panduan lengkap analisis statistika dengan aplikasi spss
TRANSCRIPT

PANDUAN LENGKAP
ANALISIS STATISTIKA
MENGGUNAKAN SOFTWARE SPSS
(Statistical Package for Social Science)
By Aldy Forester
UJI ASUMSI KLASIK, UJI VALIDITAS DAN RELIABILITAS,
ANALISIS REGRESI LINEAR BERGANDA & TABEL STATISTIK
Disadur dari Website
http://www.spssindonesia.com/ , http://www.konsistensi.com
dan http://www.portal-statistik.com/

Assalamu alaikum warrahmatullahi wabarakatuh
Permohonan maaf kepada pemilik/admin web
http://www.spssindonesia.com/, http://www.portal-statistik.com/, dan
http://www.konsistensi.com karena tanpa permohonan ijin sebelumnya,
saya telah menyadur beberapa artikel di dalamnya
dan dijadikan Panduan sederhana ini,
.
Harapan saya, semoga artikel yang sudah ditulis dalam web tersebut
dapat lebih bermanfaat dengan adanya Panduan sederhana ini.
Wassalam.
(Aldy Forester)

UJI ASUMSI KLASIK
Uji asumsi klasik adalah persyaratan statistik yang harus dipenuhi pada analisis regresi linear
berganda yang berbasis ordinary least square (OLS). Jadi analisis regresi yang tidak
berdasarkan OLS tidak memerlukan persyaratan asumsi klasik, misalnya regresi
logistik atau regresi ordinal. Demikian juga tidak semua uji asumsi klasik harus dilakukan pada
analisis regresi linear, misalnya uji multikolinearitas tidak dilakukan pada analisis regresi linear
sederhana dan uji autokorelasi tidak perlu diterapkan pada data cross sectional.
Uji asumsi klasik juga tidak perlu dilakukan untuk analisis regresi linear yang bertujuan untuk
menghitung nilai pada variabel tertentu. Misalnya nilai return saham yang dihitung dengan
market model, atau market adjusted model. Perhitungan nilai return yang diharapkan dapat
dilakukan dengan persamaan regresi, tetapi tidak perlu diuji asumsi klasik.
Uji asumsi klasik yang sering digunakan yaitu uji multikolinearitas, uji heteroskedastisitas, uji
normalitas, uji autokorelasi dan uji linearitas. Tidak ada ketentuan yang pasti tentang urutan uji
mana dulu yang harus dipenuhi. Analisis dapat dilakukan tergantung pada data yang ada.
Sebagai contoh, dilakukan analisis terhadap semua uji asumsi klasik, lalu dilihat mana yang
tidak memenuhi persyaratan. Kemudian dilakukan perbaikan pada uji tersebut, dan setelah
memenuhi persyaratan, dilakukan pengujian pada uji yang lain.
1. Uji Normalitas
Uji normalitas adalah untuk melihat apakah nilai residual terdistribusi normal atau tidak. Model
regresi yang baik adalah memiliki nilai residual yang terdistribusi normal. Jadi uji normalitas
bukan dilakukan pada masing-masing variabel tetapi pada nilai residualnya. Sering terjadi
kesalahan yang jamak yaitu bahwa uji normalitas dilakukan pada masing-masing variabel. Hal
ini tidak dilarang tetapi model regresi memerlukan normalitas pada nilai residualnya bukan pada
masing-masing variabel penelitian.
Pengertian normal secara sederhana dapat dianalogikan dengan sebuah kelas. Dalam kelas
siswa yang bodoh sekali dan pandai sekali jumlahnya hanya sedikit dan sebagian besar berada
pada kategori sedang atau rata-rata. Jika kelas tersebut bodoh semua maka tidak normal, atau
sekolah luar biasa. Dan sebaliknya jika suatu kelas banyak yang pandai maka kelas tersebut
tidak normal atau merupakan kelas unggulan. Pengamatan data yang normal akan memberikan
nilai ekstrim rendah dan ekstrim tinggi yang sedikit dan kebanyakan mengumpul di tengah.
Demikian juga nilai rata-rata, modus dan median relatif dekat.
Uji normalitas dapat dilakukan dengan uji histogram, uji normal P Plot, uji Chi Square,
Skewness dan Kurtosis atau uji Kolmogorov Smirnov. Tidak ada metode yang paling baik atau
paling tepat. Tipsnya adalah bahwa pengujian dengan metode grafik sering menimbulkan
perbedaan persepsi di antara beberapa pengamat, sehingga penggunaan uji normalitas dengan
uji statistik bebas dari keragu-raguan, meskipun tidak ada jaminan bahwa pengujian dengan uji
statistik lebih baik dari pada pengujian dengan metode grafik.

Jika residual tidak normal tetapi dekat dengan nilai kritis (misalnya signifikansi Kolmogorov
Smirnov sebesar 0,049) maka dapat dicoba dengan metode lain yang mungkin memberikan
justifikasi normal. Tetapi jika jauh dari nilai normal, maka dapat dilakukan beberapa langkah
yaitu: melakukan transformasi data, melakukan trimming data outliers atau menambah data
observasi. Transformasi dapat dilakukan ke dalam bentuk Logaritma natural, akar kuadrat,
inverse, atau bentuk yang lain tergantung dari bentuk kurva normalnya, apakah condong ke kiri,
ke kanan, mengumpul di tengah atau menyebar ke samping kanan dan kiri.
2. Uji Multikolinearitas
Uji multikolinearitas adalah untuk melihat ada atau tidaknya korelasi yang tinggi antara variabel-
variabel bebas dalam suatu model regresi linear berganda. Jika ada korelasi yang tinggi di
antara variabel-variabel bebasnya, maka hubungan antara variabel bebas terhadap variabel
terikatnya menjadi terganggu. Sebagai ilustrasi, adalah model regresi dengan variabel
bebasnya motivasi, kepemimpinan dan kepuasan kerja dengan variabel terikatnya adalah
kinerja. Logika sederhananya adalah bahwa model tersebut untuk mencari pengaruh antara
motivasi, kepemimpinan dan kepuasan kerja terhadap kinerja. Jadi tidak boleh ada korelasi
yang tinggi antara motivasi dengan kepemimpinan, motivasi dengan kepuasan kerja atau antara
kepemimpinan dengan kepuasan kerja.
Alat statistik yang sering dipergunakan untuk menguji gangguan multikolinearitas adalah
dengan variance inflation factor (VIF), korelasi pearson antara variabel-variabel bebas, atau
dengan melihat eigenvalues dan condition index (CI).
Beberapa alternatif cara untuk mengatasi masalah multikolinearitas adalah sebagai berikut:
1. Mengganti atau mengeluarkan variabel yang mempunyai korelasi yang tinggi.
2. Menambah jumlah observasi.
3. Mentransformasikan data ke dalam bentuk lain, misalnya logaritma natural, akar kuadrat
atau bentuk first difference delta.
3. Uji Heteroskedastisitas
Uji heteroskedastisitas adalah untuk melihat apakah terdapat ketidaksamaan varians
dari residual satu ke pengamatan ke pengamatan yang lain. Model regresi yang memenuhi
persyaratan adalah di mana terdapat kesamaan varians dari residual satu pengamatan ke
pengamatan yang lain tetap atau disebut homoskedastisitas.
Deteksi heteroskedastisitas dapat dilakukan dengan metode scatter plot dengan
memplotkan nilai ZPRED (nilai prediksi) dengan SRESID (nilai residualnya). Model yang baik
didapatkan jika tidak terdapat pola tertentu pada grafik, seperti mengumpul di tengah,
menyempit kemudian melebar atau sebaliknya melebar kemudian menyempit. Uji statistik yang
dapat digunakan adalah uji Glejser, uji Park atau uji White.
Beberapa alternatif solusi jika model menyalahi asumsi heteroskedastisitas adalah dengan
mentransformasikan ke dalam bentuk logaritma, yang hanya dapat dilakukan jika semua data

bernilai positif. Atau dapat juga dilakukan dengan membagi semua variabel dengan variabel
yang mengalami gangguan heteroskedastisitas.
4. Uji Autokorelasi
Uji autokorelasi adalah untuk melihat apakah terjadi korelasi antara suatu periode t
dengan periode sebelumnya (t -1). Secara sederhana adalah bahwa analisis regresi adalah
untuk melihat pengaruh antara variabel bebas terhadap variabel terikat, jadi tidak boleh ada
korelasi antara observasi dengan data observasi sebelumnya. Sebagai contoh adalah pengaruh
antara tingkat inflasi bulanan terhadap nilai tukar rupiah terhadap dollar. Data tingkat inflasi
pada bulan tertentu, katakanlah bulan Februari, akan dipengaruhi oleh tingkat inflasi bulan
Januari. Berarti terdapat gangguan autokorelasi pada model tersebut. Contoh lain, pengeluaran
rutin dalam suatu rumah tangga. Ketika pada bulan Januari suatu keluarga mengeluarkan
belanja bulanan yang relatif tinggi, maka tanpa ada pengaruh dari apapun, pengeluaran pada
bulan Februari akan rendah.
Uji autokorelasi hanya dilakukan pada data time series (runtut waktu) dan tidak perlu
dilakukan pada data cross section seperti pada kuesioner di mana pengukuran semua variabel
dilakukan secara serempak pada saat yang bersamaan. Model regresi pada penelitian di Bursa
Efek Indonesia di mana periodenya lebih dari satu tahun biasanya memerlukan uji autokorelasi.
Beberapa uji statistik yang sering dipergunakan adalah uji Durbin-Watson, uji dengan
Run Test dan jika data observasi di atas 100 data sebaiknya menggunakan uji Lagrange
Multiplier. Beberapa cara untuk menanggulangi masalah autokorelasi adalah dengan
mentransformasikan data atau bisa juga dengan mengubah model regresi ke dalam bentuk
persamaan beda umum (generalized difference equation). Selain itu juga dapat dilakukan
dengan memasukkan variabel lag dari variabel terikatnya menjadi salah satu variabel bebas,
sehingga data observasi menjadi berkurang 1.
5. Uji Linearitas
Uji linearitas dipergunakan untuk melihat apakah model yang dibangun mempunyai
hubungan linear atau tidak. Uji ini jarang digunakan pada berbagai penelitian, karena biasanya
model dibentuk berdasarkan telaah teoretis bahwa hubungan antara variabel bebas dengan
variabel terikatnya adalah linear. Hubungan antar variabel yang secara teori bukan merupakan
hubungan linear sebenarnya sudah tidak dapat dianalisis dengan regresi linear, misalnya
masalah elastisitas.
Jika ada hubungan antara dua variabel yang belum diketahui apakah linear atau tidak,
uji linearitas tidak dapat digunakan untuk memberikan adjustment bahwa hubungan tersebut
bersifat linear atau tidak. Uji linearitas digunakan untuk mengkonfirmasikan apakah sifat linear
antara dua variabel yang diidentifikasikan secara teori sesuai atau tidak dengan hasil observasi
yang ada. Uji linearitas dapat menggunakan uji Durbin-Watson, Ramsey Test atau uji Lagrange
Multiplier
Sumber : http://www.konsultanstatistik.com/2009/03/uji-asumsi-klasik.html
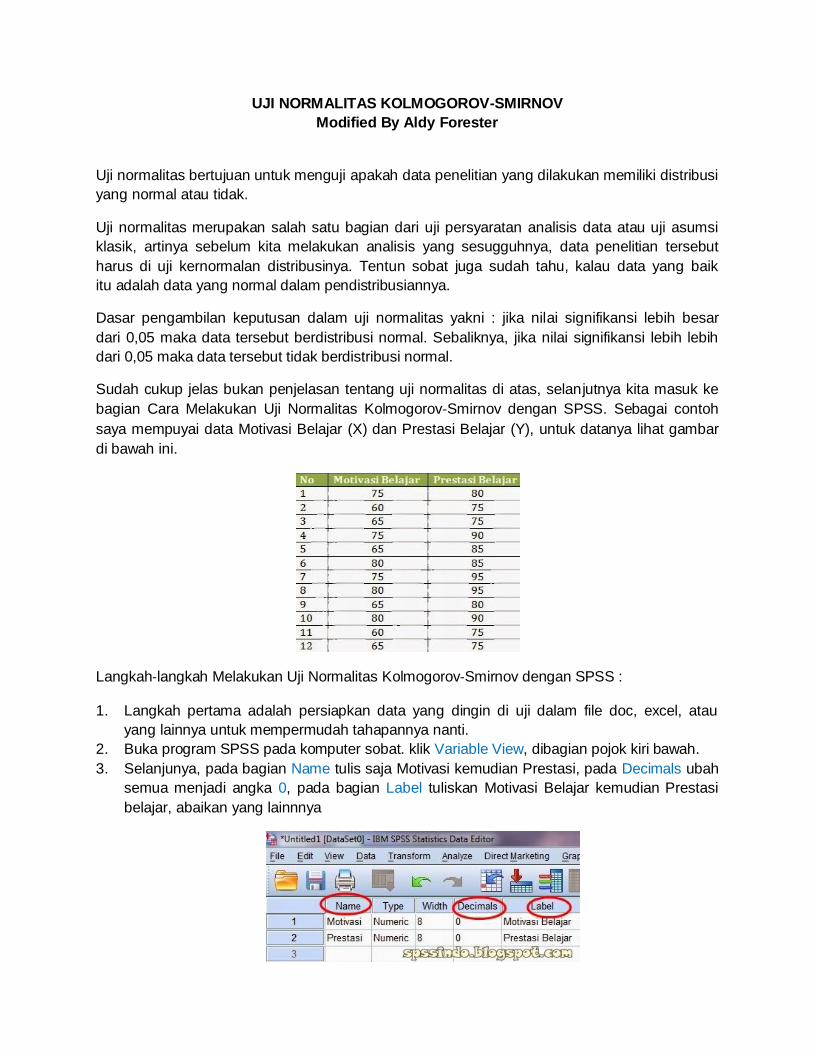
UJI NORMALITAS KOLMOGOROV-SMIRNOV
Modified By Aldy Forester
Uji normalitas bertujuan untuk menguji apakah data penelitian yang dilakukan memiliki distribusi
yang normal atau tidak.
Uji normalitas merupakan salah satu bagian dari uji persyaratan analisis data atau uji asumsi
klasik, artinya sebelum kita melakukan analisis yang sesugguhnya, data penelitian tersebut
harus di uji kernormalan distribusinya. Tentun sobat juga sudah tahu, kalau data yang baik
itu adalah data yang normal dalam pendistribusiannya.
Dasar pengambilan keputusan dalam uji normalitas yakni : jika nilai signifikansi lebih besar
dari 0,05 maka data tersebut berdistribusi normal. Sebaliknya, jika nilai signifikansi lebih lebih
dari 0,05 maka data tersebut tidak berdistribusi normal.
Sudah cukup jelas bukan penjelasan tentang uji normalitas di atas, selanjutnya kita masuk ke
bagian Cara Melakukan Uji Normalitas Kolmogorov‐Smirnov dengan SPSS. Sebagai contoh
saya mempuyai data Motivasi Belajar (X) dan Prestasi Belajar (Y), untuk datanya lihat gambar
di bawah ini.
Langkah‐langkah Melakukan Uji Normalitas Kolmogorov‐Smirnov dengan SPSS :
1. Langkah pertama adalah persiapkan data yang dingin di uji dalam file doc, excel, atau
yang lainnya untuk mempermudah tahapannya nanti.
2. Buka program SPSS pada komputer sobat. klik Variable View, dibagian pojok kiri bawah.
3. Selanjunya, pada bagian Name tulis saja Motivasi kemudian Prestasi, pada Decimals ubah
semua menjadi angka 0, pada bagian Label tuliskan Motivasi Belajar kemudian Prestasi
belajar, abaikan yang lainnnya

4. Setelah itu, klik Data View, dan masukkan data Motivasi Belajar dan Prestasi Belajar yang
sudah dipersiapkan tadi, bisa dengan cara copy‐paste
5. Langkah selanjutnya, kita akan mengubah data tersebut ke dalam bentuk unstandardized
residual, caranya adalah : dari menu SPSS pilih menu Analyze, kemudian klik Regression,
dan pilih Linear.
6. Muncul kotak dialog dengan nama Linear Regression, selanjutnya masukkan variabel
Prestasi Belajar (Y) ke Dependent, masukkan variabel Motivasi Belajar (X) ke kotak
Independent (s), lalu klik Save.

7. Akan mucul lagi kotak dialog dengan nama Linear Regression: Save, pada bagian
Residuals, centang () Unstandardized (abaikan kolom yang lain), Selanjunya klik
Continue, lalu klik OK, maka akan muncul variabel baru dengan nama RES_1, abaikan
saja output yang muncul dari program SPSS.
8. Langkah selanjutnya, pilih menu Analyze, lalu pilih Non‐parametric Test, klik Legaci
Dialog, kemudian pilih submenu 1‐Sample K‐S
9. Muncul kotak dialog lagi dengan nama One‐Sampel Kolmogorov‐Smirnov test,
selanjutnya, masukkan variabel Unstandardized Residuals ke kotak Test Variable List,
pada Test Distribution centang () Normal.

10. Langkah terkahir yakni klik OK untuk mengakhiri perintah, Selanjutnya lihat tampilan
Outputnya, tinggal kita interprestasikan supaya lebih jelas.
Berdasarkan output di atas, diketahui bahwa nilai signifikansi sebesar 0,977 lebih besar dari
0,05, sehingga dapat disimpulkan bahwa data yang kita uji berdistribusi normal.
Sumber : http://www.spssindonesia.com/2014/01/uji-normalitas-kolmogorov-smirnov-spss.html
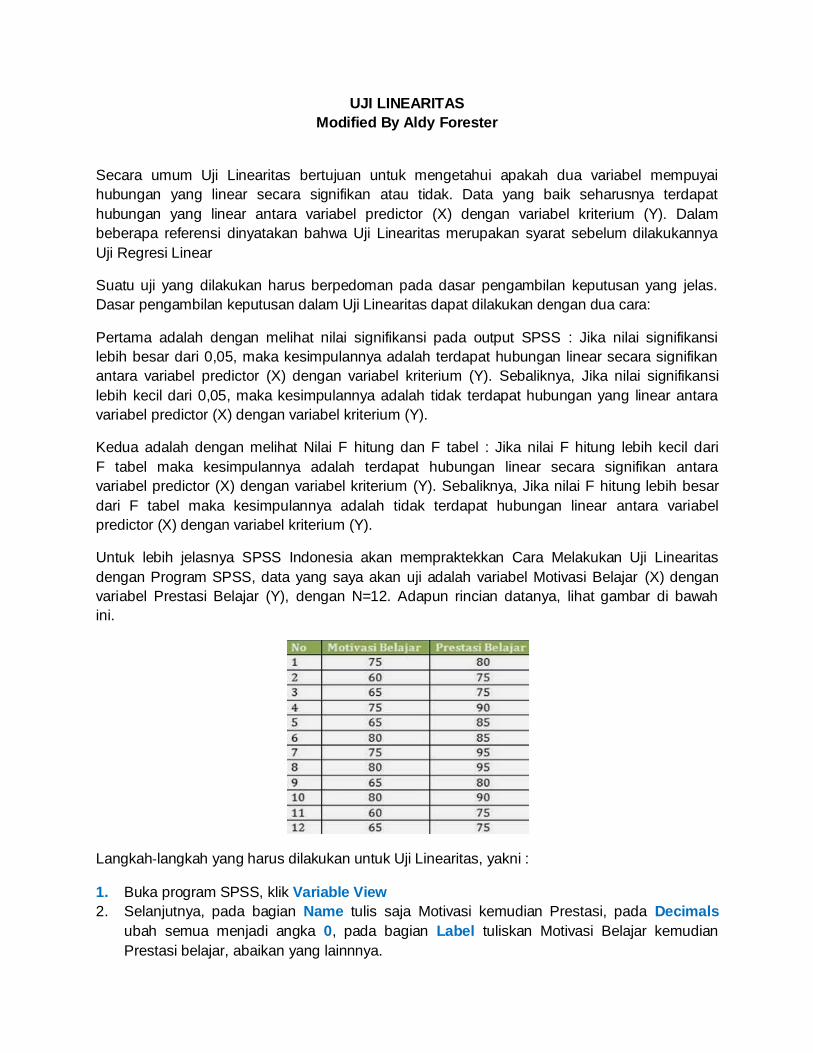
UJI LINEARITAS
Modified By Aldy Forester
Secara umum Uji Linearitas bertujuan untuk mengetahui apakah dua variabel mempuyai
hubungan yang linear secara signifikan atau tidak. Data yang baik seharusnya terdapat
hubungan yang linear antara variabel predictor (X) dengan variabel kriterium (Y). Dalam
beberapa referensi dinyatakan bahwa Uji Linearitas merupakan syarat sebelum dilakukannya
Uji Regresi Linear
Suatu uji yang dilakukan harus berpedoman pada dasar pengambilan keputusan yang jelas.
Dasar pengambilan keputusan dalam Uji Linearitas dapat dilakukan dengan dua cara:
Pertama adalah dengan melihat nilai signifikansi pada output SPSS : Jika nilai signifikansi
lebih besar dari 0,05, maka kesimpulannya adalah terdapat hubungan linear secara signifikan
antara variabel predictor (X) dengan variabel kriterium (Y). Sebaliknya, Jika nilai signifikansi
lebih kecil dari 0,05, maka kesimpulannya adalah tidak terdapat hubungan yang linear antara
variabel predictor (X) dengan variabel kriterium (Y).
Kedua adalah dengan melihat Nilai F hitung dan F tabel : Jika nilai F hitung lebih kecil dari
F tabel maka kesimpulannya adalah terdapat hubungan linear secara signifikan antara
variabel predictor (X) dengan variabel kriterium (Y). Sebaliknya, Jika nilai F hitung lebih besar
dari F tabel maka kesimpulannya adalah tidak terdapat hubungan linear antara variabel
predictor (X) dengan variabel kriterium (Y).
Untuk lebih jelasnya SPSS Indonesia akan mempraktekkan Cara Melakukan Uji Linearitas
dengan Program SPSS, data yang saya akan uji adalah variabel Motivasi Belajar (X) dengan
variabel Prestasi Belajar (Y), dengan N=12. Adapun rincian datanya, lihat gambar di bawah
ini.
Langkah‐langkah yang harus dilakukan untuk Uji Linearitas, yakni :
1. Buka program SPSS, klik Variable View
2. Selanjutnya, pada bagian Name tulis saja Motivasi kemudian Prestasi, pada Decimals
ubah semua menjadi angka 0, pada bagian Label tuliskan Motivasi Belajar kemudian
Prestasi belajar, abaikan yang lainnnya.

3. Setelah itu, klik Data View, dan masukkan data Motivasi Belajar dan Prestasi Belajar yang
sudah dipersiapkan tadi, bisa dengan cara copy‐paste.
4. Berikutnya, dari menu utama SPSS pilih Analyze, lalu klik Compare Means, dan pilih
Means.
5. Muncul kotak dengan nama Means, masukkan variabel Motivasi Belajar (X) ke kotak
Independet List dan variabel Prestasi Belajar (Y) ke kotak Dependet List.

6. Selanjutnya, klik Options, pada Statistik for First Layer, pilih Test of Linearity, kemudian
klik Continue.
7. Langkah terahir adalah klik OK untuk mengakhiri perintah.
Tampilan Output SPSS
Seperti yang sudah saya jelaskan di awal bahwa dasar pengambilan keputusan dalam Uji
Linearitas dapat dilakukan dengan dua cara yakni melihat nilai signifikansi dan nilai F.
Berdasarkan nilai signifikansi : dari output di atas, diperoleh nilai signifikansi = 0,867 lebih
besar dari 0,05, yang artinya terdapat hubungan linear secara signifikan antara variable
Motivasi Belajar (X) dengan variable Prestasi Belajar (Y).

Berdasarkan nilai F : dari output di atas, diperoleh nilai F hitung = 0,145, sedang F tabel kita
cari pada tabel Distribution Tabel Nilai F0,05 (Tabel Distribution Tabel Nilai F 0,05 terlampir),
dengan angka df nya, dari output di atas diketahui df 2.8 (angka yang saya lingkari merah).
Lalu kita cari pada tabel Distribution Tabel Nilai F 0,05, ditemukan nilai F tabel = 4,46. Karena
nilai F hitung lebih kecil dari F tabel maka dapat disimpulkan bahwa terdapat hubungan linear
secara signifikan antara variable Motivasi Belajar (X) dengan variable Prestasi Belajar (Y).
Sumber : http://www.spssindonesia.com/2014/02/uji-linearitas-dengan-program-spss.html

UJI HETEROSKEDASTISITAS
Modified By Aldy Forester
Sebelum saya mulai pada tutorialnya, sobat harus tahu terlebih dahulu tujuan dari Uji
Heteroskedastisitas. Uji ini pada dasarnya bertujuan untuk menguji apakah dalam model
regresi terjadi ketidaksamaan variance dari residual satu pengamatan ke pengamatan yang
lain. Jika variance dari residual satu pengamatan ke pengamatan lain tetap, maka disebut
Homoskedastisitas dan berbeda disebut Heteroskedastisitas. Model regresi yang baik
seharusnya tidak terjadi heteroskedastisitas.
Setiap uji dalam statistik pasti mempuyai dasar pengambilan keputusan yang berguna untuk
menentukan sebuah kesimpulan. Dasar pengambilan keputusan pada Uji Heteroskedastisitas
yakni :
Jika nilai signifikansi lebih besar dari 0,05, kesimpulannya adalah tidak terjadi
heteroskedastisitas.
Jika nilai nilai signifikansi lebih kecil dari 0,05, kesimpulannya adalah terjadi
heteroskedastisitas.
Dalam artikel, Uji Heteroskedastisitas dilakukan dengan Uji Glejser. Maksudnya uji Glejser ini
adalah mengusulkan untuk meregres nilai absolute residual terhadap variabel independen
dengan persamaan regresi : |Ut| =a + BXt + vt
Agar lebih jelas, selanjutnya kita masuk saja kebagian praktek yakni langkah‐langkah
melakukan Uji Heteroskedastisitas dengan Glejser SPSS versi 21. Namun sebelumnya, perlu
saya informasikan bahwa data yang saya uji disini adalah data Motivasi (X1), Minat (X2), dan
Prestasi ﴾Y﴿. Adapun data yang saya maksud dapat dilihat pada gambar dibawah ini.
1. Setelah data yang ingin di uji sudah dipersiapkan, selanjutnya buka program SPSS, lalu
seperti biasa, klik Variable View, Selanjutnya, pada bagian Name tulis saja X1, X2 dan Y,
pada Decimals ubah semua menjadi angka 0, pada bagian Label tuliskan Motivasi, Minat
dan Prestasi, abaikan yang lainnnya.

2. Setelah itu, klik Data View, dan masukkan data Motivasi (X1), Minat (X2) dan Prestasi (Y)
yang sudah dipersiapkan tadi, bisa dengan cara copy‐paste.
3. Langkah selanjunya, saya akan membuat variabel tersebut dalam bentuk unstandardized
residual, caranya : dari menu SPSS pilih Analyze, lalu klik Regression, selanjutnya klik
Linear.
4. Kemudian, muncul kotak dialog dengan nama Linear Regression, maka masukkan
variabel Prestasi (Y) ke Dependent, masukkan variabel Motivasi (X1) dan Minat (X2) ke
Independent (s), laku klik Save.

5. Muncul dialog dengan nama Linear Regression: Save, selanjutnya pada bagian
Residuals, centang () Unstandardized (abaikan kolom yang lain), lalu klik Continue.
6. Lalu klik OK, abaikan saja ada output SPSS yang muncul, lihat di bagian Data View maka
akan muncul variabel baru dengan nama RES_1.

7. Selanjutnya saya akan membuat variabel RES2, caranya :dari menu utama SPSS pilih
Transform, lalu Compute Variable : pada kotak Target Variable isi dengan RES2. Pada
kotak Numeric Expression ketikkan rumus: ABS_RES(RES_1).
8. Kemudian klik OK, abaikan saja ada output SPSS yang muncul, lihat di bagian Data View
maka akan muncul variabel baru dengan nama RES2.
9. Langkah berikutnya, dari menu utama SPSS pilih Analyze, kemudian pilih Regression,
lalu klik Linear.
10. Kemudian muncul kotak dialog dengan nama Linear Regression, lalu keluarkan dulu
variabel Prestasi (Y) yang terdapat pada Dependent dan ganti dengan variabel RES2, lalu
klik Save.

11. Mucul kotak dengan nama Linear Regression: Save, selanjutnya pada bagian Residual,
hilangkan tanda centang () Unstandardized (abaikan kolom yang lain), lalu klik Continue.
12. Langkah yang terakhir adalah klik OK untuk mengakhiri perintah, maka kita sudah bisa
melihat Outputnya, tinggal kita interprestasikan saja.
Interprestasi :
Berdasarkan output di atas diketahui bahwa nilai signifikasi variabel Motivasi (X1) sebesar
0,004 lebih kecil dari 0,05, artinya terjadi heteroskedastisitas pada variabel Motivasi (X1).
Sementara itu, diketahui nilai signifikasi variabel Minat (X2) yakni 0,009 lebih kecil dari 0,05,
antinya terjadi heteroskedastisitas pada variabel Minat (X2).
Sumber : http://www.spssindonesia.com/2014/02/uji-heteroskedastisitas-glejser-spss.html#

UJI MULTIKOLINEARITAS
Modified By Aldy Forester
Uji Multikolonieritas bertujuan untuk menguji apakah model regresi ditemukan adanya korelasi
antar veriabel bebas ﴾independent﴿. Model regresi yang baik seharusnya tidak terjadi korelasi
diantara variabel bebas ﴾tidak terjadi Multikolonieritas﴿. Jika variabel bebas saling berkorelasi,
maka variabel‐variabel ini tidak ortogonal adalah variabel bebas yang nilai korelasi antar
sesame variabel bebas sama dengan nol.
Seperti biasanya, setiap uji statistik yang dilakukan pasti ada dasar pengambilan keputusannya.
Dasar pengambilan keputusan pada Uji Multikolonieritas dapat dilakukan dengan dua cara
yakni :
1. Melihat nilai tolerance :
Jika nilai Tolerance lebih besar dari 0,10 maka artinya tidak terjadi Multikolinieritas
terhadap data yang di uji.
Jika nilai Tolerance lebih kecil dari 0,10 maka artinya Terjadi Multikolinieritas terhadap
data yang di uji.
2. Melihat nilai VIF (Variance Inflation Factor) :
Jika nilai VIF lebih kecil dari 10,00 maka artinya Tidak terjadi Multikolinieritas terhadap
data yang di uji
Jika nilai VIF lebih besar dari 10,00 maka artinya Terjadi Multikolinieritas terhadap data
yang di uji
Selanjutnya kita masuk kebagian Cara Melakukan Uji Multikolonieritas dengan Melihat Nilai
Tolerance dan VIF SPSS adapun rincian data yang akan saya uji adalah Data Motivasi Belajar
(X) dan Prestasi Belajar (Y). Adapun langkah‐langkah pengujiannya simak dibawah ini.
1. Persiapkan data yang akan di uji.
2. Buka program SPSS, klik Variable View, Selanjutnya, pada bagian Name tulis saja X1, X2
dan Y, pada Decimals ubah semua menjadi angka 0, pada bagian Label tuliskan Motivasi,
Minat dan Prestasi, abaikan yang lainnnya.

3. Setelah itu, klik Data View, dan masukkan data Motivasi (X1), Minat (X2) dan Prestasi (Y)
yang sudah dipersiapkan tadi, bisa dengan cara copy‐paste.
4. Dari menu SPSS, Pilih menu Analyze, kemudian sub menu Regression, lalu pilih Linear.
5. Muncul kotak baru dengan nama Linear Regression, masukkan variabel Motivasi (X1) dan
Minat (X2) pada kotak Independent (s). Masukkan variabel Prestasi (Y) pada kotak
Dependent, selanjutnya pada bagian method, pilih Enter, lalu klik Statistics.

6. Dilayar akan muncul tampilan windows Linear Refression Statistics. Aktifkan pilihan
dengan centang () Covariance matrix dan Collinearity Diagnostics. Abaikan yang lain
biar tetap default. Kemudian Klik Continue dan tekan OK.
Maka muncul outputnya sebagai berikut :
Saatnya untuk interprestasi Output. Seperti yang sudah saya jelaskan di bagian awal bahwa
dasar pengambilan keputusan dalam Multikolonieritas dapat dengan Melihat Nilai Tolerance
dan VIF.
Berdasarkan output di atas diketahui bahwa : Nilai Toerance variabel Motivasi (X1) dan Minat
(X2) yakni 0,380 lebih besar dari 0,10. Sementara itu, Nilai VIF variabel Motivasi (X1) dan Minat
(X2) yakni 2,634 lebih kecil dari 10,00. Sehingga dapat disimpulkan tidak terjadi
Multikolonieritas.
Sumber : http://www.spssindonesia.com/2014/02/uji-multikolonieritas-dengan-melihat.html

UJI AUTOKORELASI
Modified By Aldy Forester
Uji Autokorelasi adalah untuk melihat apakah terjadi korelasi antara suatu periode t dengan
periode sebelumnya (t -1). Secara sederhana adalah bahwa analisis regresi adalah untuk
melihat pengaruh antara variabel bebas terhadap variabel terikat, jadi tidak boleh ada korelasi
antara observasi dengan data observasi sebelumnya.
Sebagai contoh adalah pengaruh antara tingkat inflasi bulanan terhadap nilai tukar rupiah
terhadap dollar. Data tingkat inflasi pada bulan tertentu, katakanlah bulan Februari, akan
dipengaruhi oleh tingkat inflasi bulan Januari. Berarti terdapat gangguan autokorelasi pada
model tersebut. Contoh lain, pengeluaran rutin dalam suatu rumah tangga. Ketika pada bulan
Januari suatu keluarga mengeluarkan belanja bulanan yang relative tinggi, maka tanpa ada
pengaruh dari apapun, pengeluaran pada bulan Februari akan rendah.
Uji autokorelasi hanya dilakukan pada data time series (runtut waktu) dan tidak perlu dilakukan
pada data cross section seperti pada kuesioner di mana pengukuran semua variabel dilakukan
secara serempak pada saat yang bersamaan. Model regresi pada penelitian di Bursa Efek
Indonesia di mana periodenya lebih dari satu tahun biasanya memerlukan uji autokorelasi.
Beberapa uji statistik yang sering dipergunakan adalah uji DurbinWatson, uji dengan Run Test
dan jika data observasi di atas 100 data sebaiknya menggunakan uji Lagrange Multiplier. Run
test sebagai bagian dari statistik nonparametrik dapat digunakan untuk menguji apakah antar
residual terdapat korelasi yang tinggi atau tidak. Jika antar residual tidak terdapat hubungan
korelasi maka dikatakan bahwa residual adalah acak atau random. Run Test digunakan untuk
melihat apakah residual terjadi secara random atau tidak.
H0 : Residual Random (acak)
H1 : Residual Tidak Random
Uji run test akan memberikan kesimpulan yang lebih pasti jika terjadi masalah pada Durbin
Watson Test yaitu nilai d terletak antara dL dan dU atau diantara (4dU) dan (4dL) yang akan
menyebabkan tidak menghasilkan kesimpulan yang pasti atau pengujian tidak meyakinkan jika
menggunakan DW test. Seperti contoh dibawah ini.

Dengan T=27, K=5, dL = 1.08364, dU = 1.75274. artinya dL < d < dU = Tidak ada kesimpulan
yang pasti.
Mari kita mulai langkahlangkahnya,,, saya tidak menggunakan hasil diatas dalam tutorial ini,
karena saya ingin melanjutkan postingangpostingan sebelumnya tentang analisis regresi
berganda dengan spss, supaya satu studikasus yang digunakan dan dibahas secara runtun dan
lengkap. Silahkan lihat studi kasusnya disini.
1. Pada Data View SPSS, Pilih menu Analyze – Regression – Linear, pada kotak
Dependent, isikan variabel dependent (Jumlah Penduduk Miskin) dan pada kotak
Independent, isikan variabel X1, X2, (Jumlah Pengangguran, Angka Rata2 Lama
Sekolah)
2. Pilih metode Enter, kemudian klik Button Save
3. Berikan centang pada Unstandardized pada kolom Residuals, lalu klik Continue,
kemudian pilih OK.

4. Selanjutnya pada Data View SPSS, akan muncul kolom baru dengan nama kolom
RES_1, ini merupakan residual regresi.
5. Pilih menu Analyze > Nonparametric Test > Legacy Dialogs – Runs, kemudian
Pindahkan RES_1 ke kolom Test Variable List di sebelah kanan, centang pada
Median, lalu klik OK.
Sekarang Perhatikan output runs test di bawah ini, nilai yang dibandingkan adalah Asymp. Sig.
(2-tailed) yaitu 0,869.
Hasil run test menunjukkan bahwa nilai Asymp. Sig. (2tailed) > 0.05 yang berarti Hipotesis nol
diterima. Dengan demikian, data yang dipergunakan cukup random sehingga tidak terdapat
masalah autokorelasi pada data yang diuji.
Sumber : http://www.portal-statistik.com/2014/05/mendeteksi-autokorelasi-dengan-run-test.html

UJI VALIDITAS PRODUCT MOMENT
Modified By Aldy Forester
Setiap penelitian yang dilakukan dengan menggunakan metode angket perlu dilakukan uji
validitasnya. Uji validitas berguna untuk mengetahui kevalidan atau kesesuaian angket yang
peneliti gunakan untuk memperoleh data dari para responden. Uji Validitas Product Momen
Pearson Correlation menggunakan prinsip mengkorelasikan atau menghubungkan antara
masing‐masing skor item dengan skor total yang diperoleh dalam penelitian.
Setiap uji dalam statistic tentu mempuyai dasar dalam pengambilan keputusan sebagai acuan
untuk membuat kesimpulan, begitu pula Uji Validitas Product Momen Pearson Correlation,
dalam uji validitas ini, dasar pengambilan keputusannya adalah sebagai berikut :
1. Jika nilai rhitung lebih besar dari nilai rtabel, maka angket tersebut dinyatakan valid.
2. Jika nilai rhitung lebih kecil dari nilai rtabel, maka angket tersebut dinyatakan tidak
valid
Setelah mengetahui dasar pengambilan keputusan Uji Validitas Product Momen Pearson
Correlation, pertanyaan berikutnya adalah bagaima kemudian jika terdapat beberapa item soal
dalam angket yang tidak valid?
Jawabannya adalah : kalau angket tersebut valid tentunya tidak ada masalah, Namun jika tidak
bagaimana? Nah, perlu diperhatikan bahwa jika setelah dilakukan Validitas Product Momen
Pearson Correlation terdapat item soal yang tidak valid, maka ada beberapa pilihan yang perlu
dilakukan yakni, mengulang dan mengganti dengan soal yang lain, mengulang angket dan
dibagikan kepada terponden lagi tanpa harus diganti soalnya, atau tidak mengubah soal dan
tidak membagikan ulang angket kepada responden, namun angket yang tidak valid di drop atau
tidak ikut dihitung dalam uji berikutnya.
Menuju kebagian praktek, yakni cara melakukan uji validitas product momen dengan SPSS.
Contoh data yang akan diuji adalah data Partisipasi Siswa dalam Pemilihan Ketua OSIS.
Dengan total responden berjumlah 20 siswa atau N = 20 dan item soal berjumlah 7 buah. Uji
akan dilakukan dengan Program SPSS versi 21. Table datanya lihat dibawah ini.

Lakukan langkah‐langkah pengujiannya seperti urutan cara di bawah ini.
1. Persiapkan data angket yang ingin di uji dalam file doc, excel, dll (seperti contoh di atas).
2. Buka Program SPSS.
3. Klik Variable View, dibagian pojok kiri bawah.
4. Pada bagian Name tuliskan Item_1 ke bawah sampai Item_7 (sampai 7 karena item soal
saya berjumlah 7 buah) terakhir tulis Skor_Total. Pada Decimals ubah semua menjadi
angka 0, abaikan yang lainnnya.
5. Klik Data View (dibagian pojok kiri bawah) dan masukkan data skor angketnya, bisa
dilakukan dengan cara copy paste data angket yang sudah dipersiapkan tadi.

6. Selanjutnya Pilih menu Analyze, kemudian pilih sub menu Correlate, lalu pilih Bivariate
7. Kemudian muncul kotak baru, dari kotak dialog Bivariate Correlations, masukkan semua
variabel ke kotak Variables. Pada bagian Correlation Coefficients centang Pearson,
Pada bagian Test of Significance pilih Two‐tailed. Centang Flag significant
Corerrelations. Klik OK untuk mengakhiri Perintah.
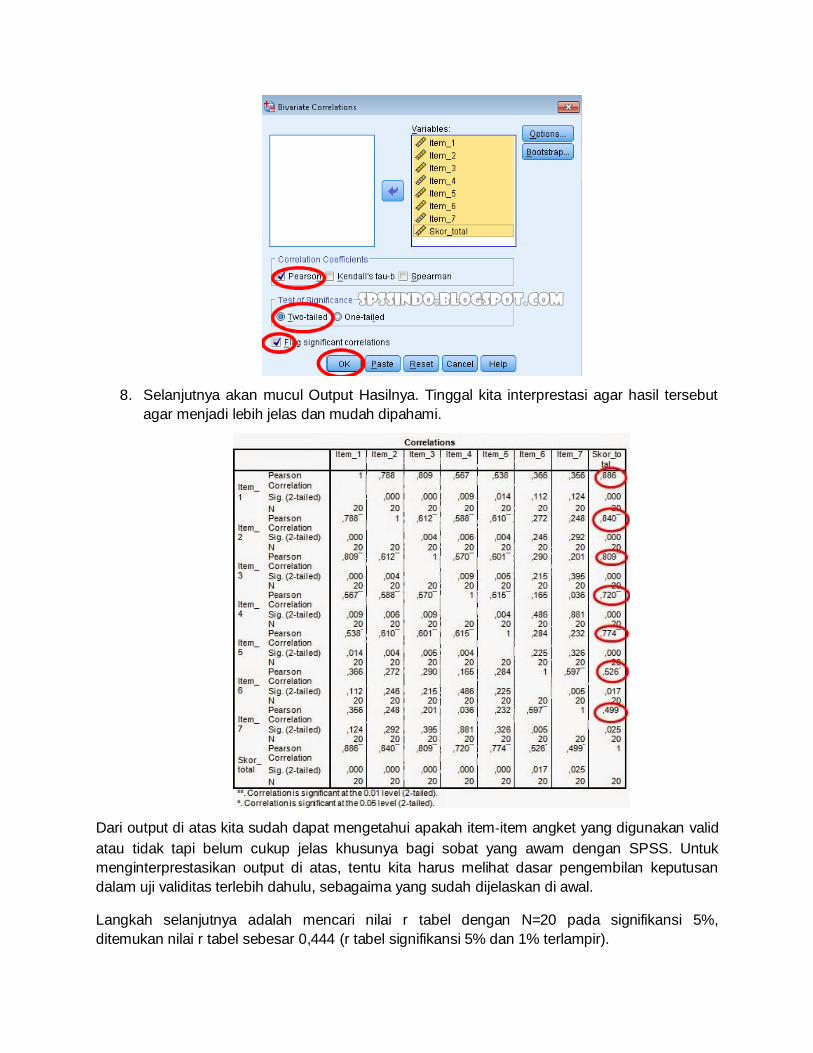
8. Selanjutnya akan mucul Output Hasilnya. Tinggal kita interprestasi agar hasil tersebut
agar menjadi lebih jelas dan mudah dipahami.
Dari output di atas kita sudah dapat mengetahui apakah item‐item angket yang digunakan valid
atau tidak tapi belum cukup jelas khusunya bagi sobat yang awam dengan SPSS. Untuk
menginterprestasikan output di atas, tentu kita harus melihat dasar pengembilan keputusan
dalam uji validitas terlebih dahulu, sebagaima yang sudah dijelaskan di awal.
Langkah selanjutnya adalah mencari nilai r tabel dengan N=20 pada signifikansi 5%,
ditemukan nilai r tabel sebesar 0,444 (r tabel signifikansi 5% dan 1% terlampir).

Angka r tabel kemudian kita bandingkan dengan nilai r hitung yang telah diketahui dari nilai
output (angka yang sayaberi lingkaran merah pada gambar output di atas). Dengan demikian,
diketahui bahwa semua nilai r hitung lebih besar dari nilai r tabel, yang artinya semua item
anget tersebut dinyatakan valid dan bisa dijadikan sebagai alat pengumpul data dalam
penelitian yang dilakukan. Untuk lebih jelasnya dapat melihat pada tabel rangkuman uji validitas
data Partisipasi Siswa dalam Pemilihan Ketua OSIS di bawah ini.
Sumber : http://www.spssindonesia.com/2014/01/uji-validitas-product-momen-spss.html

UJI RELIABILITAS ALPHA CRONBACH’S
Modified By Aldy Forester
Setelah melakukan Uji Validitas Product Momen dengan SPSS, selanjutnya yang harus
dilakukan agar angket yang digunakan benar‐benar dapat dipercaya sebagai alat pengumpul
data maka perlu di uji reliabilitas atau tingkat kepercayaannya pula.
Secara umum reliabilitas diartikan sebagai sesuatu hal yang dapat dipercaya atau keadaan
dapat dipercaya. Dalam statistik SPSS Uji Reliabilitas berfungsi untuk mengetahui tingkat
kekonsistensian angket yang digunakan oleh peneliti sehigga angket tersebut dapat
dihandalkan, walaupun penelitian dilakukan berulangkali dengan angket yang sama.
Salah satu cara melakukan uji reliabilitas instrumen adalah dengan Uji Reliabilitas Alpha
Cronbach’s dengan SPSS. Uji Reliabilitas dalam hal ini mengacu pada nilai Alpha yang
dihasilkan dalam output SPSS. Seperti halnya pada uji‐uji statistik lainnya hasil Uji Reliabilitas
Alpha Cronbach’s pun berpedoman pada dasar pengambilan keputusan yang telah ditentukan.
Dasar pengambilan keputusan dalam Uji Reliabilitas adalah jika nilai Alpha lebih besar dari r
tabel maka item‐item angket yang digunakan dinyatakan reliabel atau konsisten, sebaliknya jika
nilai Alpha lebih kecil dari r tabel maka item‐item angket yang digunakan dinyatakan
tidak reliabiel atau tidak konsisten.
Langkah‐langkah melakukan Uji Reliabilitas Alpha Cronbach’s dengan SPSS yang harus
dilakukan yaitu :
1. Persiapkan data yang akan di uji dalam format doc, excel, atau yang lainnya, dalam praktek
kali ini saya akan menguji reliabilitas Partisipasi Siswa dalam Pemilihan Ketua OSIS
dengan N = 20 dan item angket 7 buah. Lihat datanya di bawah ini.
2. Buka Program SPSS dan klik Variable View, dibagian pojok kiri bawah.
3. Pada bagian Name tuliskan Item_1 ke bawah sampai Item_7 (sampai 7 karena item angket
yang valid pada angket Partisipasi Siswa dalam Pemilihan Ketua OSIS berjumlah 7 buah).
P ada Decimals ubah semua menjadi angka 0, abaikan yang lainnnya.
4. Klik Data View (dibagian pojok kiri bawah) masukkan data angketnya (catatan : angket
yang ditulis hanya yang valid saja, yang sebelumnya telah dilakukan uji validitas, jika
sebelumnya ada item angket yang tidak valid, maka item angket tersebut tidak perlu
dilakukan uji reliabilitas), memasukkan data angket bisa dilakukan dengan cara copy paste
data angket yang sudah dipersiapkan tadi.
5. Selanjutnya, dari menu SPSS pilih Analyze, lalu klik Scale, kemudian klik Reliability
Analyze.
6. Nah, muncul kotak dialog baru kan dengan nama Reliability Analysis, masukkan semua
variabel ke kotak Items, kemudian pada bagian Model pilih Alpha
7. Langkah selanjunya adalah klik Statistics, pada Descriptives for, klik Scale if item
deleted, selanjutnya klik Continue. Abaikan pilihan yang lainnya.

8. Yang terakhir adalah klik OK untuk mengakhiri perintah, setelah itu akan muncul tampilan
outputnya selanjutnya tinggal kita interprestasikan saja.
Dari gambar output di atas, diketahui bahwa nilai Alpha sebesar 0,850, kemudian nilai ini kita
bandingkan dengan nilai r tabel dengan nilai N=20 dicari pada distribusi nilai r tabel signifikansi
5% (r tabel signifikansi 5% dan 1% terlampir) diperoleh nilai r tabel sebesar 0,444.
Kesimpulannya Alpha = 0,850 > r tabel = 0,444, artinya item‐item angket Partisipasi Siswa
dalam Pemilihan Ketua OSIS dapat dikatakan reliabel atau terpercaya sebagai alat pengumpul
data dalam penelitian.
Sumber : http://www.spssindonesia.com/2014/01/uji-reliabilitas-alpha-spss.html

ANALISIS REGRESI LINEAR BERGANDA (METODE STEPWISE)
Modified By Aldy Forester
Regresi linear ganda berguna untuk mencari pengaruh dua atau lebih variabel bebas (predictor)
atau untuk mencari hubungan fungsional dua variabel predictor atau lebih terhadap variabel
kriteriumnya. Rumus yang digunakan sama seperti pada regresi sederhana namun, disesuaikan
dengan jumlah variabel yang diteliti. Rumus persamaan regresinya adalah sebagai berikut:
Y = a+b1x1+b2x2....bn
Untuk memperjelas pemahaman kita tentang cara Uji Analisis Regresi Linear Ganda Dengan
SPSS, kita akan menggunakan contoh yaitu: “diduga bahwa besarnya nilai tergantung pada
besarnya Skor Tes Kecerdasan dan Frekuensi Membolos. Untuk keperluan tersebut, maka
dilakukan pengamatan terhadap 12 orang siswa dengan mencatat Frekuensi Membolos, Skor
Tes Kecerdasan dan Nilai Ujian, data dari variabel di atas adalah sebagai berikut:
Langkah-langkah Uji Analisis Regresi Linear Ganda Dengan SPSS:
1. Buka lembar kerja baru pada program SPSS.
2. Klik Variabel View pada SPSS Data editor.
3. Pada kolom Name, ketik Skor_Tes pada beris pertama, ketik Membolos pada
baris kedua dan ketik Nilai pada baris ketiga.
4. Pada kolom Decimals, ketik 0 untuk baris pertama, baris kedua dan baris
ketiga.
5. Pada kolom Label, ketik Skor Tes Kecerdasan untuk baris pertama, ketik
Frekuensi Membolos pada baris kedua, dan ketik Nilai Ujian pada baris ketiga.
6. Abaikan kolom yang lainnya.
7. Ketik Data View pada SPSS Data editor.
8. Ketik datanya seperti data di atas sesuai dengan variabelnya.
9. Dari menu SPSS, pilih menu Analyze > Regression > Linear maka akan muncul
kontak dialog seperti sebagai berikut:
10. Masukkan variabel Nilai Ujian ke kolom Dependent, dan masukkan variabel
Skor Tes Kecerdasan dan Frekuensi Membolos ke kolom Independent (s)
11. Pada Method kita pilih metode Stepwise
12. Klik Statistics klik pilihan Estimates, Model Fit dan Deskriptive, kemudian klik
Continue
13. Klik OK untuk mengakhiri perintah.
Maka akan muncul output sebagai berikut:
Penjelasan output pertama (Descriptive Statistics)
Pada bagian ini merupakan tabel yang menyajikan deskriptif data masing-masing variabel yang
meliputi Mean (ratarata), Std. Deviation (standar deviasi dan N=jumlah data).
Penjelasan output bagian kedua (Corelation)
Pada bagian ini merupakan matrik korelasi antara variabel Skor Tes Kecerdasan
dengan Nilai Ujian diperoleh r = 0,860 dengan probabilitas = 0,000 < 0,05, maka
Ho ditolak, yang berarti bahwa ada hubungan/korelasi yang signifikan antara
Skor Tes Kecerdasan dengan Nilai Ujian.
Variabel Frekuensi Membolos dengan nilai ujian r = -0,848, tanda negative menggambarkan
hubungan yang berlawanan yang artinya semakin sering membolos, maka akan semakin kecil
nilai yang diperoleh.
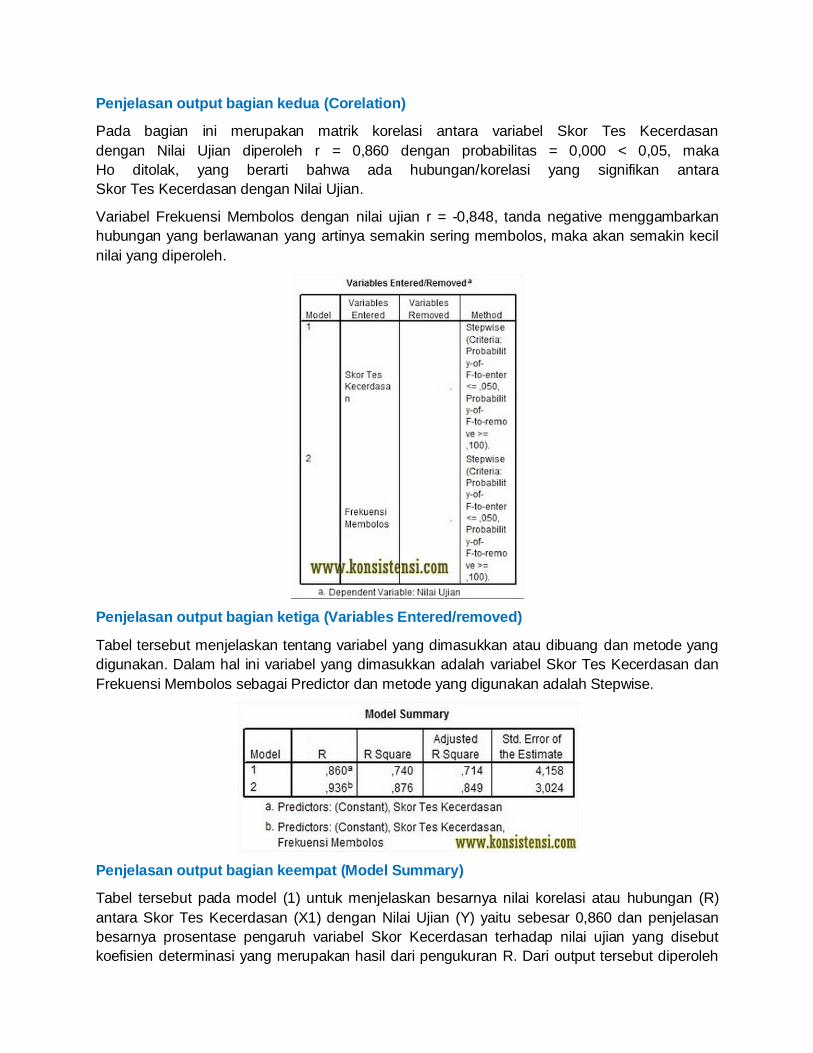
Penjelasan output bagian ketiga (Variables Entered/removed)
Tabel tersebut menjelaskan tentang variabel yang dimasukkan atau dibuang dan metode yang
digunakan. Dalam hal ini variabel yang dimasukkan adalah variabel Skor Tes Kecerdasan dan
Frekuensi Membolos sebagai Predictor dan metode yang digunakan adalah Stepwise.
Penjelasan output bagian keempat (Model Summary)
Tabel tersebut pada model (1) untuk menjelaskan besarnya nilai korelasi atau hubungan (R)
antara Skor Tes Kecerdasan (X1) dengan Nilai Ujian (Y) yaitu sebesar 0,860 dan penjelasan
besarnya prosentase pengaruh variabel Skor Kecerdasan terhadap nilai ujian yang disebut
koefisien determinasi yang merupakan hasil dari pengukuran R. Dari output tersebut diperoleh
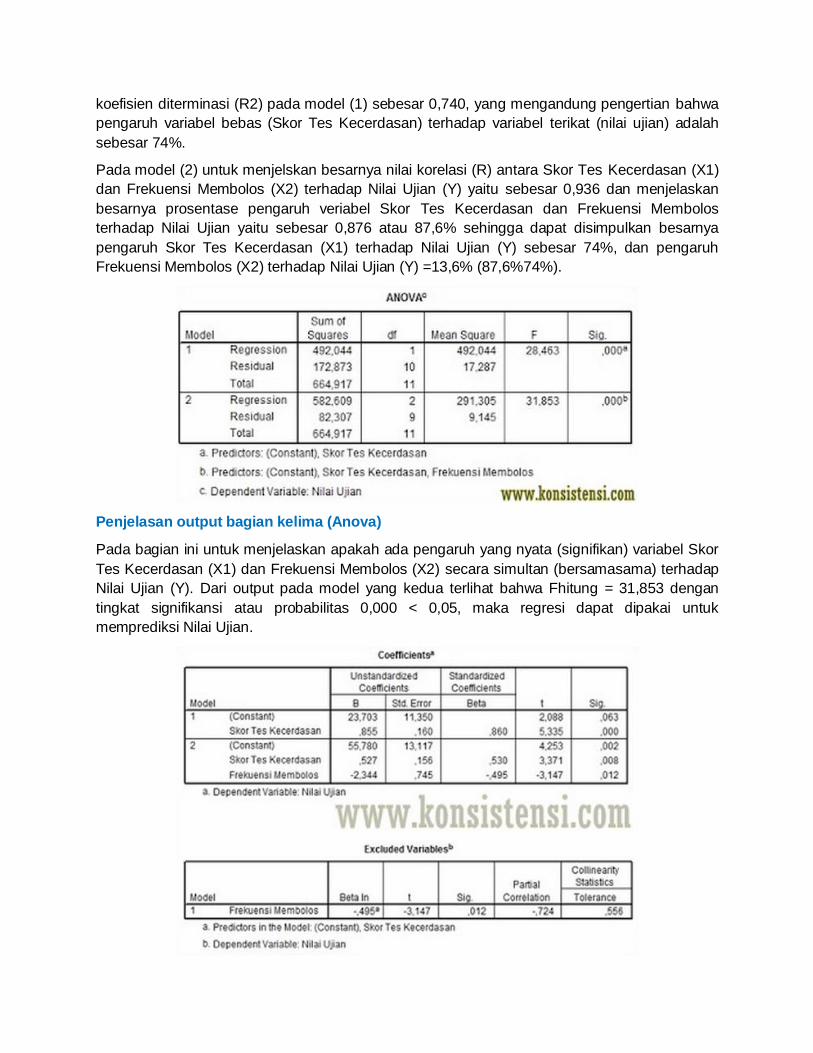
koefisien diterminasi (R2) pada model (1) sebesar 0,740, yang mengandung pengertian bahwa
pengaruh variabel bebas (Skor Tes Kecerdasan) terhadap variabel terikat (nilai ujian) adalah
sebesar 74%.
Pada model (2) untuk menjelskan besarnya nilai korelasi (R) antara Skor Tes Kecerdasan (X1)
dan Frekuensi Membolos (X2) terhadap Nilai Ujian (Y) yaitu sebesar 0,936 dan menjelaskan
besarnya prosentase pengaruh veriabel Skor Tes Kecerdasan dan Frekuensi Membolos
terhadap Nilai Ujian yaitu sebesar 0,876 atau 87,6% sehingga dapat disimpulkan besarnya
pengaruh Skor Tes Kecerdasan (X1) terhadap Nilai Ujian (Y) sebesar 74%, dan pengaruh
Frekuensi Membolos (X2) terhadap Nilai Ujian (Y) =13,6% (87,6%74%).
Penjelasan output bagian kelima (Anova)
Pada bagian ini untuk menjelaskan apakah ada pengaruh yang nyata (signifikan) variabel Skor
Tes Kecerdasan (X1) dan Frekuensi Membolos (X2) secara simultan (bersamasama) terhadap
Nilai Ujian (Y). Dari output pada model yang kedua terlihat bahwa Fhitung = 31,853 dengan
tingkat signifikansi atau probabilitas 0,000 < 0,05, maka regresi dapat dipakai untuk
memprediksi Nilai Ujian.

Penjelasan output bagian keenam (Coefficients)
Pada tabel Coefficients, pada kolom B pada Constanta (a) adalah 55,780, Skor Tes
Kecerdasan (b1) adalah 0,527 dan Frekuensi Membolos (b2) adalah 2,344. Berdasarkan data
di atas, maka dapat dikatakan bahwa: Konstanta sebesar 55,780, koefisien regresi X1 sebesar
0,527, dan koefisien regresi X2 sebesar 2,233.
Kesimpulan:
Skor Tes Kecerdasan nilai thitung = 3,371 dengan probabilitas = 0,008 < 0,5, artinya ada
pengaruh yang signifikan. Untuk variabel Frekusnsi Membolos nilai Thitung = 3,147 dengan
probabilitas = 0,012 < 0,05 yang berarti ada pengaruh yang signifikan.
Sumber : http://www.konsistensi.com/2013/05/uji-analisis-regresi-linear-ganda.html

ANALISIS REGRESI LINEAR BERGANDA (METODE ENTER)
Modified By Aldy Forester
Analisis Regresi adalah suatu cara atau teknik untuk mencari hubungan antara variabel satu
dengan variabel lain yang dinyatakan dalam bentuk persamaan matematik dalam hubungan
yang fungsional. Dalam pengertian lain, analisis regresi ingin mencari hubungan dari dua
variabel atau lebih dengan mana variabel yang satu tergantung pada variabel yang lain.
Secara umum, dapat dinyatakan pula bahwa apabila ingin mengetahui pengaruh satu variabel
X terhadap satu variabel Y maka digunakan analisis regresi sederhana, dan apabila ingin
megetahui pengaruh dua variabel X atau lebih terhadap variabel Y digunakan analisis regresi
ganda (multiples). Persamaan Analisis Regresi Multiples berdasarkan pada rumus :
Theoremanya : Y = a+b1x1+b2x2....bn
Setelah mengetahui teori dasar mengenai Analisis Regresi Multiples, sekarang kita masuk ke
bagian Cara Melakukan Analisis Regresi Multipes dengan SPSS versi 21. Sebagai contoh, ingin
mengetahui pengaruh variabel Motivasi (X1) dan variabel Minat (X2), terhadap variabel Prestasi
(Y), data penelitian ini mempuyai sampel berjumlah 12 siswa. Adapun data lengkapnya lihat
pada gambar di bawah ini.
Langkah‐Langkah pada SPSS :
1. Buka program SPSS, klik Variable View, Selanjutnya, pada bagian Name tulis saja X1, X2
dan Y, pada Decimals ubah semua menjadi angka 0, pada bagian Label tuliskan Motivasi,
Minat dan Prestasi.

2. Setelah itu, klik Data View, dan masukkan data Motivasi (X1), Minat (X2) dan Prestasi (Y)
yang sudah dipersiapkan tadi.
3. Selanjutnya, dari menu utama SPSS, Pilih Analyze > Regression > Linear
4. Muncul kotak dialog dengan nama Linear Regression, masukkan variabel Motivasi (X1),
Minat (X2) ke kotak Independent (s), masukkan variabel Prestasi (Y) pada kotak
Dependent, pada Method pilih Enter, selanjutnya klik Statistics
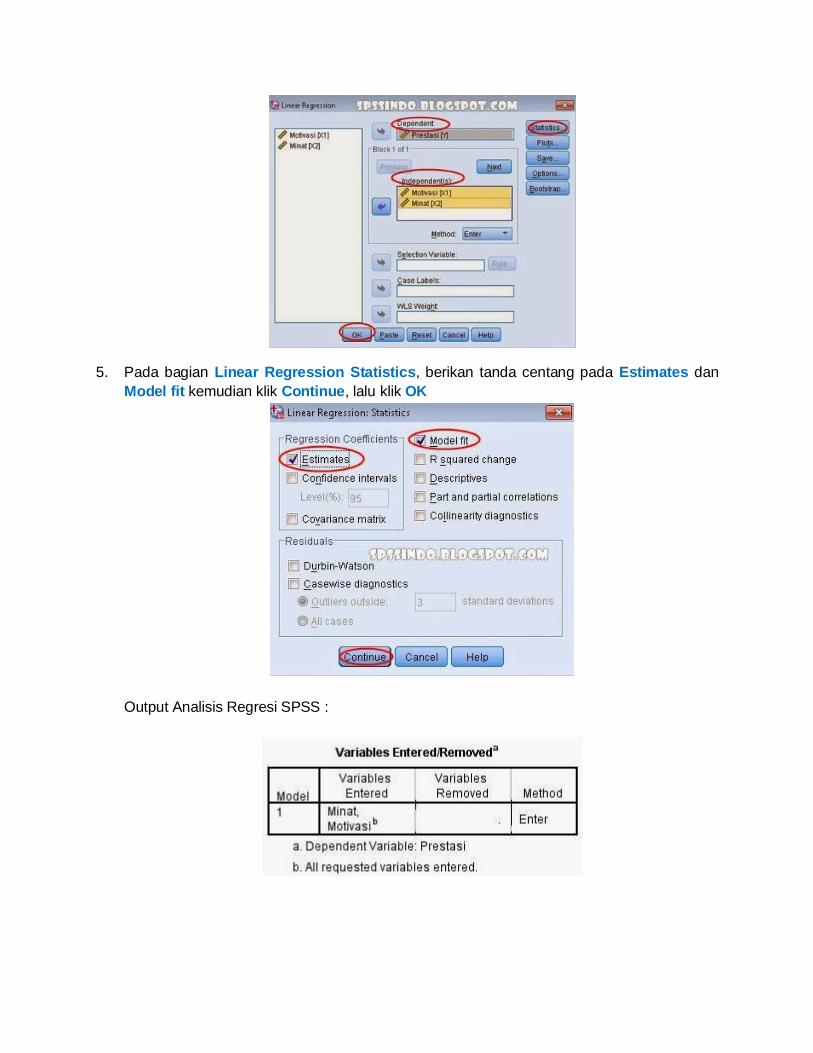
5. Pada bagian Linear Regression Statistics, berikan tanda centang pada Estimates dan
Model fit kemudian klik Continue, lalu klik OK
Output Analisis Regresi SPSS :
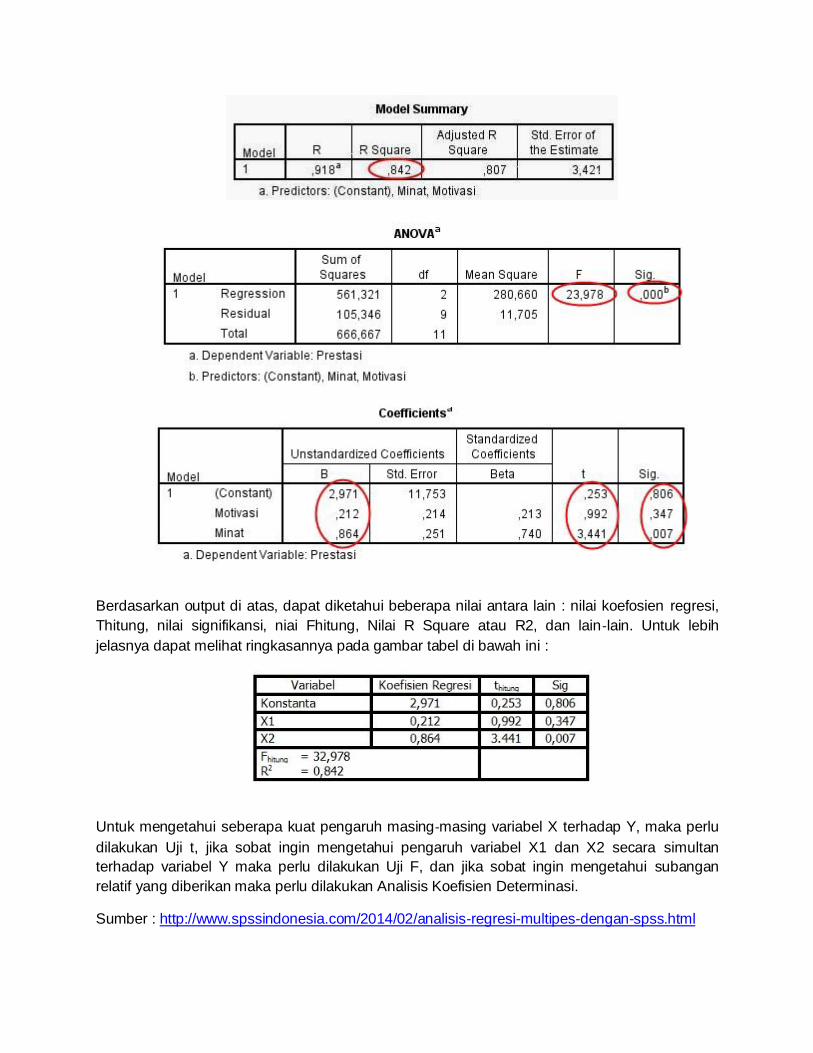
Berdasarkan output di atas, dapat diketahui beberapa nilai antara lain : nilai koefosien regresi,
Thitung, nilai signifikansi, niai Fhitung, Nilai R Square atau R2, dan lain‐lain. Untuk lebih
jelasnya dapat melihat ringkasannya pada gambar tabel di bawah ini :
Untuk mengetahui seberapa kuat pengaruh masing‐masing variabel X terhadap Y, maka perlu
dilakukan Uji t, jika sobat ingin mengetahui pengaruh variabel X1 dan X2 secara simultan
terhadap variabel Y maka perlu dilakukan Uji F, dan jika sobat ingin mengetahui subangan
relatif yang diberikan maka perlu dilakukan Analisis Koefisien Determinasi.
Sumber : http://www.spssindonesia.com/2014/02/analisis-regresi-multipes-dengan-spss.html

Titik Presentase Disitribusi F Probabilita = 0,05
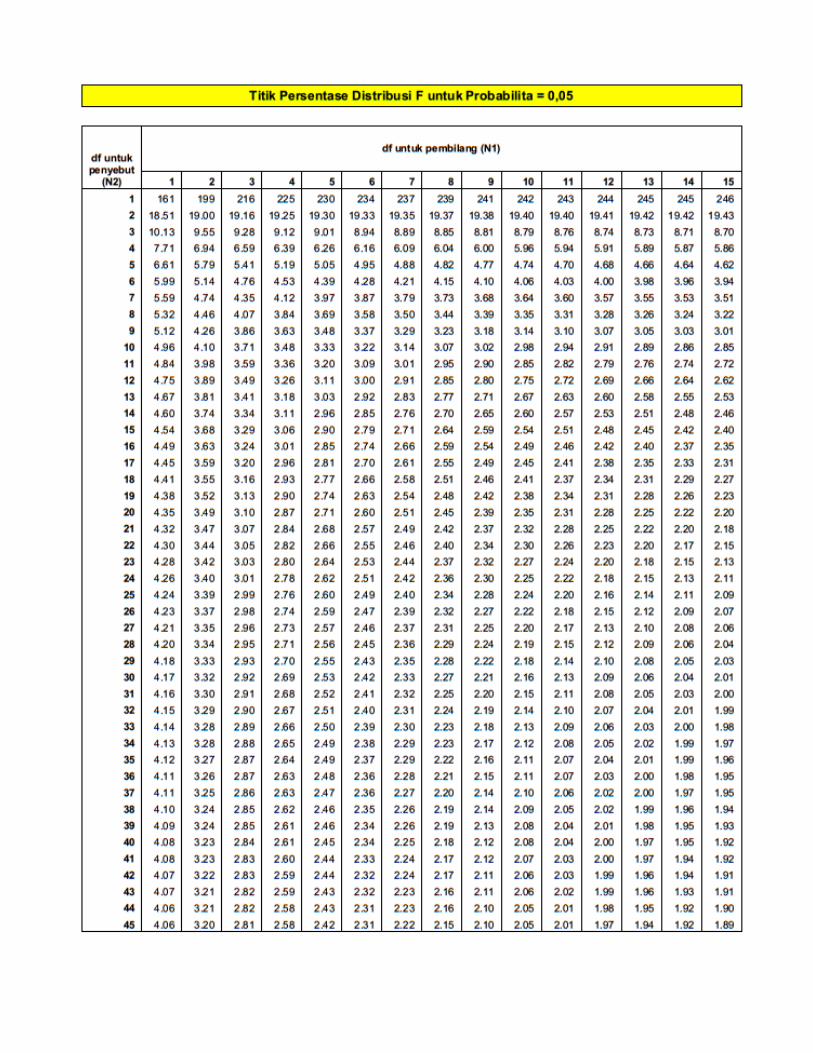
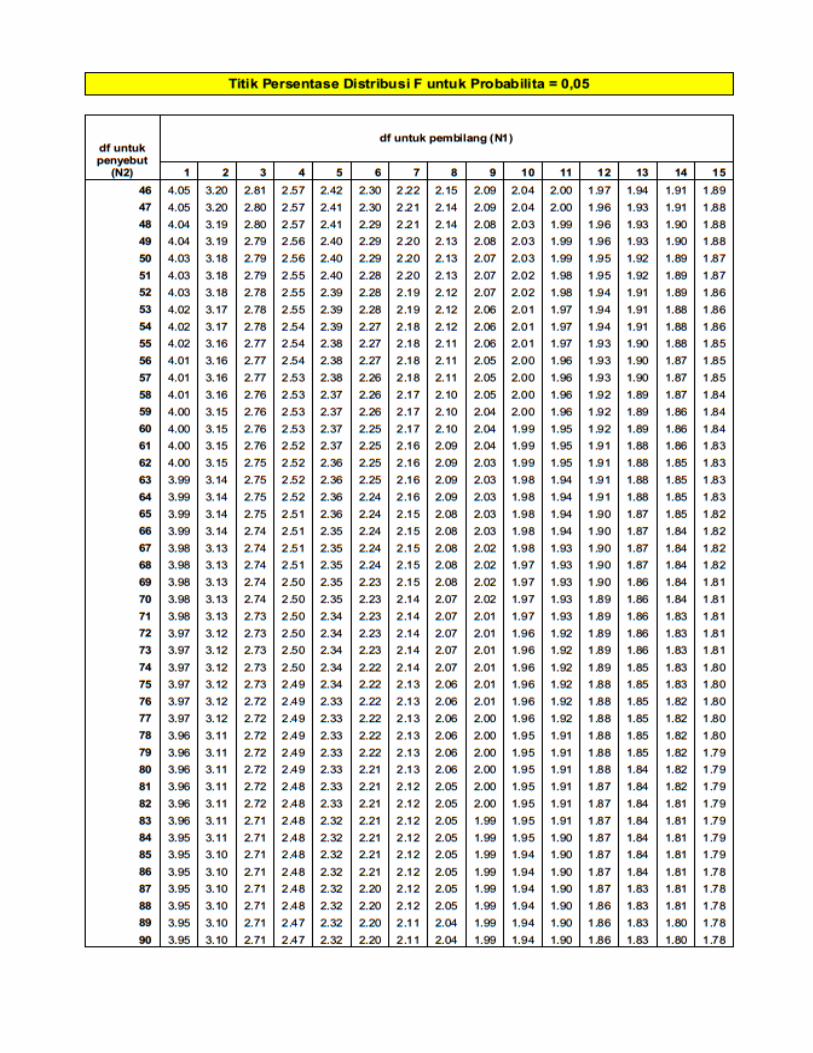
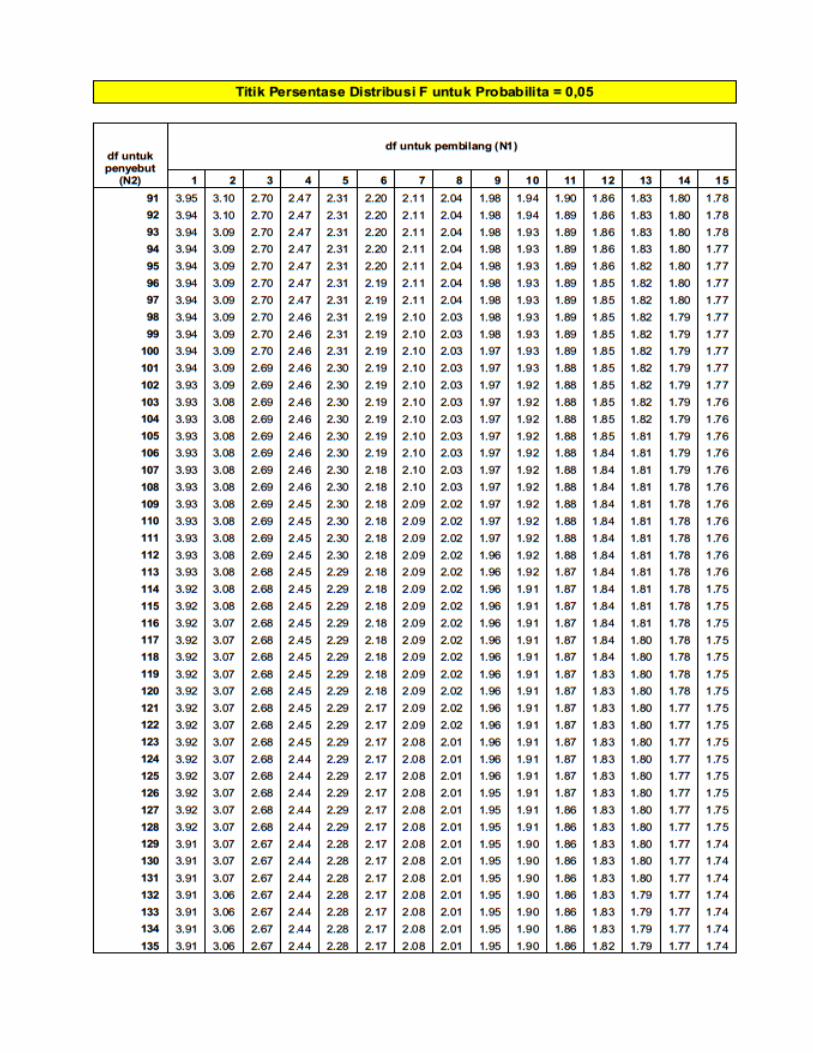

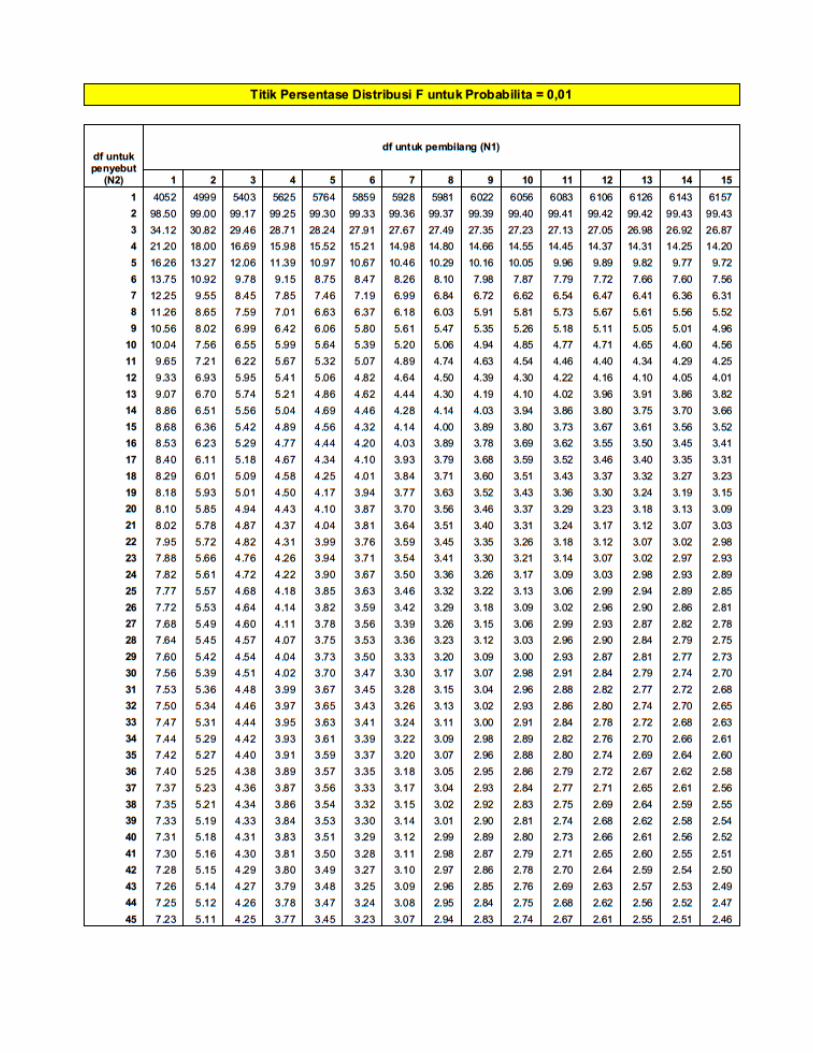
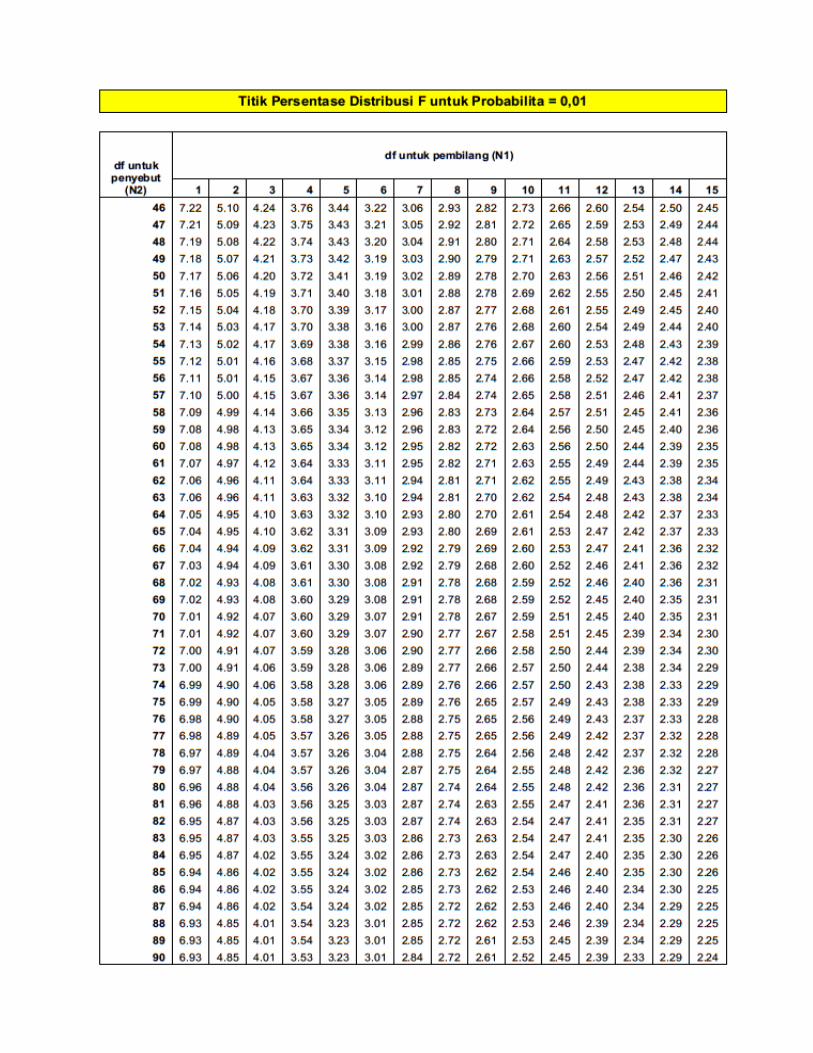
Titik Presentase Disitribusi F Probabilita = 0,01

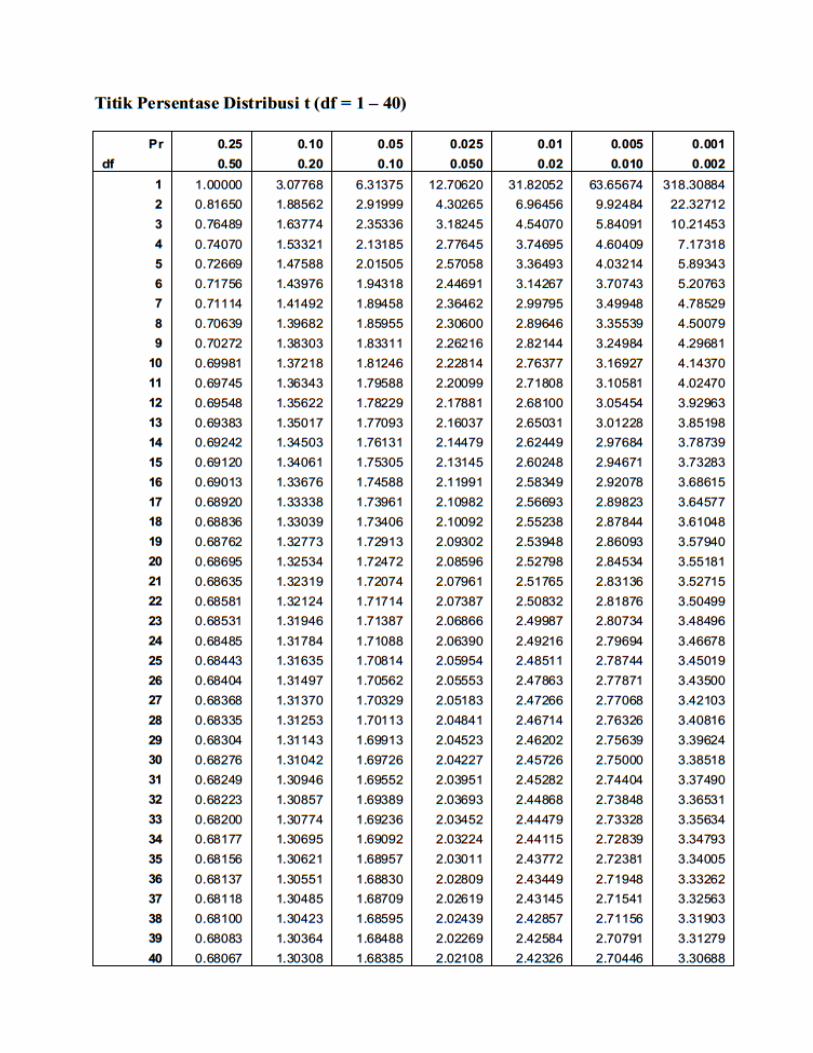
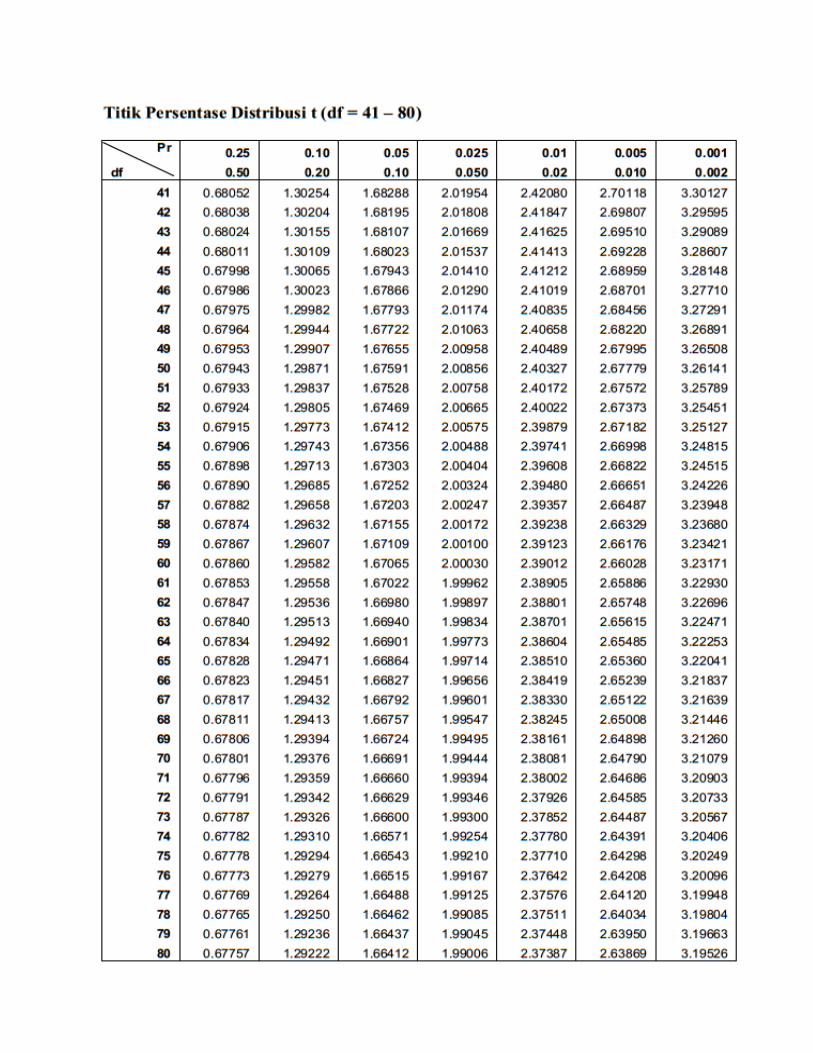
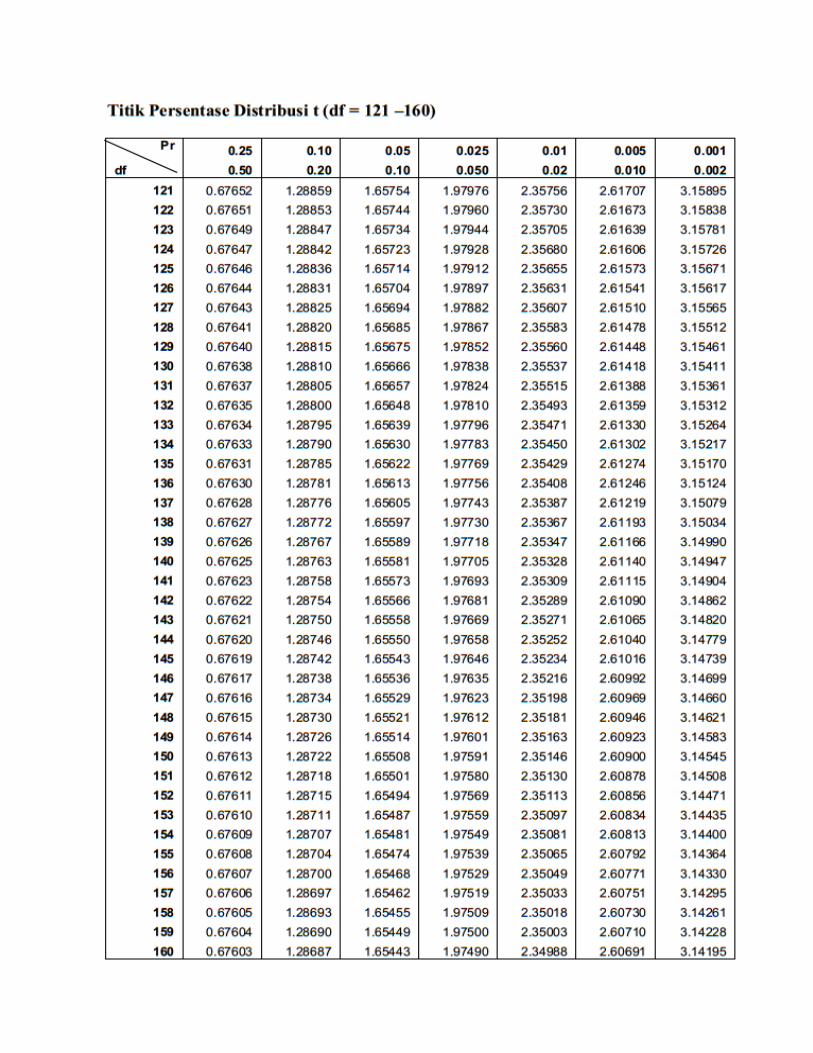
Titik Presentase Disitribusi t df = 1 - 160

Tabel R (Korelasi Linear Sederhana) df = 1 - 200
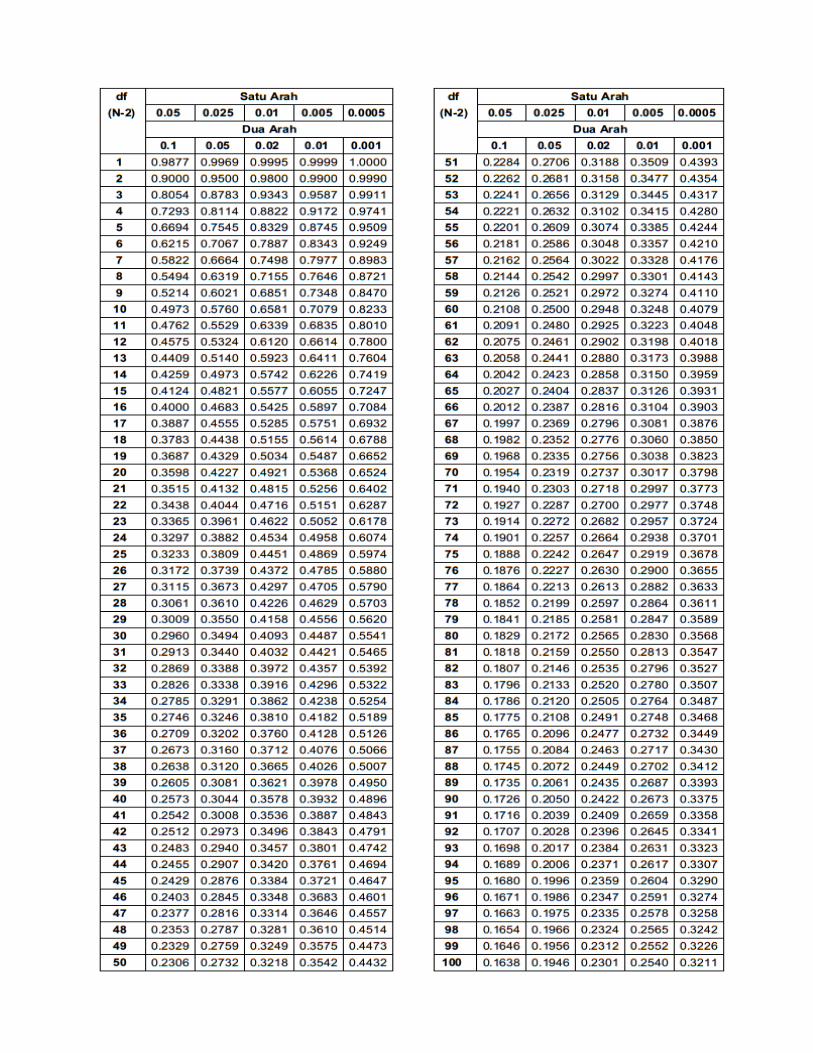
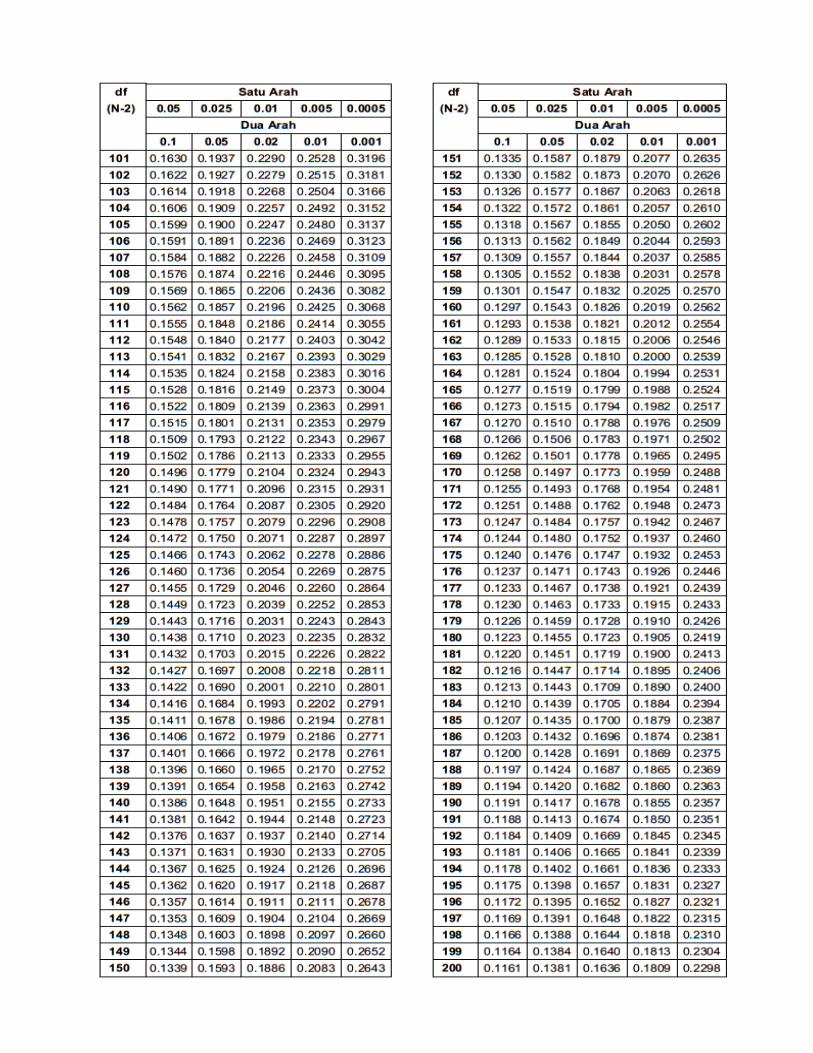

Tabel Nilai Kritis Uji Kolmogorov-Smirnov
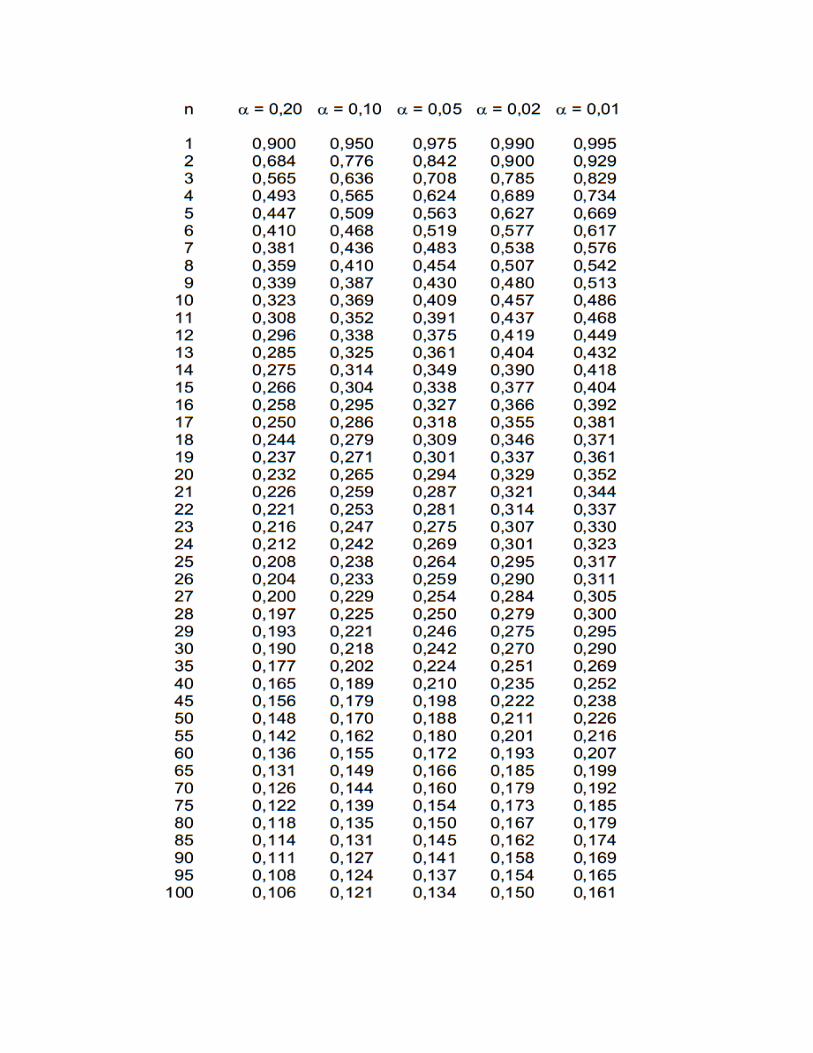

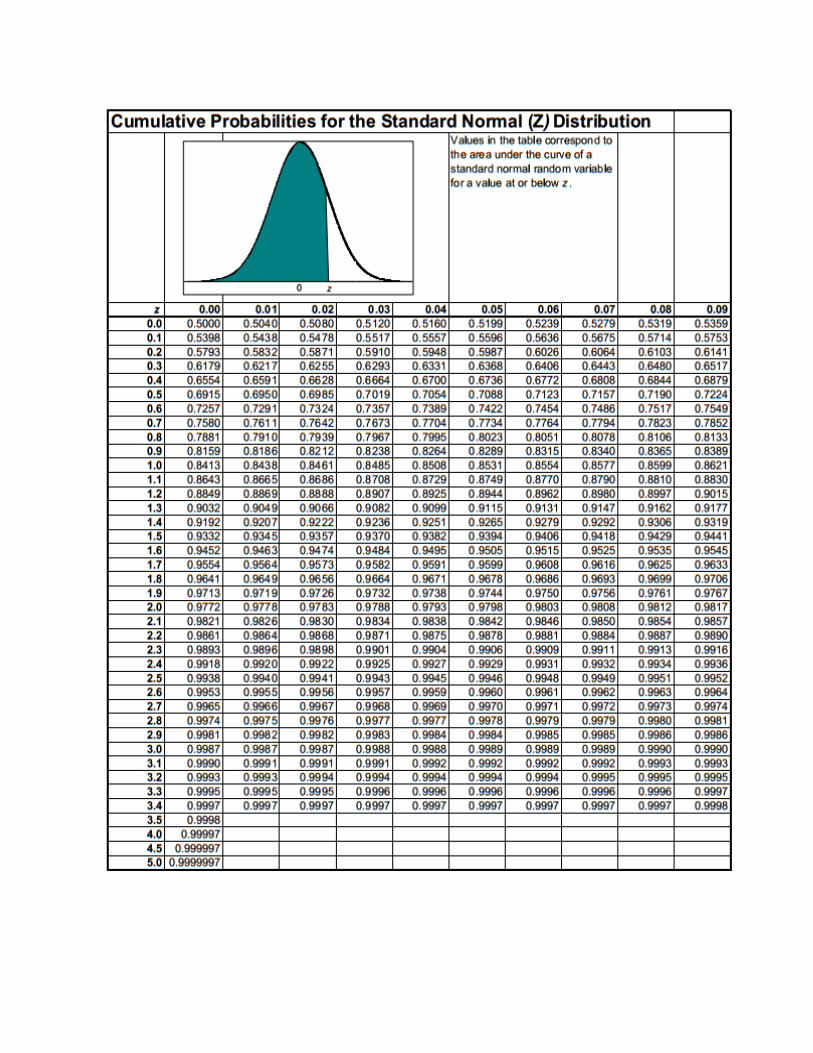
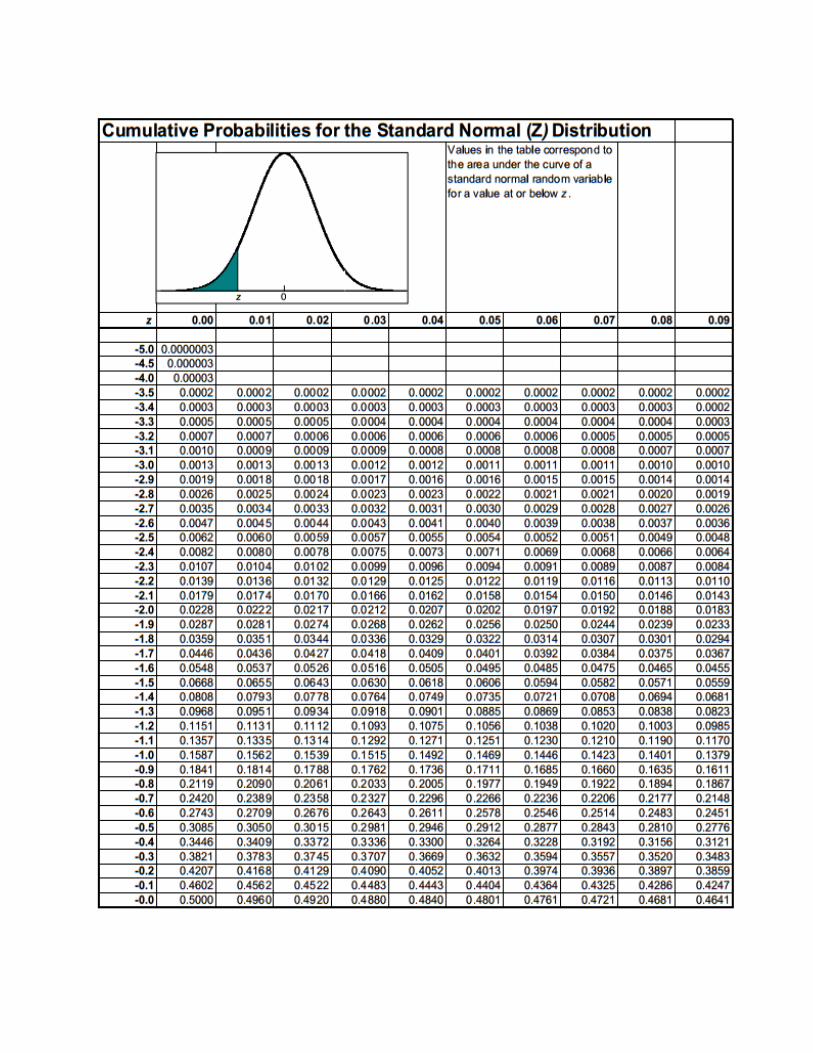
Tabel Distribusi Z Normal Positive & Negative