkan dalam model 1, dari
model 1 dapat dilihat variabel luas kawasan
permukiman dan panjang jalan
memperlihatkan tingkat signifikansi yang
cukup kuat. Lebih jelasnya, nilai koefisien dan
signifikansi masing-masing variabel pada
model 1 diperlihatkan pada Tabel III.
Tabel III Nilai Koefisien dan Signifikansi Model Bangkitan Pergerakan Terhadap Variabel
Sosial Ekonomi
Model 1
Unstandardized Coefficients
Standardized Coefficients
t Sig.
B Std.
Error Beta
(Constant)* 271.121 87.867 3.086 .003
Ukuran Keluarga
-7.460 17.025 -.033 -.438 .663
Jmlh_Pddk -.002 .003 -.052 -.713 .478
Ls_mukim* .000 .000 .525 2.980 .004
Ls_terbangun -1.531E-5 .000 -.037 -.170 .865
Pjng_jalan* .005 .004 .237 1.295 .200
Pjng_rute .004 .004 .089 .972 .335
Jumlh_fas .976 1.064 .094 .916 .363
Sumber: Output SPSS, 2008
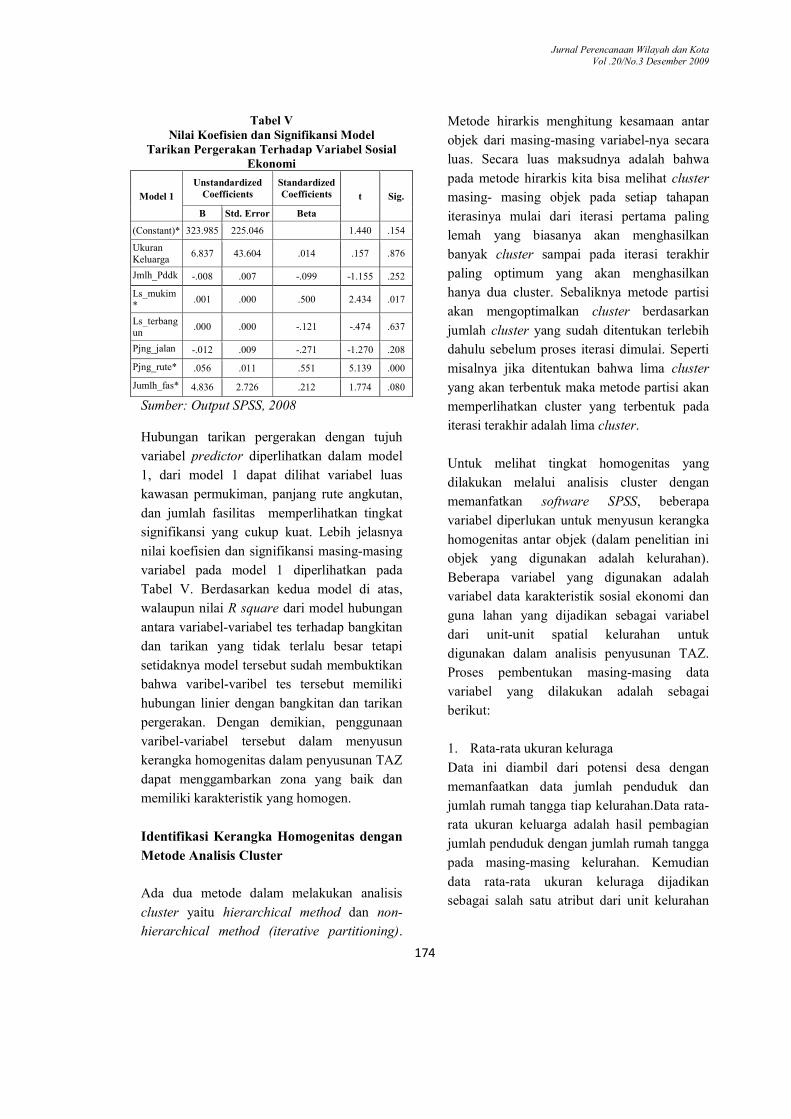
Dari hasil uji model terhadap tarikan, dari
ketujuh variabel yang digunakan
memperlihatkan hubungan yang cukup kuat
yaitu dengan rata-rata R square antara 0,495 –
0,507. Hal ini menyatakan bahwa kurang lebih
50% data memiliki hubungan linier dengan
tarikan pergerakan.
Tabel IV
R, R Square, Adjust R Square, dan Std. Error Dari Model Tarikan Dengan Variabel-variabel
Tes
Model R R
Square Adjust R Square
Std. Error of the Estimate
1 .712a .507 .458 324.611
2 .712b .507 .466 322.373
3 .711c .506 .471 320.600
4 .704d .495 .467 321.814
Sumber: Output SPSS, 2008
Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
174
Tabel V Nilai Koefisien dan Signifikansi Model
Tarikan Pergerakan Terhadap Variabel Sosial Ekonomi
Model 1
Unstandardized Coefficients
Standardized Coefficients t Sig.
B Std. Error Beta
(Constant)* 323.985 225.046 1.440 .154
Ukuran Keluarga
6.837 43.604 .014 .157 .876
Jmlh_Pddk -.008 .007 -.099 -1.155 .252
Ls_mukim*
.001 .000 .500 2.434 .017
Ls_terbangun
.000 .000 -.121 -.474 .637
Pjng_jalan -.012 .009 -.271 -1.270 .208
Pjng_rute* .056 .011 .551 5.139 .000
Jumlh_fas* 4.836 2.726 .212 1.774 .080
Sumber: Output SPSS, 2008 Hubungan tarikan pergerakan dengan tujuh
variabel predictor diperlihatkan dalam model
1, dari model 1 dapat dilihat variabel luas
kawasan permukiman, panjang rute angkutan,
dan jumlah fasilitas memperlihatkan tingkat
signifikansi yang cukup kuat. Lebih jelasnya
nilai koefisien dan signifikansi masing-masing
variabel pada model 1 diperlihatkan pada
Tabel V. Berdasarkan kedua model di atas,
walaupun nilai R square dari model hubungan
antara variabel-variabel tes terhadap bangkitan
dan tarikan yang tidak terlalu besar tetapi
setidaknya model tersebut sudah membuktikan
bahwa varibel-varibel tes tersebut memiliki
hubungan linier dengan bangkitan dan tarikan
pergerakan. Dengan demikian, penggunaan
varibel-variabel tersebut dalam menyusun
kerangka homogenitas dalam penyusunan TAZ
dapat menggambarkan zona yang baik dan
memiliki karakteristik yang homogen.
Identifikasi Kerangka Homogenitas dengan
Metode Analisis Cluster
Ada dua metode dalam melakukan analisis
cluster yaitu hierarchical method dan non-
hierarchical method (iterative partitioning).
Metode hirarkis menghitung kesamaan antar
objek dari masing-masing variabel-nya secara
luas. Secara luas maksudnya adalah bahwa
pada metode hirarkis kita bisa melihat cluster
masing- masing objek pada setiap tahapan
iterasinya mulai dari iterasi pertama paling
lemah yang biasanya akan menghasilkan
banyak cluster sampai pada iterasi terakhir
paling optimum yang akan menghasilkan
hanya dua cluster. Sebaliknya metode partisi
akan mengoptimalkan cluster berdasarkan
jumlah cluster yang sudah ditentukan terlebih
dahulu sebelum proses iterasi dimulai. Seperti
misalnya jika ditentukan bahwa lima cluster
yang akan terbentuk maka metode partisi akan
memperlihatkan cluster yang terbentuk pada
iterasi terakhir adalah lima cluster.
Untuk melihat tingkat homogenitas yang
dilakukan melalui analisis cluster dengan
memanfatkan software SPSS, beberapa
variabel diperlukan untuk menyusun kerangka
homogenitas antar objek (dalam penelitian ini
objek yang digunakan adalah kelurahan).
Beberapa variabel yang digunakan adalah
variabel data karakteristik sosial ekonomi dan
guna lahan yang dijadikan sebagai variabel
dari unit-unit spatial kelurahan untuk
digunakan dalam analisis penyusunan TAZ.
Proses pembentukan masing-masing data
variabel yang dilakukan adalah sebagai
berikut:
1. Rata-rata ukuran keluraga
Data ini diambil dari potensi desa dengan
memanfaatkan data jumlah penduduk dan
jumlah rumah tangga tiap kelurahan.Data rata-
rata ukuran keluarga adalah hasil pembagian
jumlah penduduk dengan jumlah rumah tangga
pada masing-masing kelurahan. Kemudian
data rata-rata ukuran keluraga dijadikan
sebagai salah satu atribut dari unit kelurahan

Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
175
dengan metoda joint table dalam software arc
view/gis.
2. Kepadatan Penduduk
Kepadatan penduduk merupakan hasil
pembagian jumlah penduduk terhadap luas
kelurahan. Data jumlah penduduk didapatkan
dari potensi desa sedangkan data luas
kelurahan didapatkan dari peta unit kelurahan
dari BAPPEDA dengan memanfaatkan
perintah calculate geometry pada software arc
view/gis. Proses penggabungan data kepadatan
penduduk untuk menjadi atribut dari unit
kelurahan dilakukan dengan perintah joint
tabel dalam software arc view/gis.
3. Rasio Kawasan Permukiman
Luas kawasan permukiman pada setiap
kelurahan didapatkan dengan metoda
menumpangtindihkan (overlay) peta batas unit
kelurahan dengan peta guna lahan dan
kemudian mengkalkulasikan luas kawasan
permukiman pada masing-masing desa dengan
perintah calculate geometry pada software arc
view/gis. Proses penggabungan data rasio
kawasan permukiman untuk menjadi atribut
dari unit kelurahan dilakukan dengan perintah
joint tabel dalam software arc view/gis.
4. Rasio Kawasan Terbangun
Rasio kawasan terbagun adalah luas kawasan
terbangun yang dinormalisasikan terhadap luas
unit kelurahan.Kawasan terbangun yang
dimaksudkan adalah semua kawasan buit-up
area pada kategori guna lahan dalam peta guna
lahan yang diperoleh dari DISTARKIM. Ada
pun proses pembentukan data dan penyatuan
menjadi atribut unit spatial kelurahan sama
seperti proses yang dilakukan pada rasio
kawasan permukiman.
5. Rasio Panjang Jalan
Rasio panjang jalan adalah panjang ruas jalan
yang dinormalisasikan terhadap luas unit
kelurahan. Data panjang jalan setiap
kelurarahan didapatkan dengan metoda
menumpangtindihkan (overlay) peta batas unit
kelurahan dengan peta ruas jalan dan
kemudian mengkalkulasikan luas panjang ruas
jalan pada masing-masing desa dengan
perintah calculate length pada software arc
view/gis. Proses penggabungan data rasio
kawasan permukiman untuk menjadi atribut
dari unit kelurahan dilakukan dengan perintah
joint tabel dalam software arc view/gis.
6. Rasio Panjang Rute Angkutan
Rasio panjang rute angkutan adalah panjang
jalan yang dilalui rute angkutan kota pada
masing-masing kelurahan yang
dinormalisasikan terhadap luas unit kelurahan.
Peta rute angkutan didapatkan dari peta dalam
program JJDB (jalan-jalan di bandung yuk!)
yang dikeluarkan oleh perusahaan ELCEE
pada tahun 2003. Ada pun proses pembentukan
data dan penyatuan menjadi atribut unit spatial
kelurahan sama seperti proses yang dilakukan
pada rasio panjang jalan.
7. Rasio Jumlah Fasilitas
Rasio jumlah faslitas adalah rata-rata jumlah
fasilitas dalam setiap satu hektar lahan pada
masing-masing kelurahan.Data jumlah fasilitas
didapatkan dari potensi desa. Adapun fasilitas
yang dimaksudkan adalah fasilitas-fasilitas
sosial dan ekonomi yang mungkin
mempengaruhi aktivitas pergeraka dari
masyarakat antara lain fasilitas sekolah (SD,
SMP, SMA, dan PT), fasilitas kesehatan
(rumah sakit, rumah sakit bersalin, poliklinik,
dan posyandu), hotel/penginapan, bank, dan
pusat perbelanjaan. Semua unit fasilitas
dujumlahkan dengan bobot yang sama pada
setiap unit kelurahan. Kemudian data rasio
jumlah faslitas dijadikan sebagai salah satu
atribut dari unit kelurahan dengan metoda joint
table dalam software arc view/gis.
Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
176
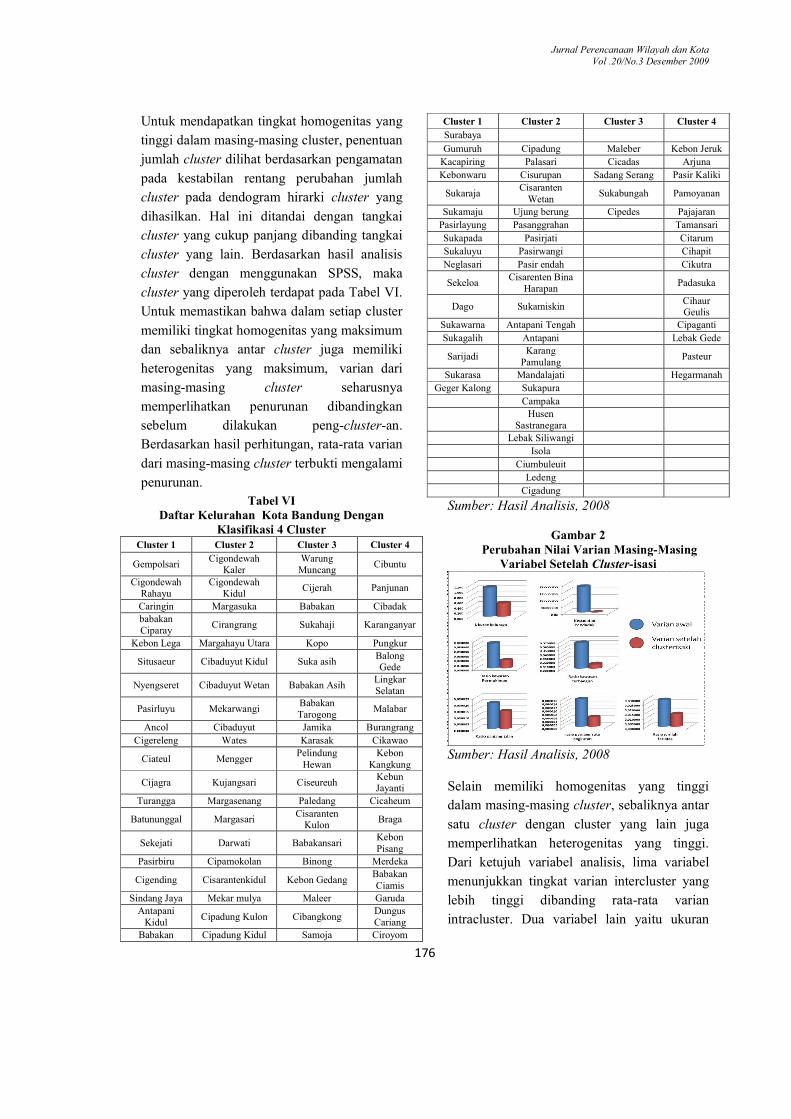
Untuk mendapatkan tingkat homogenitas yang
tinggi dalam masing-masing cluster, penentuan
jumlah cluster dilihat berdasarkan pengamatan
pada kestabilan rentang perubahan jumlah
cluster pada dendogram hirarki cluster yang
dihasilkan. Hal ini ditandai dengan tangkai
cluster yang cukup panjang dibanding tangkai
cluster yang lain. Berdasarkan hasil analisis
cluster dengan menggunakan SPSS, maka
cluster yang diperoleh terdapat pada Tabel VI.
Untuk memastikan bahwa dalam setiap cluster
memiliki tingkat homogenitas yang maksimum
dan sebaliknya antar cluster juga memiliki
heterogenitas yang maksimum, varian dari
masing-masing cluster seharusnya
memperlihatkan penurunan dibandingkan
sebelum dilakukan peng-cluster-an.
Berdasarkan hasil perhitungan, rata-rata varian
dari masing-masing cluster terbukti mengalami
penurunan.
Tabel VI Daftar Kelurahan Kota Bandung Dengan
Klasifikasi 4 Cluster Cluster 1 Cluster 2 Cluster 3 Cluster 4
Gempolsari Cigondewah
Kaler Warung
Muncang Cibuntu
Cigondewah Rahayu
Cigondewah Kidul
Cijerah Panjunan
Caringin Margasuka Babakan Cibadak
babakan Ciparay
Cirangrang Sukahaji Karanganyar
Kebon Lega Margahayu Utara Kopo Pungkur
Situsaeur Cibaduyut Kidul Suka asih Balong Gede
Nyengseret Cibaduyut Wetan Babakan Asih Lingkar Selatan
Pasirluyu Mekarwangi Babakan Tarogong
Malabar
Ancol Cibaduyut Jamika Burangrang
Cigereleng Wates Karasak Cikawao
Ciateul Mengger Pelindung
Hewan Kebon
Kangkung
Cijagra Kujangsari Ciseureuh Kebun Jayanti
Turangga Margasenang Paledang Cicaheum
Batununggal Margasari Cisaranten
Kulon Braga
Sekejati Darwati Babakansari Kebon Pisang
Pasirbiru Cipamokolan Binong Merdeka
Cigending Cisarantenkidul Kebon Gedang Babakan Ciamis
Sindang Jaya Mekar mulya Maleer Garuda
Antapani Kidul
Cipadung Kulon Cibangkong Dungus Cariang
Babakan Cipadung Kidul Samoja Ciroyom
Cluster 1 Cluster 2 Cluster 3 Cluster 4
Surabaya
Gumuruh Cipadung Maleber Kebon Jeruk
Kacapiring Palasari Cicadas Arjuna
Kebonwaru Cisurupan Sadang Serang Pasir Kaliki
Sukaraja Cisaranten
Wetan Sukabungah Pamoyanan
Sukamaju Ujung berung Cipedes Pajajaran
Pasirlayung Pasanggrahan
Tamansari
Sukapada Pasirjati
Citarum
Sukaluyu Pasirwangi
Cihapit
Neglasari Pasir endah
Cikutra
Sekeloa Cisarenten Bina
Harapan Padasuka
Dago Sukamiskin
Cihaur Geulis
Sukawarna Antapani Tengah
Cipaganti
Sukagalih Antapani
Lebak Gede
Sarijadi Karang
Pamulang Pasteur
Sukarasa Mandalajati
Hegarmanah
Geger Kalong Sukapura
Campaka
Husen
Sastranegara
Lebak Siliwangi
Isola
Ciumbuleuit
Ledeng
Cigadung
Sumber: Hasil Analisis, 2008
Gambar 2
Perubahan Nilai Varian Masing-Masing Variabel Setelah Cluster-isasi
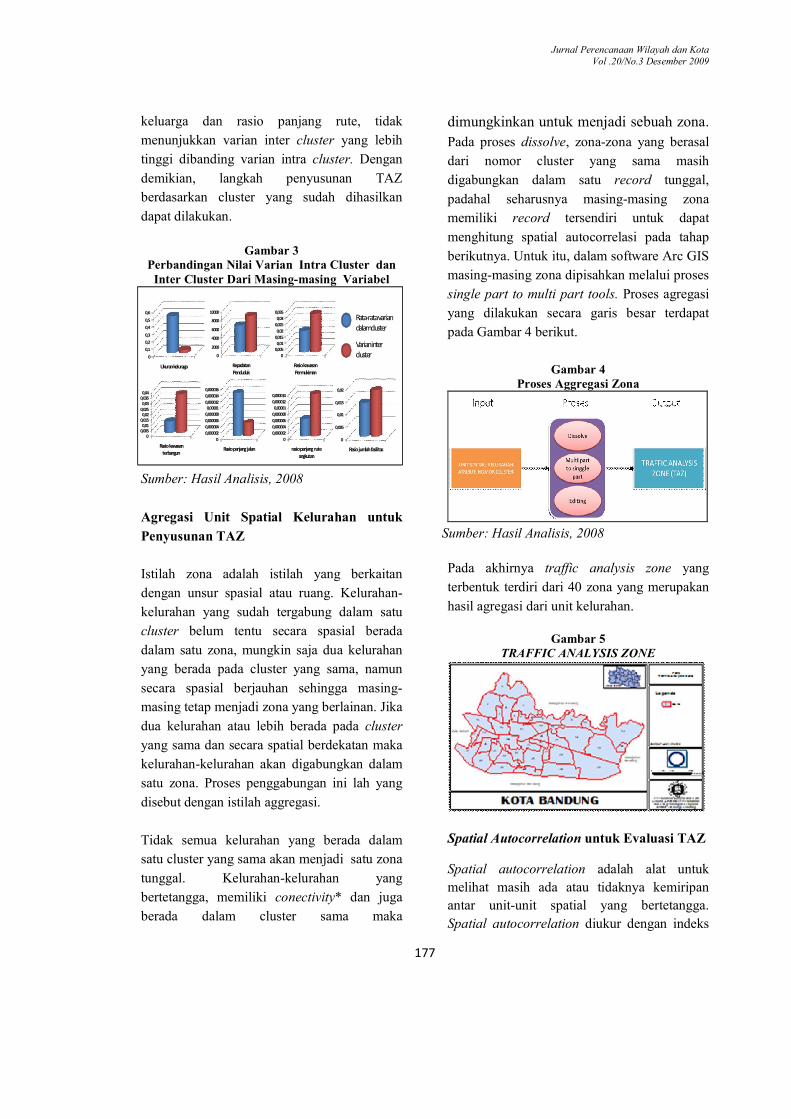
Sumber: Hasil Analisis, 2008 Selain memiliki homogenitas yang tinggi
dalam masing-masing cluster, sebaliknya antar
satu cluster dengan cluster yang lain juga
memperlihatkan heterogenitas yang tinggi.
Dari ketujuh variabel analisis, lima variabel
menunjukkan tingkat varian intercluster yang
lebih tinggi dibanding rata-rata varian
intracluster. Dua variabel lain yaitu ukuran
Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
177
keluarga dan rasio panjang rute, tidak
menunjukkan varian inter cluster yang lebih
tinggi dibanding varian intra cluster. Dengan
demikian, langkah penyusunan TAZ
berdasarkan cluster yang sudah dihasilkan
dapat dilakukan.
Gambar 3
Perbandingan Nilai Varian Intra Cluster dan Inter Cluster Dari Masing-masing Variabel
Rata-rata variandalamcluster
Varian inter cluster0
0,1
0,2
0,3
0,4
0,5
0,6
Ukuran keluraga
0
2000
4000
6000
8000
10000
Kepadatan Penduduk
0
0,0050,01
0,015
0,02
0,025
0,03
0,035
Rasio kawasan Permukiman
00,0050,01
0,0150,02
0,0250,03
0,0350,04
Rasio kawasan terbangun
0
0,000002
0,000004
0,000006
0,000008
0,000010,000012
0,000014
0,000016
Rasio panjang jalan
0
0,000002
0,000004
0,000006
0,000008
0,00001
0,000012
0,000014
rasio panjang rute angkutan
0
0,005
0,01
0,015
0,02
Rasio jumlah fasilitas
Sumber: Hasil Analisis, 2008
Agregasi Unit Spatial Kelurahan untuk
Penyusunan TAZ
Istilah zona adalah istilah yang berkaitan
dengan unsur spasial atau ruang. Kelurahan-
kelurahan yang sudah tergabung dalam satu
cluster belum tentu secara spasial berada
dalam satu zona, mungkin saja dua kelurahan
yang berada pada cluster yang sama, namun
secara spasial berjauhan sehingga masing-
masing tetap menjadi zona yang berlainan. Jika
dua kelurahan atau lebih berada pada cluster
yang sama dan secara spatial berdekatan maka
kelurahan-kelurahan akan digabungkan dalam
satu zona. Proses penggabungan ini lah yang
disebut dengan istilah aggregasi.
Tidak semua kelurahan yang berada dalam
satu cluster yang sama akan menjadi satu zona
tunggal. Kelurahan-kelurahan yang
bertetangga, memiliki conectivity* dan juga
berada dalam cluster sama maka
dimungkinkan untuk menjadi sebuah zona.
Pada proses dissolve, zona-zona yang berasal
dari nomor cluster yang sama masih
digabungkan dalam satu record tunggal,
padahal seharusnya masing-masing zona
memiliki record tersendiri untuk dapat
menghitung spatial autocorrelasi pada tahap
berikutnya. Untuk itu, dalam software Arc GIS
masing-masing zona dipisahkan melalui proses
single part to multi part tools. Proses agregasi
yang dilakukan secara garis besar terdapat
pada Gambar 4 berikut.
Gambar 4 Proses Aggregasi Zona
Sumber: Hasil Analisis, 2008
Pada akhirnya traffic analysis zone yang
terbentuk terdiri dari 40 zona yang merupakan
hasil agregasi dari unit kelurahan.
Gambar 5
TRAFFIC ANALYSIS ZONE
Spatial Autocorrelation untuk Evaluasi TAZ
Spatial autocorrelation adalah alat untuk
melihat masih ada atau tidaknya kemiripan
antar unit-unit spatial yang bertetangga.
Spatial autocorrelation diukur dengan indeks
Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
178
moran yaitu antara negatif 1 sampai dengan
positif 1. Nilai indeks Moran semakin
mendekati negatif 1 menyatakan bahwa
negative spatial autocorrelation (dispers)
terjadi, atau pola dispers yang mudah dipahami
adalah pola papan catur dimana unit yang
bernilai tinggi dikelilingi oleh tetangga yang
bernilai rendah dan sebaliknya. Indeks Moran
mendekati nilai harapan (expected value) yang
biasanya sangat dekat dengan nila 0 (nol)
menyatakan tidak terjadi spatial
autocorrelation atau pola ini disebut juga
dengan random. Indeks Moran mendekati 1 menyatakan positive autocorrelation terjadi
(cluster). Pola cluster terjadi ketika unit yang
bernilai tinggi dikelilingi oleh tetangga yang
benilai tinggi dan sebaliknya tetangga yang
bernilai rendah dikelilingi tetangga yang
bernilai rendah.
Dengan berubahnya jumlah unit spatial dari
sebelum dan sesudah dilakukan penzonaan
maka terjadi perubahan nilai indeks harapan
(expected index). Oleh karena itu, untuk
menyatakan bahwa telah terjadi perubahan
pola spasial yang mengarah ke pola random,
tidak relevan jika dengan melihat pada
penurunan nilai indeks moran. Dengan
demikian, yang harus dilihat adalah perubahan
jarak dari indeks moran terhadap indeks
harapan sebelum dan sesudah penzonaan. Dari
hasil perhitungan maka perubahan jarak dari
indeks moran terhadap indeks harapan sebelum
dan sesudah penzonaan dapat dilihat pada
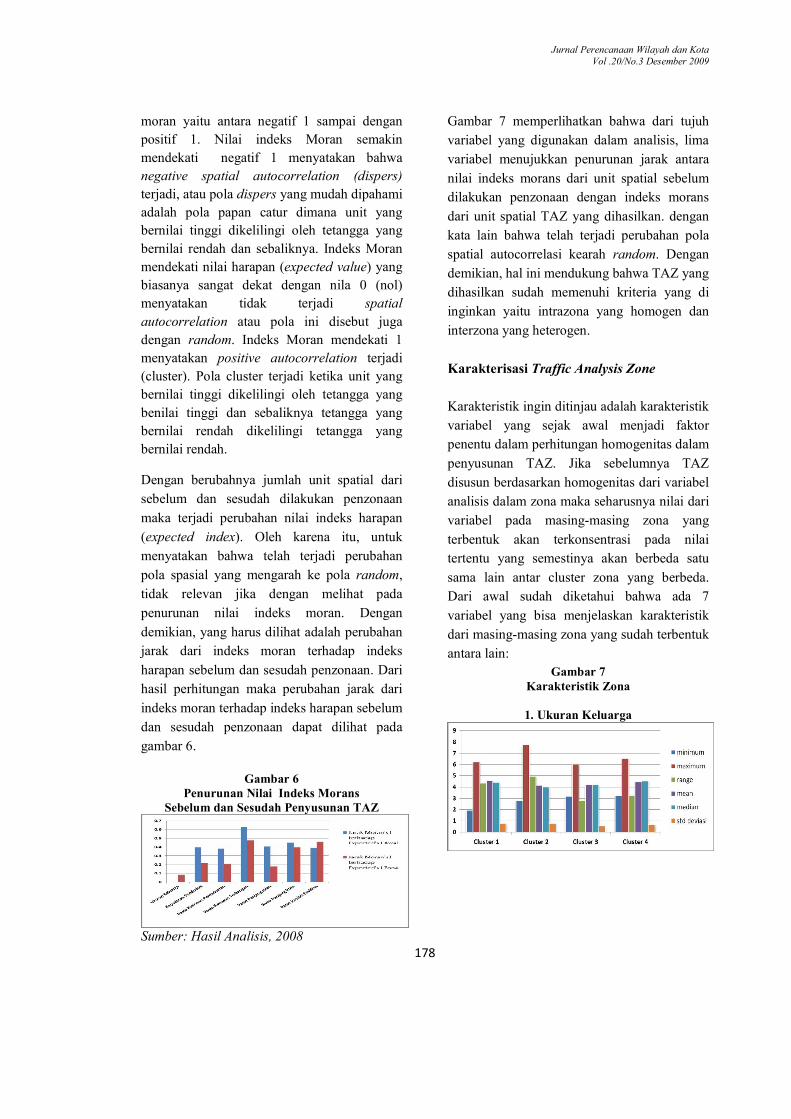
gambar 6.
Gambar 6
Penurunan Nilai Indeks Morans Sebelum dan Sesudah Penyusunan TAZ
Sumber: Hasil Analisis, 2008
Gambar 7 memperlihatkan bahwa dari tujuh
variabel yang digunakan dalam analisis, lima
variabel menujukkan penurunan jarak antara
nilai indeks morans dari unit spatial sebelum
dilakukan penzonaan dengan indeks morans
dari unit spatial TAZ yang dihasilkan. dengan
kata lain bahwa telah terjadi perubahan pola
spatial autocorrelasi kearah random. Dengan
demikian, hal ini mendukung bahwa TAZ yang
dihasilkan sudah memenuhi kriteria yang di
inginkan yaitu intrazona yang homogen dan
interzona yang heterogen.
Karakterisasi Traffic Analysis Zone
Karakteristik ingin ditinjau adalah karakteristik
variabel yang sejak awal menjadi faktor
penentu dalam perhitungan homogenitas dalam
penyusunan TAZ. Jika sebelumnya TAZ
disusun berdasarkan homogenitas dari variabel
analisis dalam zona maka seharusnya nilai dari
variabel pada masing-masing zona yang
terbentuk akan terkonsentrasi pada nilai
tertentu yang semestinya akan berbeda satu
sama lain antar cluster zona yang berbeda.
Dari awal sudah diketahui bahwa ada 7
variabel yang bisa menjelaskan karakteristik
dari masing-masing zona yang sudah terbentuk
antara lain:
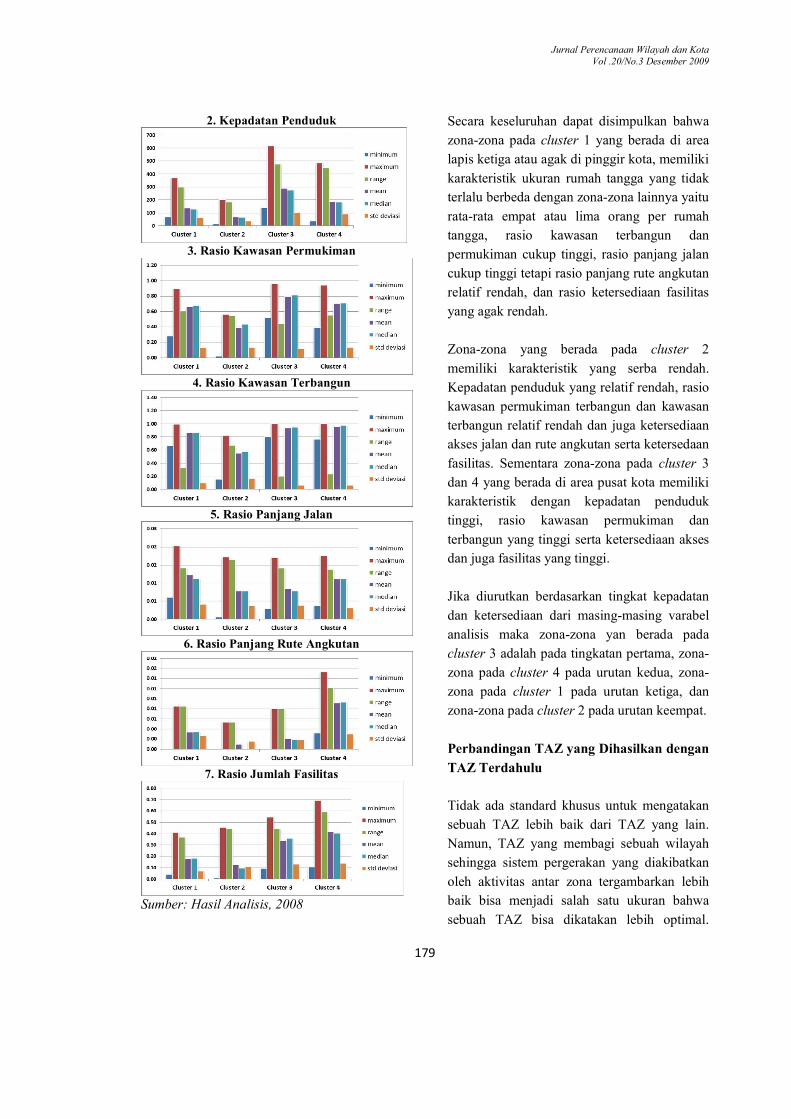
Gambar 7 Karakteristik Zona
1. Ukuran Keluarga
Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
179
2. Kepadatan Penduduk
3. Rasio Kawasan Permukiman
4. Rasio Kawasan Terbangun
5. Rasio Panjang Jalan
6. Rasio Panjang Rute Angkutan
7. Rasio Jumlah Fasilitas
Sumber: Hasil Analisis, 2008
Secara keseluruhan dapat disimpulkan bahwa
zona-zona pada cluster 1 yang berada di area
lapis ketiga atau agak di pinggir kota, memiliki
karakteristik ukuran rumah tangga yang tidak
terlalu berbeda dengan zona-zona lainnya yaitu
rata-rata empat atau lima orang per rumah
tangga, rasio kawasan terbangun dan
permukiman cukup tinggi, rasio panjang jalan
cukup tinggi tetapi rasio panjang rute angkutan
relatif rendah, dan rasio ketersediaan fasilitas
yang agak rendah.
Zona-zona yang berada pada cluster 2
memiliki karakteristik yang serba rendah.
Kepadatan penduduk yang relatif rendah, rasio
kawasan permukiman terbangun dan kawasan
terbangun relatif rendah dan juga ketersediaan
akses jalan dan rute angkutan serta ketersedaan
fasilitas. Sementara zona-zona pada cluster 3
dan 4 yang berada di area pusat kota memiliki
karakteristik dengan kepadatan penduduk
tinggi, rasio kawasan permukiman dan
terbangun yang tinggi serta ketersediaan akses
dan juga fasilitas yang tinggi.
Jika diurutkan berdasarkan tingkat kepadatan
dan ketersediaan dari masing-masing varabel
analisis maka zona-zona yan berada pada
cluster 3 adalah pada tingkatan pertama, zona-
zona pada cluster 4 pada urutan kedua, zona-
zona pada cluster 1 pada urutan ketiga, dan
zona-zona pada cluster 2 pada urutan keempat.
Perbandingan TAZ yang Dihasilkan dengan
TAZ Terdahulu
Tidak ada standard khusus untuk mengatakan
sebuah TAZ lebih baik dari TAZ yang lain.
Namun, TAZ yang membagi sebuah wilayah
sehingga sistem pergerakan yang diakibatkan
oleh aktivitas antar zona tergambarkan lebih
baik bisa menjadi salah satu ukuran bahwa
sebuah TAZ bisa dikatakan lebih optimal.
Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
180
Untuk bisa menggambarkan karakteristik
pergerakan yang diakibatkan oleh sistem
aktivitas antar zona dengan baik, zona yang
homogen bisa menjadi ukuran. Jika zona-zona
yang dibentuk memiliki karakteristik yang
homogen maka karakteristik pergerakan antar
kegiatan akan lebih mudah diidentifikasi
sehingga solusi untuk penyelesaiannyapun
lebih mudah untuk dilakukan.
Jika dibandingkan dengan TAZ terdahulu yang
berdasarkan batas kelurahan, TAZ yang
dihasilkan pada studi ini diharapkan lebih
mampu menggambarkan pola dan karakteristik
pergerakan antar zona karena TAZ yang
dihasilkan telah disusun berdasarkan
kesamaan atau homogenitas karakteristik
sosial, ekonomi dan guna lahan kawasan. Dari
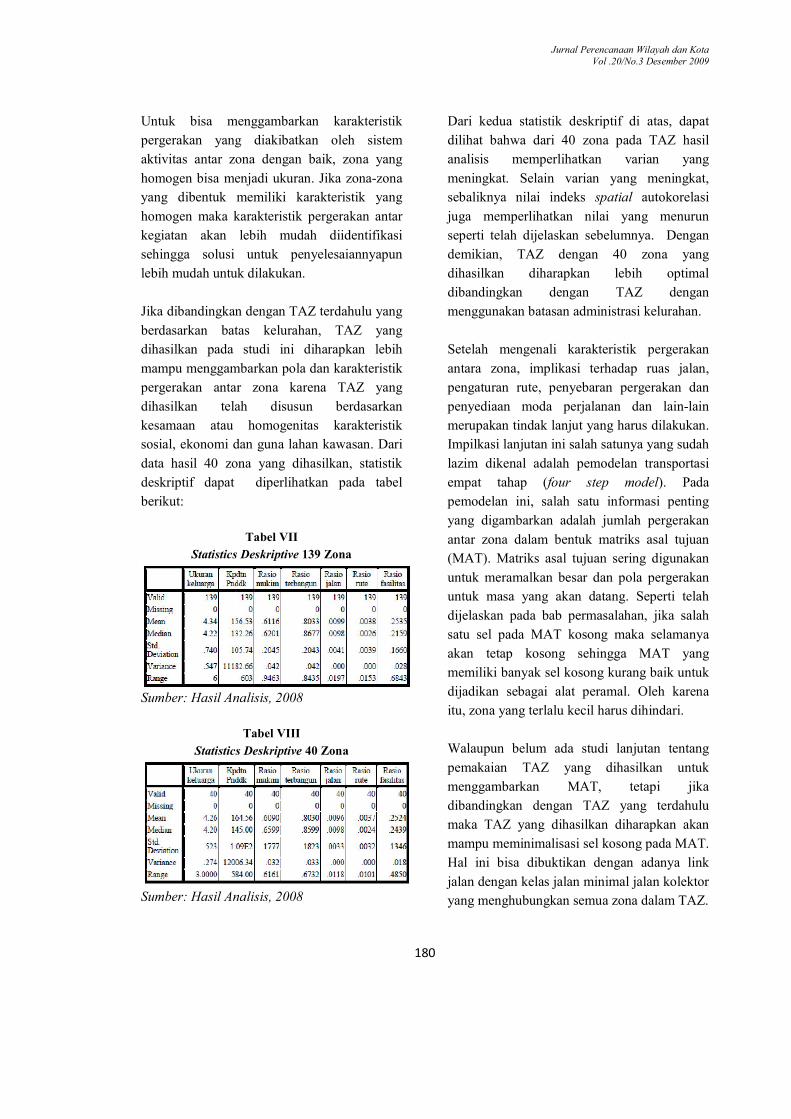
data hasil 40 zona yang dihasilkan, statistik
deskriptif dapat diperlihatkan pada tabel
berikut:
Tabel VII
Statistics Deskriptive 139 Zona
Sumber: Hasil Analisis, 2008
Tabel VIII
Statistics Deskriptive 40 Zona
Sumber: Hasil Analisis, 2008
Dari kedua statistik deskriptif di atas, dapat
dilihat bahwa dari 40 zona pada TAZ hasil
analisis memperlihatkan varian yang
meningkat. Selain varian yang meningkat,
sebaliknya nilai indeks spatial autokorelasi
juga memperlihatkan nilai yang menurun
seperti telah dijelaskan sebelumnya. Dengan
demikian, TAZ dengan 40 zona yang
dihasilkan diharapkan lebih optimal
dibandingkan dengan TAZ dengan
menggunakan batasan administrasi kelurahan.
Setelah mengenali karakteristik pergerakan
antara zona, implikasi terhadap ruas jalan,
pengaturan rute, penyebaran pergerakan dan
penyediaan moda perjalanan dan lain-lain
merupakan tindak lanjut yang harus dilakukan.
Impilkasi lanjutan ini salah satunya yang sudah
lazim dikenal adalah pemodelan transportasi
empat tahap (four step model). Pada
pemodelan ini, salah satu informasi penting
yang digambarkan adalah jumlah pergerakan
antar zona dalam bentuk matriks asal tujuan
(MAT). Matriks asal tujuan sering digunakan
untuk meramalkan besar dan pola pergerakan
untuk masa yang akan datang. Seperti telah
dijelaskan pada bab permasalahan, jika salah
satu sel pada MAT kosong maka selamanya
akan tetap kosong sehingga MAT yang
memiliki banyak sel kosong kurang baik untuk
dijadikan sebagai alat peramal. Oleh karena
itu, zona yang terlalu kecil harus dihindari.
Walaupun belum ada studi lanjutan tentang
pemakaian TAZ yang dihasilkan untuk
menggambarkan MAT, tetapi jika
dibandingkan dengan TAZ yang terdahulu
maka TAZ yang dihasilkan diharapkan akan
mampu meminimalisasi sel kosong pada MAT.
Hal ini bisa dibuktikan dengan adanya link
jalan dengan kelas jalan minimal jalan kolektor
yang menghubungkan semua zona dalam TAZ.

Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
181
Dengan adanya link jalan yang
menghubungkan seluruh zona dalam TAZ
yang dihasilkan maka aksesibiltas antar zona
akan lebih baik sehingga interaksi antar
keseluruhan zona terjadi. Dengan demikian,
jika interaksi antar keseluruhan zona terjadi
maka tidak akan ada sel yang kosong pada
MAT sehingga MAT yang dibuat berdasarkan
zona ini bisa lebih baik untuk meramalkan
besar dan pola pergerakan di kota bandung
untuk masa depan.
IV. PENUTUP
Untuk membangun sebuah TAZ dengan
prinsip memaksimalkan homogenitas kawasan
maka diperlukan variabel-variabel yang
menggambarkan karakteristik dari wilayah
yang bisa mempengaruhi pola pergerakan dari
masyarakat seperti struktur sosial ekonomi
masyarakat dan fasilitas-fasilitas yang
membangkitkan dan menarik pergerakan dari
bagian-bagian wilayah tersebut.
Dalam membangun sebuah TAZ dengan
memanfaatkan metoda aggregasi seperti yang
dilakukan dalam studi ini, data berbasis
GIS mutlak diperlukan karena data
berbasis GIS memiliki kelebihan dalam
mengasosiasikan data spatial dengan data
atribut. Kerangka homogenitas kawasan
yang disusun dalam studi ini membagi unit
kelurahan Kota Bandung kedalam empat
cluster.
Masing-masing cluster diasumsikan sudah
memiliki tingkat homogenitas yang tinggi
dalam satu cluster dan memiliki tingkat
heterogenitas yang tinggi antar cluster. Hal
ini telah dibuktikan dengan nilai varian
dalam cluster yang rendah dan varian
intercluster yang tinggi.
Dengan mempertimbangkan aspek
kedekatan dan conectivity unit kelurahan,
metoda aggregasi yang dilakukan telah
merangkai 139 unit kelurahan Kota
Bandung menjadi 40 zona berdasarkan
kerangka homogenitas yang sudah disusun
sebelumya. Masing-masing zona sudah
mencirikan homogenitas di dalamnya
sehingga antara satu zona cukup berbeda
dengan zona lain di sekitarnya. Ini
dibuktikan dengan indeks spatial
autocorrelation moran’s I yang semakin
mendekati nilai indeks harpan (expected
value) yang menyatakan bahwa TAZ yang
terbentuk random. Analisis data spatial
sangat diperlukan dalam studi ini.dengan
memanfaatkan indeks koefisien Morans’s I
terbukti sangat membantu, karena unsur-
unsur perkotaan harus dikenali dalam
aspek spatial atau keruangan.
Dari 40 zona yang terbentuk telah dikenali
bahwa zona-zona yang berada di wilayah
pinggiran merupakan zona dengan
kepadatan lebih rendah dibanding zona
yang berada di pusat dan memiliki
ketersediaan fasilitas yang lebih sedikit.
Jika zona-zona dikategorikan berdasarkan
nilai tinggi rendahnya varibel penyusun
TAZ yang sudah di kemukakan diawal
maka zona-zona yang berada di pusat kota
berada pada kategori satu, zona-zona pada
lapis dua pada kategori dua, zona-zona
pada lapis empat atau pinggiran pada
kategori tiga, dan zona-zona pada lapis tiga
pada kategori empat (TAZ dibagi kedalam
empat lapis dari pusat kota sebagai lapis
satu sampai ke pinggiran sebagai lapis
empat).

Jurnal Perencanaan Wilayah dan Kota Vol .20/No.3 Desember 2009
182
TAZ yang dihasilkan sudah dibandingkan
dengan TAZ terdahulu. Jika zona-zona
dalam TAZ yang disusun pada studi ini
sudah homogen dan memperlihatkan
perbedaan karakter dengan zona-zona di
sekitarnya maka dibandingkan dengan
TAZ terdahulu, TAZ yang dihasilkan lebih
efisien untuk digunakan dalam beberapa
analisis transportasi lanjutan. Selain itu,
adanya link jalan dengan kelas minimal
jalan kolektor yang menghubungkan
keseluruhan zona dalam TAZ maka
diharapkan pemakaian TAZ ini dalam
studi lanjutan seperti pembentukan matriks
asal tujuan (MAT) dapat lebih efisien
karena mampu megurangi sel kosong
dalam MAT.
DAFTAR PUSTAKA Anselin, Luc, 1997. Introduction to the Special
Issue on Spatial Econometrics. International Regional Science Review, Vol. 20, No. 1-2, 1-7 (1997). SAGE Publications.
Anselin, Luc, 2002. Introduction to Spatial Data Analysis. REAL, University of Illinois, Urbana-Champaign.
Anselin, Luc, 2004. Introduction to Spatial Data Analysis. ICPSR-CSISS, University of Illinois, Urbana-Champaign.
Bao, S. 1999. Literature Review of Spatial Statistics and Models. Cina Data Center, Univercity of Michigan.
Biro Pusat Statistik. 2005. Kota Bandung dalam Angka 2005.
Biro Pusat Statistik. 2005. Potensi Desa 2005. Black, John. 1981. Urban Transport Planning:
Theory and Practice. London: Crown Helm. Dillon, Wiliam R. & Matthew Goldstein.1984.
Multivariative Analysis. JohnWiley & Sons. Ding, Chengri. 1994. Impact Analysis Of Spatial
Data Aggregation On Transportation Forecasted Demand: A Gis Approach. University of Illinois at Urbana-Champaign.URISA (1994), p362-375.
Ding, Y., and Fotheringham, S. A., 1991, The Integration of Spatial Data Analysis and GIS: The Development of the STATCAS Module for ARC/INFO (Buffalo, NY:
National Center for Geographic Information and Analysis).
Edwards, John D. 1992. Transportation Planning Handbook. New Jersey: Prentice Hall.
Griffith, D. A., 1987. Spatial Autocorrelation: APrimer, State University of New York at Buffalo, ressource Publication in Geography.
Healey, J. (1996). Statistics. A Tool For Social Research. Wadsworth Publishing Company. California.
John, Robert. 1988. Use of Cluster Analysis in Social Service Planning: A Case Study of Laguna Pueblo Elders. Journal of Applied Gerontology 1988; 7; 21, DOI: 10.1177/073346488800700103. SAGE Publications.
Kachigan, Sam Kash.1986. Statistical Analysis. New York: Radius Press.
Meyer and Miller, 2001. Urban Transportation Plannig. Second edition, Mc Graw Hill.
Tamin, Ofyar Z, 2000. Perencanaan dan Permodelan Transportasi. Bandung: Penerbit ITB.
You, Jinsoo, 1996. Iplementation of Integration Land Use and Transportation Model with Geographic Information System, Urbana, Illinois.